按关键词阅读:
Word2Vec词嵌入:单词编码的这种方法(通常称为单词嵌入)考虑了上下文 。例如 , 我们可以预期国王和王室一词的空间距离要比鹦鹉和蜂蜜小 。Word2vec使用浅层两层神经网络执行特定任务(基于所使用的方法) , 并为每个单词学习隐藏层的权重 。这些学习的隐藏层权重用作我们的最终单词向量 。您可以阅读原始论文 , 以深入了解如何获得这些单词向量 。但总的来说 , 这是使用Word2Vec获取基于上下文的单词向量的两种常用方法:
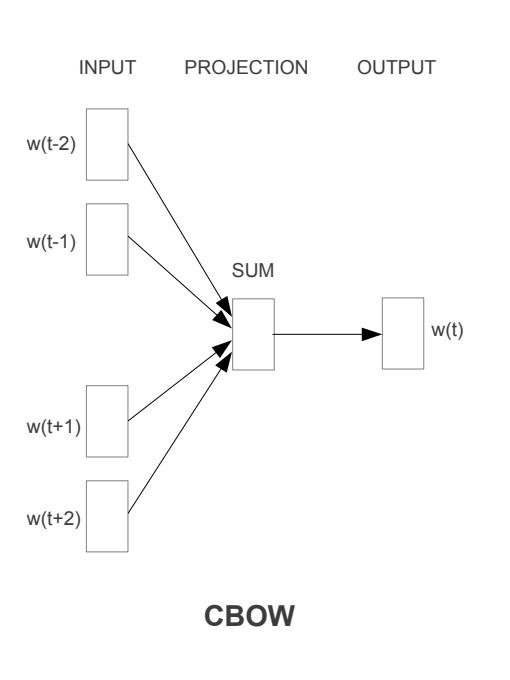
CBOW(连续词袋):
 文章插图
文章插图
source :
CBOW模型体系结构尝试根据源上下文单词(环绕单词)预测当前的目标单词(中心单词) 。
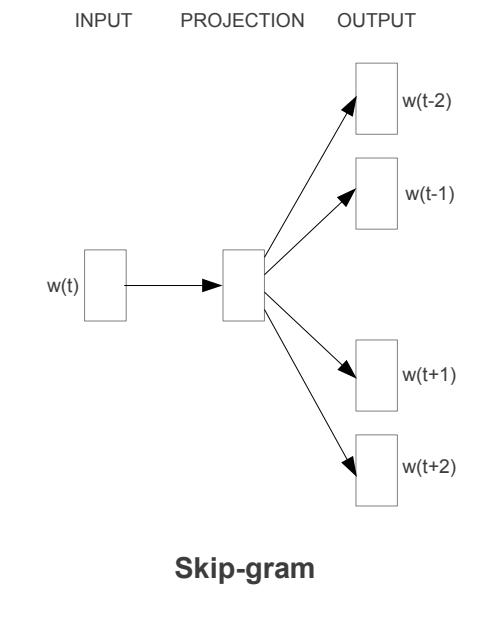
跳过—语法模型 Skip — Gram:
 文章插图
文章插图
source:
Skip-gram模型体系结构试图实现与CBOW模型相反的功能 。它尝试在给定目标单词(中心单词)的情况下预测源上下文单词(环绕单词) 。
在两种情况下 , 窗口大小(每侧考虑的周围单词数)都是超参数 。
Glove 手套:
Glove与Word2vec非常相似 , 但与Word2vec不同 , Glove利用了单词的全局共现 , 而不仅仅是局部上下文 , 这使它在某些方面更加强大 。同样 , 通过阅读原始论文 , 您可以更好地理解 。
词嵌入-如何使用它们?现在我们对什么是词嵌入及其为何有用有了一个大概的想法 , 让我们来谈谈如何利用它们来发挥我们的优势 。
使用预训练的单词向量:
有许多公开的 , 经过预先训练的 , 具有不同向量长度的预训练词向量 , 例如Glove , fasttext等 。 这些已经在大规模语料库(Wikipedia , twitter和常见的抓取数据集)上进行了训练 , 可以下载并用于在我们的语料库中对词进行编码 。
示例:使用词向量相似度查找与给定文档最相似的文档
问题陈述:
给定一组属于不同主题的文档(训练集) , 当给定一个新文档时 , 我们能否从原始文档集中找到与其最相似的文档?
方法:
· 将经过预训练的单词向量文件加载到字典中 , 以单词为键 , 其向量表示为值 。
· 通过对特定文档中存在的单词的单词矢量求平均值 , 找到训练集中每个文档的质心矢量(忽略不属于词汇表的单词)
· 找到新文档的质心 , 从训练集中选择其质心最接近新文档质心的文档(使用合适的相似度度量 , 例如欧氏距离 , 余弦相似度等)
代码:
这是一些辅助函数 , 用于加载glove字典 , 查找质心以及查找质心之间的距离:
mport numpy as np#loading the glove file into a dictionary of wordsdef load_glove(filename):glove_dict = {}with open(filename) as f:file_content = f.readlines()for line in file_content:line_content = line.split()glove_dict[line_content[0]] = np.array(line_content[1:], dtype=float)return glove_dict#get centroid of a particular documentdef get_centroid(text, gloves):words_list = preprocess_text(text)word_vec_sum = 0words_count = 0for w in words_list:if w in gloves:word_vec_sum += gloves[w]words_count += 1if words_count:return word_vec_sum/words_countelse:return 0#get distance between two centroidsdef get_distance (a,b):return (np.linalg.norm(a - b))训练从头开始生成单词向量:如果要查找特定语料库的单词向量 , 可以使用gensim包进行训练 。
例:
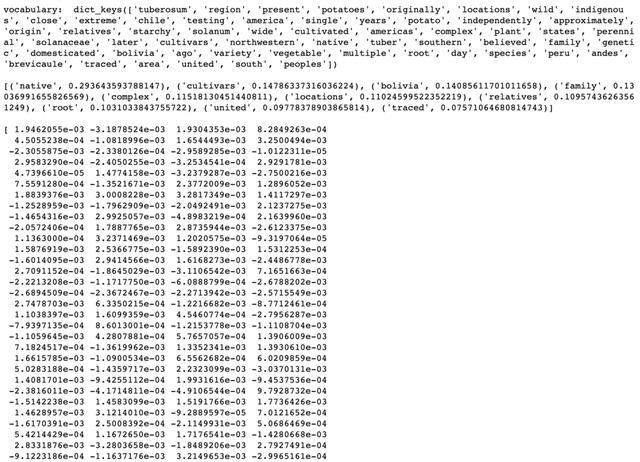
import gensimwith open('./potato.txt') as f:text = f.read()words_list = [preprocess_text(text)]model = gensim.models.Word2Vec(words_list,size=150,window=2,min_count=1,workers=10,iter=10)print('vocabulary: ', model.wv.vocab.keys(),'\n')print(model.wv.most_similar('starchy'),'\n')print(model.wv.word_vec('potato'),'\n')输出:
 文章插图
文章插图
在上面的示例中 , 我仅使用了Wikipedia页面上的两行内容 。训练是非常快速和简单的 , 您只需要输入单词列表 , 所需单词矢量的大小 , 窗口大小(要考虑的周围单词的数量)以及出现该单词的最小次数 它被视为词汇的一部分 。检查词汇表 , 获取向量以及查看语料库中最常用的词都很容易 。当然 , 从头开始的训练可能并不总是能获得与预训练的结果一样好的结果 , 但是对于涉及数据看起来与预训练中使用的数据集截然不同的问题的好处 。
数据探索带有文本数据的EDA不如表格或数字数据那么简单 。但是 , 有些库可以使这些任务更容易 。对于本文的其余部分 , 我使用了Kaggle的以下数据集:Toxic Comment Classification Challenge
使用spacy探索:![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2V352020.html
标题:自然语言处理(NLP)入门( 二 )