谷歌搜索的灵魂!BERT模型的崛起与荣耀( 二 )
在BERT面世之前 , NLP大厦头顶上有两片乌云:标记数据集不足和结果的低准确率 。
前者 , BERT在无标记数据集中用无监督学习解决;后者 , BERT通过加深Transformer层数和双向编码的方法精进 。
在出生时就带着横扫各大赛事的“战绩” , 两年的实战更历经无数风雨 , 现如今的BERT不仅在学界具有里程碑意义 , 在实际应用这片广阔天地中更是大有作为 。
二、两年不止步 , BERT的进阶史要在网页搜索届呼风唤雨 , 谷歌的真本事当然不止BERT一个 , 用于搜索引擎优化的Panda、Penguin、Payday , 打击垃圾邮件的Pigeon以及名声在外的网页排名算法Pagerank……每一块小模组都各司其职 , 组成了谷歌搜索的“最强大脑” 。
 文章插图
文章插图
BERT是在一岁时 , 也就是2019年10月15日 , 正式加入谷歌搜索的算法大脑 , 承担在美国境内的10%英文查询中 。
“深网络”、“双通路”的BERT不仅能“猜心” , 还能识错 。
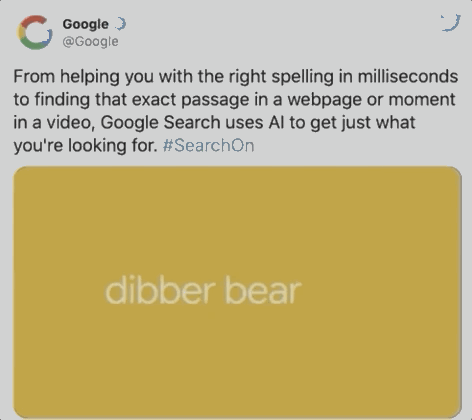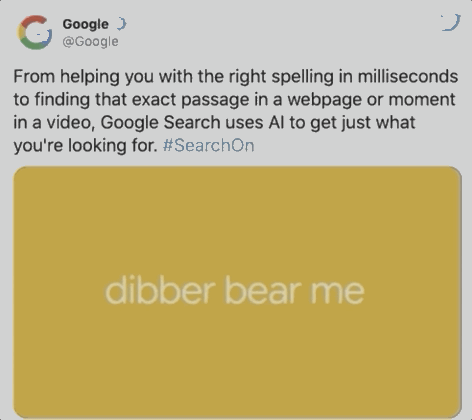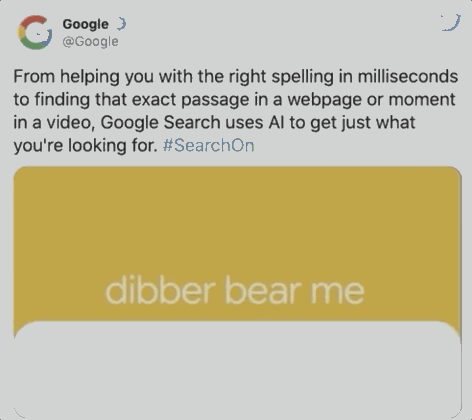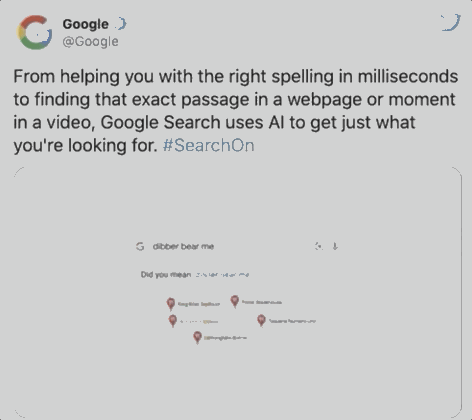
据谷歌统计 , 在每十次搜索中 , 就会出现一个拼写错误 , 如下图用户想搜索dinner , 却误输成dibber , 但BERT可以绕过这个错误 , 直接识别出用户意图 , 提供餐馆位置 。
 文章插图
文章插图
两个月后 , BERT开始承担70多种语言的搜索任务 。
一年后 , BERT在谷歌搜索中使用比例近乎100% , 凭借出色的理解能力 , 替代上一代查询工具RankBrain , 成为搜索大脑的王牌 。
在这“高分高能”的实绩背后 , 是BERT模型一直的默默进阶 。
2019年12月 , 通过更加有效地分配模型容量、简化Transformer隐藏层中的参数和冗余度检查 , BERT在性能提升的同时减少计算量 , 升级为更为轻量级ALBERT 。
2020年3月 , 受生成对抗网络(GAN)的启发 , BERT改进了预训练方式 , 减少了模型训练的时间 , 从而可以在更少的计算量内达到相同的文本识别效果 , 衍生出了ELECTRA模型 。
2020年8月 , BERT内引入了多语言嵌入模型 , 实现不同语言间互译 , 让用户可以在更大范围内搜索有效信息 。
2020年10月 , BERT着眼于减少模型本身的“偏见” , 利用模型评估指标来调整预训练模型中的参数 , 减少搜索时可能出现的性别种族歧视 。
从10%到100% , 带着满分出生的BERT并没有固步自封 , 而是不断地顺应时代的需求 , 一次又一次地自我更新 , 用更少的训练时间、更小的计算量达到更为优越的性能 。
今年十月 , 谷歌公布了BERT在搜索领域的表现 , 除了扩大应用范围和可应用的语言外 , BERT将谷歌在学术检索上的准确率提高了7% 。
谷歌也表示 , 会在未来利用BERT模型继续精进搜索算法 , 扩大搜索的范围 , 提高搜索的精度 。
三、BERT开球 , 百家争鸣BERT的贡献远不止是提升谷歌搜索性能或者获得“机器超过人类”的名号 , 而是作为一个泛化性极强的通用模型 , 为今后NLP届开辟了一条光明的研究赛道 。
 文章插图
文章插图
图源网络
以BERT为分界线 , NLP领域可以分为动态表征模型(Dynamic Representation)时代和深度动态表征模型(Deep Dynamic Representation)时代 , 在前一个时代 , 标注数据集的不足和单向编码器限制了模型的可拓展性;而在后一个时代 , 基于BERT发展出来的方法 , “支棱”起了NLP届半壁江山 。
改进BERT的方法千千万 , 其中大概可以分为两个方向:一是纵向 , 通过改进Transformer层的结构或者调整参数 , 得到更加轻量级的模型 , 例如之前提及过的ALBERT模型;二是纵向 , 通过在BERT模型中延伸其他算法模型 , 拓展BERT模型的功能 , 如受GAN影响诞生的ELECTRA模型 。
- 谷歌“跨年夜”Doodle带大家一起倒计时
- 谷歌推出新版Pixel 4a 5G:骁龙765G芯/卖3200元
- FTC委员称苹果、谷歌是移动游戏行业的“看门人”
- 员工|美国科技大公司中罕见成立工会,谷歌:会直接和员工谈
- 谷歌修复Pixel 5系统音量问题 快门音效不再吵
- 谷歌发布一月安全补丁 修复Pixel音频、应用重启等问题
- Apple Fitness+播放列表现可在Apple Music搜索上找到
- 为规避隐私标签不再更新ios应用?谷歌:或将本周更新
- 谷歌或于本周推出带有隐私标签的iOS App更新
- 谷歌回应质疑:首批带有隐私标签的iOS应用会在本周更新