使用NLP创建摘要
你有没有读过很多的报告 , 而你只想对每个报告做一个快速的总结摘要?你是否曾经遇到过这样的情况?
摘要已成为21世纪解决数据问题的一种非常有帮助的方法 。 在本篇文章中 , 我将向你展示如何使用Python中的自然语言处理(NLP)创建个人文本摘要生成器 。
前言:个人文本摘要器不难创建——初学者可以轻松做到!
什么是文本摘要基本上 , 在保持关键信息的同时 , 生成准确的摘要 , 而不失去整体意义 , 这是一项任务 。
摘要有两种一般类型:
- 抽象摘要>>从原文中生成新句子 。
- 提取摘要>>识别重要句子 , 并使用这些句子创建摘要 。
此外 , 提取摘要法比抽象摘要具有更好的总结效果 , 因为抽象摘要必须从原文中生成新的句子 , 这是一种比数据驱动的方法提取重要句子更困难的方法 。
如何创建自己的文本摘要器我们将使用单词直方图来对句子的重要性进行排序 , 然后创建一个总结 。 这样做的好处是 , 你不需要训练你的模型来将其用于文档 。
文本摘要工作流下面是我们将要遵循的工作流…
导入文本>>>>清理文本并拆分成句子>>删除停用词>>构建单词直方图>>排名句子>>选择前N个句子进行提取摘要
(1) 示例文本我用了一篇新闻文章的文本 , 标题是苹果以5000万美元收购AI初创公司 , 以推进其应用程序 。 你可以在这里找到原始的新闻文章:
你还可以从Github下载文本文档:
(2) 导入库
# 自然语言工具包(NLTK)import nltknltk.download('stopwords')# 文本预处理的正则表达式import re# 队列算法求首句import heapq# 数值计算的NumPyimport numpy as np# 用于创建数据帧的pandasimport pandas as pd# matplotlib绘图from matplotlib import pyplot as plt%matplotlib inline(3) 导入文本并执行预处理有很多方法可以做到 。 这里的目标是有一个干净的文本 , 我们可以输入到我们的模型中 。# 加载文本文件with open('Apple_Acquires_AI_Startup.txt', 'r') as f:file_data = http://kandian.youth.cn/index/f.read()这里 , 我们使用正则表达式来进行文本预处理 。 我们将(A)用空格(如果有的话…)替换参考编号 , 即[1]、[10]、[20] ,
(B)用单个空格替换一个或多个空格 。
text = file_data# 如果有 , 请用空格替换text = re.sub(r'\[[0-9]*\]',' ',text) # 用单个空格替换一个或多个空格text = re.sub(r'\s+',' ',text)然后 , 我们用小写(不带特殊字符、数字和额外空格)形成一个干净的文本 , 并将其分割成单个单词 , 用于词组分数计算和构词直方图 。形成一个干净文本的原因是 , 算法不会把“理解”和“理解”作为两个不同的词来处理 。
# 将所有大写字符转换为小写字符clean_text = text.lower()# 用空格替换[a-zA-Z0-9]以外的字符clean_text = re.sub(r'\W',' ',clean_text) # 用空格替换数字clean_text = re.sub(r'\d',' ',clean_text) # 用单个空格替换一个或多个空格clean_text = re.sub(r'\s+',' ',clean_text)(4) 将文本拆分为句子我们使用NLTK sent_tokenize方法将文本拆分为句子 。 我们将评估每一句话的重要性 , 然后决定是否应该将每一句都包含在总结中 。sentences = nltk.sent_tokenize(text)(5) 删除停用词停用词是指不给句子增加太多意义的英语单词 。 他们可以安全地被忽略 , 而不牺牲句子的意义 。 我们已经下载了一个文件 , 其中包含英文停用词这里 , 我们将得到停用词的列表 , 并将它们存储在stop_word 变量中 。
# 获取停用词列表stop_words = nltk.corpus.stopwords.words('english')(6) 构建直方图让我们根据每个单词在整个文本中出现的次数来评估每个单词的重要性 。我们将通过(1)将单词拆分为干净的文本 , (2)删除停用词 , 然后(3)检查文本中每个单词的频率 。
# 创建空字典以容纳单词计数word_count = {}# 循环遍历标记化的单词 , 删除停用单词并将单词计数保存到字典中for word in nltk.word_tokenize(clean_text):# remove stop wordsif word not in stop_words:# 将字数保存到词典if word not in word_count.keys():word_count[word] = 1else:word_count[word] += 1让我们绘制单词直方图并查看结果 。plt.figure(figsize=(16,10))plt.xticks(rotation = 90)plt.bar(word_count.keys(), word_count.values())plt.show()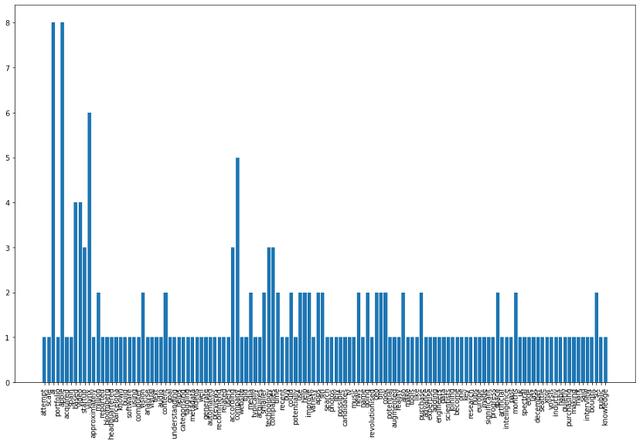 文章插图
文章插图
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 轻松|使用 GIMP 轻松地设置图片透明度
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 设置页面|QQ突然更新,加入了一项新功能,可以让你创建一个独一无二的QQID
- 撕破脸|使用华为设备就罚款87万,英政府果真要和中国“撕破脸”?
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- 机身|轻松使用一整天,OPPO K7x给你不断电体验