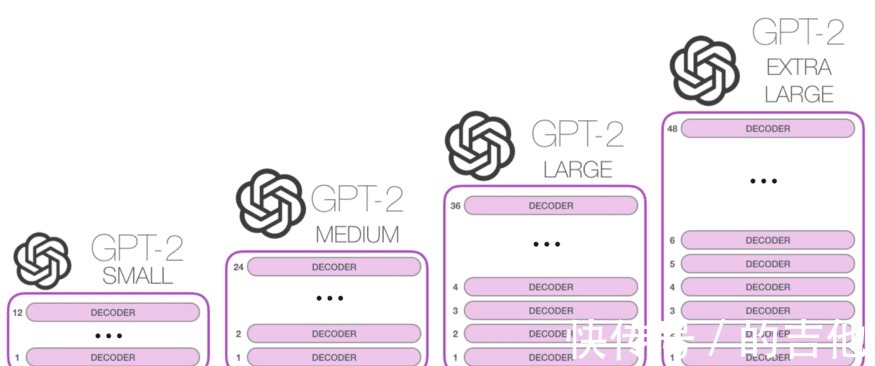
文章插图
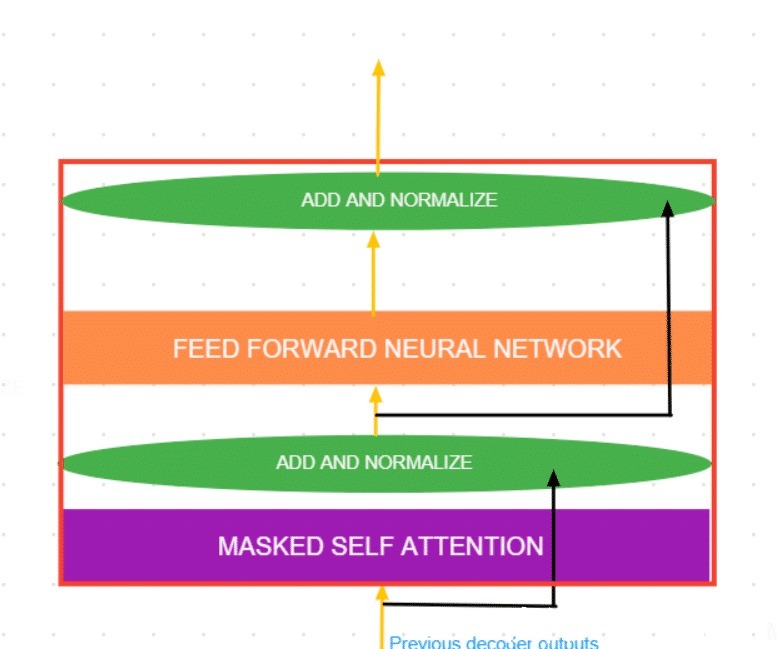
每个解码器单元主要由2层组成:
Masked 的自我关注前馈神经网络在每一步之后还有一个层规范化步骤和一个残差连接。
文章插图
直观地说,自注意分数给了我们当前时间步长的单词应该给予其他单词的重要性或注意(过去的时间步或者未来的时间步取决于注意力)。然而,在隐藏的自注意中,我们并不关心下一个或未来的单词。因此,transformer 解码器仅关注当前和过去的单词以及将来的单词。盖。这里有一个关于这个想法的漂亮的表述……【
epoch|使用深度学习模型创作动漫故事,比较LSTM和GPT2的文本生成方法】
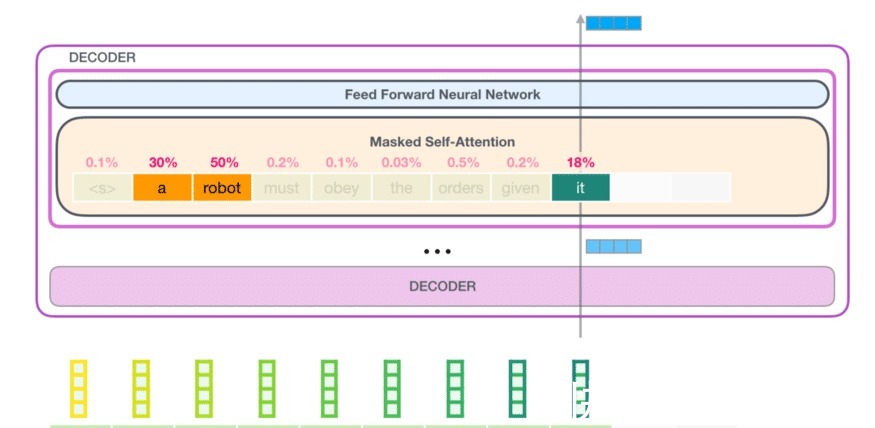
文章插图
在上面的示例中,当前单词是“ it”,并且您可以看到单词“ a”和“ robot”具有很高的注意力得分。 这是因为“ it”被用来指“robot”,“ a”也被指。您必须已经注意到上面输入文本开头的标记。 仅用于标记输入字符串的开头。 传统上,使用<| endoftext |>代替令牌。您还必须注意的另一件事是,这与传统语言建模相似,在传统语言建模中,可以看到当前令牌和过去令牌,并预测下一个令牌。 然后,将该预测令牌添加到输入中,然后再次预测下一个令牌。代码我已经将GPT2与Hugging Face库中的线性模型一起用于文本生成。 在这4个变体中,我使用了GPT2 small(具有117M个参数)。我已经在Google Colab上训练了模型,训练中的主要问题是弄清楚批大小和最大序列长度,以便在GPU上进行训练时不会出现内存不足的情况,批大小为10,最大序列长度为 300终于可以工作了。因此,我也删除了带有300个以上单词的提要,以便当我们生成提要直到300时,它实际上是完整的。创建数据集为了进行微调,首要任务是获取所需格式的数据,Pytorch中的数据加载器使我们可以非常轻松地做到这一点。步骤如下:
使用上面定义的clean_function清理数据。每个提要后都添加<| endoftext |>标记。使用HuggingFace的GPT2Tokenizer对每个大纲进行标记。为标记化单词创建一个遮罩(注意:此遮罩与我们讨论的被遮罩的自我注意不同,这是用于遮罩下一个将要看到的填充标记)。使用<| pad |>标记填充长度小于最大长度(此处为300)的序列。将令牌ID和掩码转换为张量并返回它们。import torchfrom config import tokenizerfrom utils import clean_synopsisfrom config import max_seq_lenclass AnimeDataset():def __init__(self,data):self.eos_tok = '<|endoftext|>'synopsis = clean_synopsis(data)synopsis = synopsis.apply(lambda x: str(x) + self.eos_tok)self.synopsis = synopsis.tolist()self.pad_tok = tokenizer.encode(['<|pad|>'])def __getitem__(self,item):synopsis = self.synopsis[item]tokens = tokenizer.encode(synopsis)mask = [1]*len(tokens)max_len = max_seq_lenif max_len>len(tokens):padding_len = max_len - len(tokens)tokens = tokens + self.pad_tok*padding_lenmask = mask + [0]*padding_lenelse:tokens = tokens[:max_len]mask = mask[:max_len]if tokens[-1]!= tokenizer.encode(self.eos_tok)[0]:tokens[-1] = tokenizer.encode(self.eos_tok)[0]return {'ids':torch.tensor(tokens,dtype = torch.long),'mask': torch.tensor(mask,dtype = torch.long),'og_synpsis':synopsis}def __len__(self):return len(self.synopsis)模型架构在这里,我们不需要明确地创建模型架构,因为Hugging Face库会为我们解决这个问题。 我们只需要导入带有语言模型的预训练GPT2模型即可。这个模型中的LM头是一个线性层,它输出每个词汇标记的分数(在softmax之前)。Hugging Face提供的带有LM头的GPT2Model的有趣之处在于,我们可以在此处直接传递标签(我们的输入令牌),并且标签在内部向右移动一级,模型与预测得分一起返回损失 也一样 实际上,它也返回模型中每一层的隐藏状态以及注意力得分,但我们对此并不感兴趣。我们可以导入模型和令牌生成器,并在配置类中定义所有超参数,如下所示:import transformersbatch_size = 10model_path = 'gpt2_epoch5.bin'max_seq_len = 300epochs = 5data_path = 'Data/eda-data.csv'tokenizer = transformers.GPT2Tokenizer.from_pretrained('gpt2')model = transformers.GPT2LMHeadModel.from_pretrained('gpt2')训练函数步骤:
训练功能从dataloader获取ID和掩码。通过模型传递ID和掩码。该模型输出一个元组:-(损失,预测分数,每个被屏蔽的关注层的键和值对列表,每个层的隐藏状态列表,注意力分数)我们仅对该元组中的前2个项目感兴趣。
执行向后传播并更新参数。返回该时期的平均损失。from tqdm import tqdmimport torchfrom utils import AverageMeterimport numpy as npdef train_fn(model,dataloader,optimizer,scheduler,device):model.train()tk0 = tqdm(dataloader, total = len(dataloader), leave = True, position = 0)train_loss = AverageMeter()losses = []for bi,d in enumerate(tk0):ids = d['ids'].to(device,dtype = torch.long)mask = d['mask'].to(device,dtype = torch.long)loss,out = model(input_ids = ids, labels = ids, attention_mask= mask)[:2]train_loss.update(loss.item())loss.backward()losses.append(loss.item())optimizer.step()scheduler.step()model.zero_grad()tk0.set_postfix(loss = train_loss.avg)return np.mean(losses)执行训练步骤: