谷歌搜索的灵魂!BERT模型的崛起与荣耀( 三 )
在BERT逐渐发挥影响力、实现应用落地的同时 , NLP届的新秀也轮番亮相 。
2019年出现的XLNet和2020年出现的GPT-3就是杀出重围的两员大将 。
XLNet , 在BERT的基础上 , 加入了自回归的预训练方法 , 得到一个既擅长语义理解也擅长语义生成的模型 , 补齐了BERT模型在长文阅读、以及文字生成方面的短板 。
而GPT-3更是来势汹汹 , 作为OpenAI旗下第三代深度语言学习模型 , 它自带1705亿个参数 , 是前一代模型GPT-2的100倍 , 经过5000亿个单词的预训练 , 在无微调的情况下 , 取得多个NLP基准测试上的最高分数 。
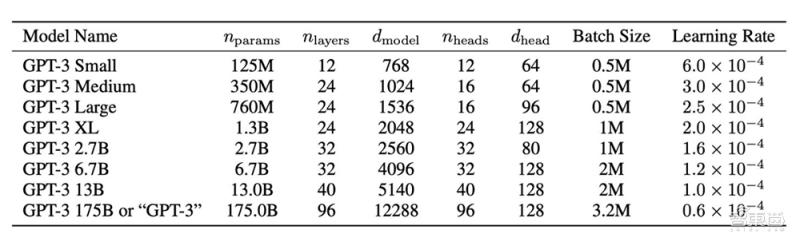 文章插图
文章插图
与此同时 , GPT-3也解决了BERT模型存在的两个问题:对标注数据的依赖 , 以及对训练数据集的过拟合 , 旨在成为更通用的NLP模型 。
基于更大的数据集和更多的参数 , GPT-3不仅能搜索网页 , 还能答题、聊天、写小说、写曲谱 , 甚至还能自动编程 。
在目前的调试阶段 , GPT-3也暴露出了包括仇恨言论、错误信息等许多问题 , 所以纵使顶着NLP界最强后浪的名号 , 它目前暂时还无法像前辈BERT一样 , 落地应用 , 为人类带来价值 。
结语:NLP新时代 , BERT不缺席自然语言处理(NLP)领域有很多细分方向:文本分类、机器翻译、阅读理解、机器人聊天……每一个子题都对应着人工智能在现实生活中的实际应用:网页检索、自动推荐、智能客服……
如何让人工智能真正走入我们的生活 , 第一个要解决的问题就是如何让机器真正地理解我们想要什么 。
BERT让我们迈出了一大步 , 基于自监督学习处理无标记数据 , 再通过双向编码理解文义 , BERT打破了之前训练数据需要标记的“魔咒” , 充分利用了大量无标记文本 , 是NLP届里程碑式的革新 。
从诞生、进阶到衍生出一系列语言模型 , 已经两岁的BERT用时间证明了自己的巨大潜力 , 或许在未来 , 它将融合进新的应用 , 为我们带来意想不到的AI革命 。
【谷歌搜索的灵魂!BERT模型的崛起与荣耀】参考资料:谷歌AI blog、Rock Content、searchengineland
 文章插图
文章插图
- 谷歌“跨年夜”Doodle带大家一起倒计时
- 谷歌推出新版Pixel 4a 5G:骁龙765G芯/卖3200元
- FTC委员称苹果、谷歌是移动游戏行业的“看门人”
- 员工|美国科技大公司中罕见成立工会,谷歌:会直接和员工谈
- 谷歌修复Pixel 5系统音量问题 快门音效不再吵
- 谷歌发布一月安全补丁 修复Pixel音频、应用重启等问题
- Apple Fitness+播放列表现可在Apple Music搜索上找到
- 为规避隐私标签不再更新ios应用?谷歌:或将本周更新
- 谷歌或于本周推出带有隐私标签的iOS App更新
- 谷歌回应质疑:首批带有隐私标签的iOS应用会在本周更新