按关键词阅读:
2.在JavaScript的控制下 , 浏览器拖动到一定位置 , 触发下一次查询请求
3.传递上次接收到的max_id , 再在这个请求中获得下一个max_id值
4.到2
以此类推
当然 , 这里没有求证是否正确 , 因为要看他的JavaScript , 没有必要 , 大概正确即可 , 功能完成就行
因此 , 我们的爬虫思路可以跟他的编码思路一样
1.发起第一次请求
2.提取评论内容
3.提取max_id
4.发起下一个请求
5.到2
以此类推
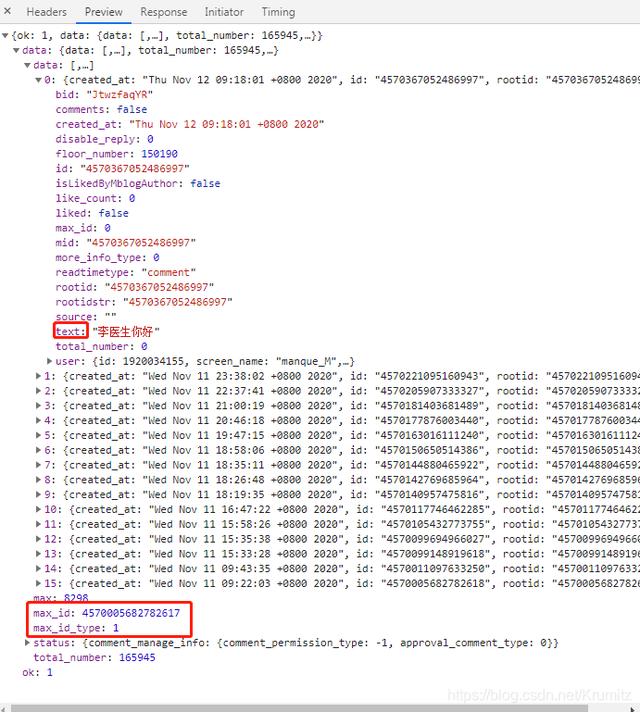
3.2 内容分析 刚刚的返回内容都是通过preview查看的 , 实际的response中以json串返回了一大堆数据 , 该串太长 , 就不贴上来了
通过preview可以知道
 文章插图
文章插图
评论的内容对应“text”中的值
max_id和max_id_type对应max_id和max_id_type的值
值得一提的是 , 实际上评论的内容是以类似
"text":"\u674e\u533b\u751f\u4f60\u597d" 这样的unicode编码返回的 , 所以在提取出来存到本地使用时 , 要转码再写入 , 要不会不显示中文 , 在等等的编码环节会提到
因为返回的是json串 , 应该无法使用css选择器提取内容 , 因此目前只能想到使用正则表达式提取
而整个返回包中text只有评论时出现 , 所以我们可以简单的写一个匹配
"text":"(.*?)" 的内容就好了
其他需要提取的内容也是如此
4. 编码4.1 spider.py 程序入口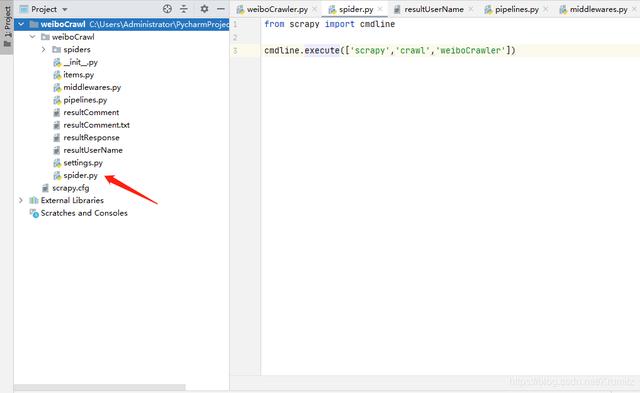 文章插图
文章插图
首先我新建了一个spider.py
from scrapy import cmdline cmdline.execute(['scrapy','crawl','weiboCrawler'])这样我就可以直接使用pycharm的运行启动了 , 不需要在控制台输命令
如果有需要的话请根据上图的结构新建文件
第三个参数需要对应你的爬虫的名字
4.2 settings.py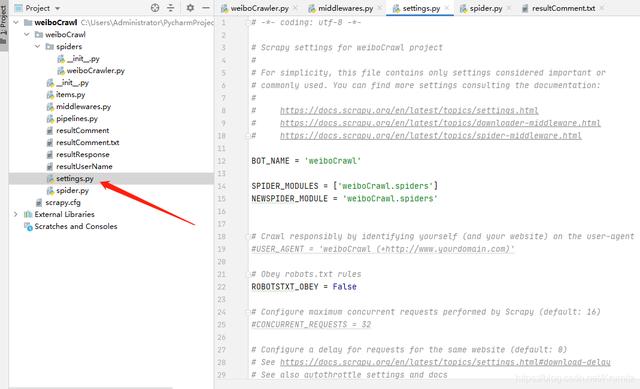 文章插图
文章插图
修改
ROBOTSTXT_OBEY = False 修改
COOKIES_ENABLED = True 去注释 , 将中间件启用
# Enable or disable downloader middlewares# See= {'weiboCrawl.middlewares.WeibocrawlDownloaderMiddleware': 543,} 修改Headers
DEFAULT_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'}4.3 middlewares.py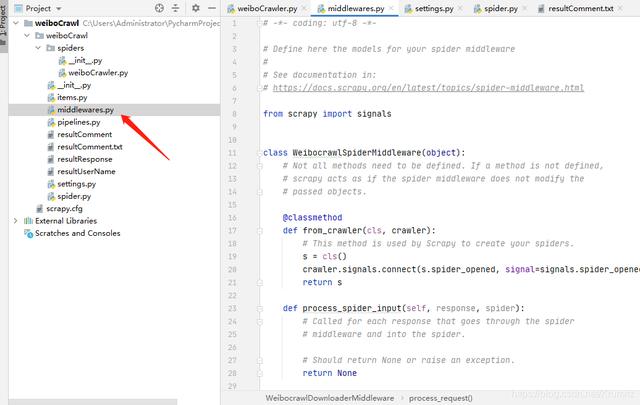 文章插图
文章插图
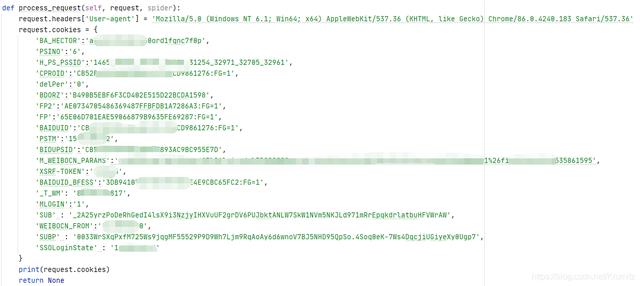
在process_request函数中增加你的cookies的值 , 如果没有cookie , 微博可能会视为游客用户 , 无法正确加载评论
 文章插图
文章插图
这里有些cookie应该是不需要的 , 但是为了保险起见 , 我还是全部加上了
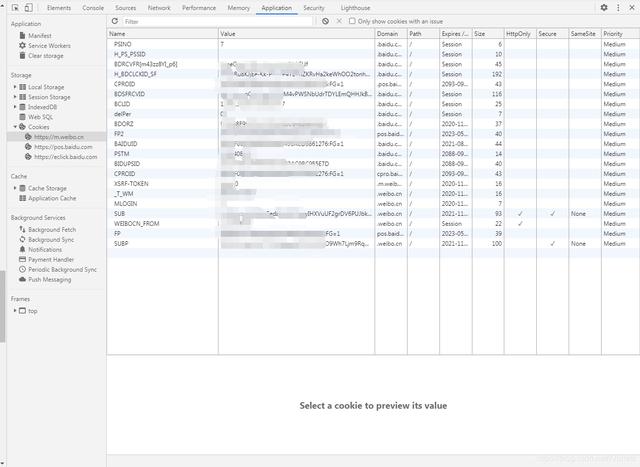
你可以通过
浏览器F12-Application-Storage-Cookies-对应的网址
 文章插图
文章插图
查看你的cookies并加入
最后 , 该函数要返回None , 返回其他可能会出错 , 如果有其他的需求的话再考虑返回其他值 , 这次不需要
4.4 weiboCrawler.py 文章插图
文章插图
在这个文件中 , 我们只要完成分析得到的需求即可 , 即
请求-提取内容-请求
剩下的交给框架去做就好了
# -*- coding: utf-8 -*-import scrapyimport reimport sysimport timereload(sys)sys.setdefaultencoding('utf-8') class WeibocrawlerSpider(scrapy.Spider):name = 'weiboCrawler'allowed_domains = ['m.weibo.cn']start_urls = [';mid=4466768535861595mid=4466768535861595 --tt-darkmode-color: #979797;">5. 结果 文章插图
文章插图
评论是成功提取出来了 , 对应网页上的内容也可以对应起来
但是一些@别人的啊 , 或者是一些微博表情变成了链接 , 看起来很乱
想去掉也是可以的 , 但是我觉得没有必要 , 先就这样了
6. 后记总结 因为只需要写一个例子出来 , 所以写的很简单 , 复用性不高
没有深入的了解Scrapy框架的原理
完成的功能也很简单 , 只提取了评论 , 如果需要提取用户名或者其他内容 , 按照分析中的思路来做即可
另外 , 由于数量过大 , 我没有爬取该微博全部的评论 , 只爬取了一部分 , 不确定设置了time.sleep后是否还会被服务器屏蔽
【从安装软件开始教你爬取微博上万条评论数据!这都还学不会吗?】 如果有被屏蔽的情况发生 , 可以考虑引入Cookie池 , 这一类的文章在我研究如何引入cookie时看到过 , 各位读者可以自己搜索一下![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2N062020.html
标题:从安装软件开始教你爬取微博上万条评论数据!这都还学不会吗?( 二 )