NeurIPS'20| AI编程:如何从复制粘贴走向推理合成( 二 )
深度学习缺乏组合泛化能力程序是具有组合性的 , 即使是一个很小的 DSL(领域很限定 , 语法很简单 , 预定义的函数很有限) , 也能够产生一个指数爆炸式的巨大程序空间 。 任何一个训练数据集中所包含的程序 , 都只是这个指数级程序空间中的冰山一角 。 因此 , 若一个 AI 编程机器人缺乏组合泛化能力 , 则必然会导致如前面漫画所体现的“人工智障”情况 。
从这个角度出发 , 越来越多的研究工作开始重新审视现有的基于深度学习的 AI 编程解决方案 。 当前主流的解决方案大多基于深度编解码架构(Neural Encoder-Decoder Architectures) 。 纽约大学教授 Brenden Lake 和 Facebook AI 科学家 Marco Baroni 的一系列研究表明 , 现有的深度学习模型并不具有组合泛化能力[4] 。 图4简单展示了他们的研究方法 。 实验任务是将诸如“run after walk”这样的自然语言句子翻译成诸如“WALK RUN”这样的指令序列(程序) 。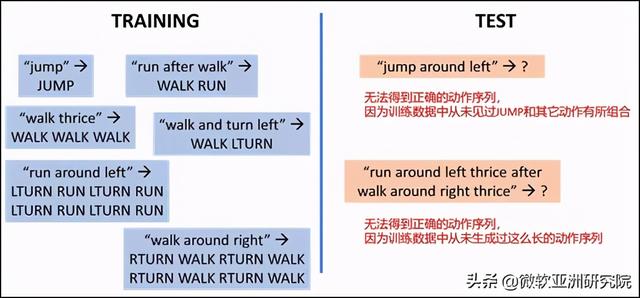 文章插图
文章插图
图4:即使是简单的任务 , 现有的深度学习模型也难以泛化到训练集之外的组合上
表面上看 , 这是个非常简单的序列到序列生成任务 。 在收集到大量自然语言句子以及它们所对应的指令序列之后 , 随机划分成训练集和测试集 , 用现有的深度学习模型进行训练 , 即可在测试集上达到99.8%的准确率 。 然而 , 一旦从组合性的角度对训练集和测试集的划分方式加以约束 , 深度学习模型就不再有效 。 例如 , 为了验证模型的系统性 , 可以让模型在训练阶段除了“jump -> JUMP”之外不再接触任何与 jump 有关的样例 , 而在测试阶段去看模型是否能够在包含 jump 的句子(例如:“jump around left”)上做对 。 实验结果表明 , 在这样的设定下 , 深度学习模型仅能达到1.2%的准确率 。
另一方面 , 为了验证模型的生产性 , 则可以让模型在训练阶段只接触指令序列长度小于24的样例 , 而在测试阶段去看模型是否能够正确地生成长度不小于24的指令序列 。 实验结果表明 , 在这样的设定下 , 深度编解码网络仅能达到20.8%的准确率 。 诸如此类的一系列研究表明 , 现有的深度学习模型在语义解析任务上不具备组合泛化能力[4][5] 。
在当前的工业实践中 , 从业者主要通过深度学习与人工规则的混合系统来缓解这一瓶颈(数据增广也可以归入其中 , 因为需要增广哪些数据通常也需要人工归纳) 。 本文想要探讨一种更有趣的思路:是否能够在深度学习中引入合适的归纳偏置 , 使之摆脱简单的记忆与模仿 , 也不需要引入人工规则 , 而是自动地探索、发现并归纳出数据集中内在的组合性规律 , 从而使端到端的深度神经网络具备组合泛化能力 。
在深度神经网络中模拟人脑的抽象化思维人类的认知之所以具备组合泛化能力 , 关键在于抽象化(Abstraction) , 即省略事物的具体细节 , 以减少其中所含的信息量 , 从而更有利于发现事物间的共性(规律) 。
这种抽象化能力是一种代数能力 , 而这正是现有的深度神经网络所缺乏的 。 如图5左侧所示 , 对于 AI 编程任务 , 现有的深度神经网络更倾向于“死记硬背”:自然语言和程序语言被看作是两个集合 , 那么学习到的只能是具体的自然语言句子和具体的程序之间的简单映射关系 , 这样自然是难以做到组合泛化的 。 对于这一问题 , 关键思路在于 , 将自然语言和程序语言看作是两个代数结构 , 且需要让深度神经网络倾向于学习这两个代数结构之间的同态(如图5右侧所示) 。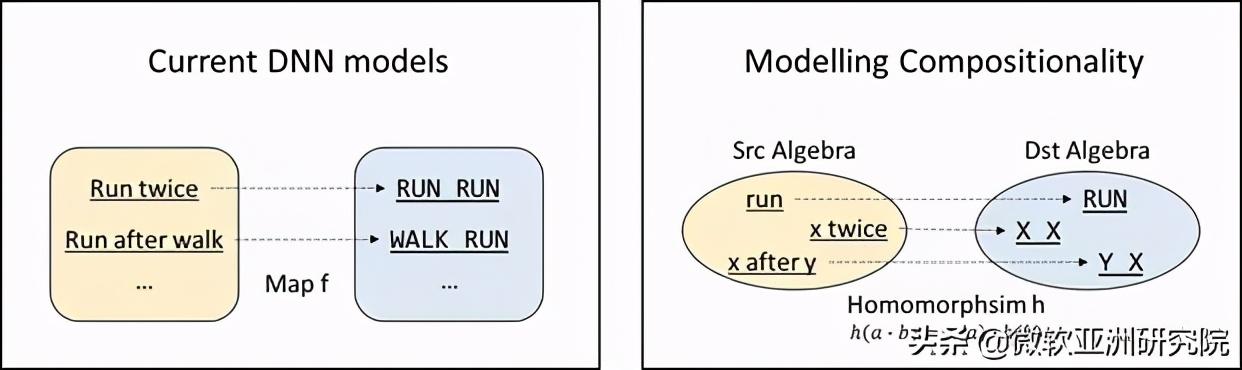 文章插图
文章插图
图5:不要学习集合之间的映射 , 改为学习代数结构之间的同态
更形象地来说 , 如果训练数据中已经包含“run opposite walk”、“run after left”、 “walk twice”等样例 , 现在面对如下样例:
INPUT: “run opposite left after walk twice”
OUTPUT: “WALK WALK LTURN LTURN RUN”
深度学习模型的实质是记住诸如此类输入输出对之间的映射关系 , 而人类的认知则倾向于做出如图6所示的抽象化: 文章插图
文章插图
图6:相比于深度学习的直接记忆与模仿 , 人类思维更倾向于将具体对象层次化地抽象为具有共性的解析表达式
图6的左侧自下而上地给出了对于作为输入的自然语言句子的抽象化过程 。 在第1、2、4步 , 分别剥离掉“run”、“left”和“walk”这三个单词的具体属性 , 将它们抽象为变量;在第3、5、6步 , 分别剥离掉“$x opposite $y”、“$y twice”和“$x after $y”这三个子句属性 , 也将它们抽象为变量 。 人类记住的并非输入与输出之间的直接映射 , 而是这一抽象化过程中每一步所产生的局部映射(如图6右侧所示)的集合 。 例如 , 在第1步中 , 将单词“run”映射到了程序“RUN”上;在第3步中 , 将抽象子句“$x opposite $y”映射到了程序“$Y $Y $X” 。 此处的“$X”是一个程序中的变量 , 指代自然语言中的变量“$x”所对应的程序;同样地 , $Y$亦是一个程序中的变量 , 指代自然语言中的变量“$y”所对应的程序 。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐