文章插图
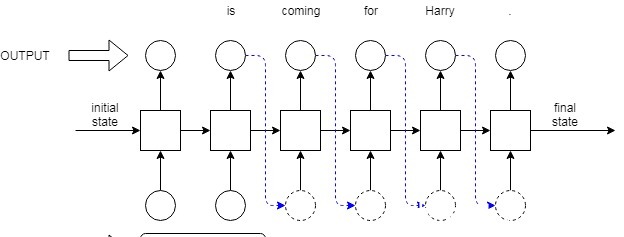
def inference(model,input_text,device,top_k=5,length = 100):output = ''model.eval()tokens = config.tokenizer(input_text)h,c = model.zero_state(1)h = h.to(device)c = c.to(device)for t in tokens:output = output+t+' 'pred,(h,c) = model(torch.tensor(w2i[t.lower()]).view(1,-1).to(device),(h,c))#print(pred.shape)for i in range(length):_,top_ix = torch.topk(pred[0],k = top_k)choices = top_ix[0].tolist()choice = np.random.choice(choices)out = i2w[choice]output = output + out + ' 'pred,(h,c) = model(torch.tensor(choice,dtype=torch.long).view(1,-1).to(device),(h,c))return output# ============================================================================================================device = 'cpu'mod = LSTMModel(emb_dim=config.emb_dim,hid_dim=config.hidden_dim,vocab_size=vocab_size,num_layers=3).to(device)mod.load_state_dict(torch.load(config.model_path))print('AI generated Anime synopsis:')inference(model = mod, input_text = 'In the ', top_k = 30, length = 100, device = device)在上面的例子中,我给出的最大长度为100,输入文本为“In the”,这就是我们得到的输出In the days attempt it 's . although it has , however ! what they believe that humans of these problems . it seems and if will really make anything . as she must never overcome allowances with jousuke s , in order her home at him without it all in the world : in the hospital she makes him from himself by demons and carnage . a member and an idol team the power for to any means but the two come into its world for what if this remains was to wait in and is n't going ! on an这在语法上似乎是正确的,但却毫无意义。LSTM虽然更善于捕捉长期依赖比基本RNN但他们只能看到几步(字)或向前迈了几步,如果我们使用双向RNNs捕获文本的上下文因此生成很长的句子时,我们看到他们毫无意义。GPT2方式一点点的理论Transformers在捕获所提供的文本片段的上下文方面做得更好。他们只使用注意力层(不使用RNN),这让他们更好地理解文本的上下文,因为他们可以看到尽可能多的时间步回(取决于注意力)。注意力有不同的类型,但GPT2所使用的注意力,是语言建模中最好的模型之一,被称为隐藏的自我注意。GPT2没有同时使用transformer 编码器和解码器堆栈,而是使用了一个高栈的transformer 解码器。根据堆叠的解码器数量,GPT2转换器有4种变体。
- 卡卡西|雷切并不适合暗杀,为什么暗部的卡卡西一直坚持使用原因很简单
- 奎因|海贼王1034话:山治进化为魔神,奎因使用杰尔马的战斗能力
- 焰云|海贼王1034话:山治进化为魔神,奎因使用杰尔马的战斗能力
- 小夫|哆啦A梦的道具中,最邪恶的几个道具,不敢轻易使用
- 村民们|《一人之下》第四季陈朵是好还是坏?张楚岚使用神明灵布局在第几集?
- 路飞|海贼王里索隆使用过6次狮子歌歌,只输给过熊,现在已能秒超新星
- 模式|佐助拥有五种战斗模式,咒印模式最弱,最强模式需和鸣人配合使用
- 四代|带土使用轮回天生时,身体被黑绝侵蚀,四代卡卡西为何无动于衷?
- 路飞|索隆霸王色深度解析,鱼人岛就已经觉醒,和路飞的还有所不同!
- 虎杖悠仁|贴吧大神自制《咒术回战》,虎杖悠仁使用领域展开,禅院真希YYDS