按关键词阅读:
Spacy是一个非常强大的NLP库 , 具有多种用途 。它可用于命名实体识别 , 识别单词所属的语音部分 , 甚至给出单词的矢量和情感 。
代码:
import spacynlp = spacy.load("en_core_web_sm")text = ' '.join(toxic_data[:1000]['comment_text'])doc = nlp(' '.join(preprocess_text(text)))x = doc[0]print('word:', x, '\n')print('part of speech:', x.pos_, '\n')print('sentiment:', x.sentiment,'\n')print('sentiment:', x.sentiment,'\n')print('word vector:', x.vector)输出:
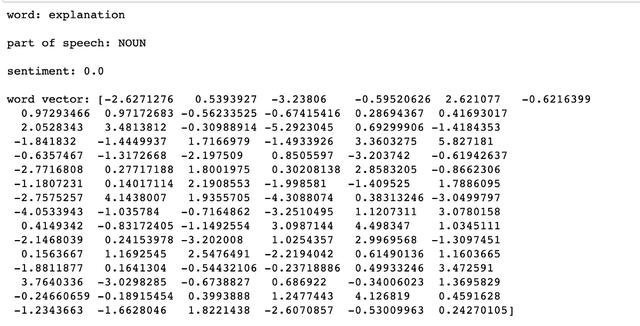 文章插图
文章插图
来自spacy的nlp函数将每个单词转换为具有各种属性的令牌 , 例如上面示例中提到的那些属性 。
词云 Wordcloud:
Wordclouds是一种简单而有趣的方法 , 用于可视化各种单词在我们的语料库中出现的频率 。让我们以评论数据中最常出现的名词为例:
代码:
from wordcloud import WordCloudimport matplotlib.pyplot as pltdef make_wc(word_list):wordcloud = WordCloud()wordcloud.fit_words(dict(Counter(word_list).most_common(40)))fig=plt.figure(figsize=(10, 10))plt.imshow(wordcloud)plt.axis("off")plt.show()make_wc([token.text for token in doc if token.pos_ in ['NOUN']])输出:
 文章插图
文章插图
article, talk, and page are the most frequently occurring nouns
情感分析在NLP中 , 一项非常常见的任务是确定特定评论或文本的正面或负面情感 。vaderSentiment软件包提供了一种快速简便的方法:
代码:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzersentiment_analyzer = SentimentIntensityAnalyzer()def get_sentiment_score(text):return sentiment_analyzer.polarity_scores(text)['compound']输出:
 文章插图
文章插图
The sentiment score for a toxic comment seems to be close to -1 whereas a non-toxic one has a score
The sentiment score for a toxic comment seems to be close to -1 whereas a non-toxic one has a score greater than 0 as expected
文字分类对于分类 , 我使用过的最简单的库之一是fasttext 。它于2016年由Facebook发布 , 并使用线性技术将单词向量组合到代表文本的向量中 , 并用于计算分类标准 。它花费很少的时间进行培训 , 并为大多数常见的文本分类问题提供了不错的结果 。它可以用来提出基线模型 。您可以阅读原始文章 , 以更好地了解fasttext分类器背后的机制 。
我们已经介绍了大多数基础知识 , 但是NLP当然还有很多 。但是 , 本文是一个不错的起点 , 希望对初学者有所帮助 , 因为这是我刚开始学习的第一件事!
【自然语言处理(NLP)入门】(本文翻译自Aakanksha NS的文章《Getting Started with Natural Language Processing (NLP) — preprocessing, word embeddings, text classification, and more!》 , 参考:)
![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2V352020.html
标题:自然语言处理(NLP)入门( 三 )