NeurIPS'20| AI编程:如何从复制粘贴走向推理合成( 三 )
上述例子说明了 , 相比于直接记住相对复杂的具体映射 , 人类更倾向于从中归纳出相对简单的共性抽象映射 , 从而获得组合泛化能力 。 因此 , 为了让深度学习也获得组合泛化能力 , 需要设计一种能够模拟人类认知中的抽象化过程的新型神经网络架构 。
将输入/输出的各个具体对象形式化 , 称为源域表达式(Source Expression, SrcExp)/目标域表达式(Destination Expression, DstExp) , 统称为表达式(Expression, Exp) 。 若表达式中的某个/某些子部分被替换为变量 , 则称这些带变量的表达式为解析表达式(Analytical Expression, AE) 。 同样地 , 解析表达式也可分为源域解析表达式(SrcAE)和目标域解析表达式(DstAE) 。
对于每个输入的 SrcExp , 神经网络架构需要通过若干次抽象化操作逐渐地将其转换为更简单的 SrcAE(如图6左侧所示) 。 在这一抽象化过程中 , 每个被置换为变量的 SrcAE 将被解析为一个 DstAE , 最终由这些 DstAE 组合形成一个 DstExp 作为输出(如图6右侧所示) 。 模型需要以这种抽象化过程作为一种归纳偏置 , 在不依赖任何人工预定义的抽象/映射规则的前提下 , 完全自动化地完成对具体的抽象化过程与表达式映射的探索与学习 。
LANE 的模型实现新型的神经网络架构 LANE(Learning Analytical Expressions)能够在语义解析任务中模拟人类的抽象化思维 , 从而获得组合泛化能力 。 在之前的神经网络学习框架中 , 神经网络是直接被用来学习一个从具体的源字串(Source Token Sequence)到具体的目标串(Destination Token Sequence)的映射函数 。 而在 LANE 中 , 需要学习的是一个定义域和值域分别是由源字串抽象化后导出的解析表达式和目标串解析表达式的函数 。
LANE 由两个神经网络模块构成:一个模块称为 Composer , 由一个 TreeLSTM 模型实现 , 负责对输入的 SrcExp 进行隐式树状归纳(Latent Tree Induction) , 从而得到逐渐抽象简化的中间 SrcAE;另一个模块称为 Solver , 负责在每次抽象发生时进行局部语义解析 , 将语义细节剥离并保留在记忆单元(Memory)中 , 从而使得后续处理过程中这些细节被简化为一个变量 。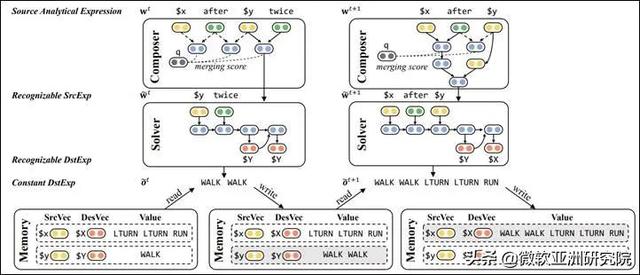 文章插图
文章插图
图7:LANE: 用神经网络学习隐式的解析表达式 , 以模拟人类的抽象化思维
图7解释了 LANE 的工作流程 , 也展示了 LANE 如何处理图6中的第5步和第6步抽象 。 在第5步抽象化过程中 , 对于当前的 SrcAE “$x after $y twice” , Composer 基于树状 LSTM 输出下一步抽象动作:应该对“$y twice”这个局部进行抽象化 。 Solver 则使用一个深度编解码网络将“$y twice”解释为 DstAE “$Y $Y” , 与原 Memory 中的“$Y = WALK”结合得到新变量所对应的 DstExp “WALK WALK” , 并以此更新 Memory 。 经过这一过程 , “$x after $y twice”中的“$y twice”这部分细节被剥离掉了 , 形成了一个抽象程度更高的 SrcAE “$x after $y” , 进而可以开始第6步抽象 。 通过这样的方式 , Composer 与 Solver 协同工作 , LANE 将输入的 SrcExp 逐渐抽象为简化程度越来越高的 SrcAE , 直到形成一个由单变量构成的最简 SrcAE 。 该变量在 Memory 中对应的取值即为最终输出的 DstExp 。
由于 LANE 中包含不可求导的离散操作 , 因此可以基于强化学习(Reinforcement Learning)来实现模型的训练 。 模型训练有如下三个关键点:
1. 奖励(Reward)设计。 Reward 分为两部分:一部分是基于相似度的奖励 , 即模型生成的 DstExp 与真实的 DstExp 之间的序列相似度;另一部分是基于简洁度的奖励 , 它是受奥卡姆剃刀原则启发 , 用于鼓励模型生成更通用/简洁的解析表达式 。 由于这两个奖励的设计都没有刻意引入任务相关的特别知识 , 表明 LANE 应该具有很大的普适性 。
2. 分层强化学习(Hierarchical Reinforcement Learning) 。 Composer 和 Solver 协同工作 , 但地位并不相同:Solver 的决策依赖于 Composer 的决策 。 因此 , 将 Composer 和 Solver 分别视作高层代理(High-level Agent)和底层代理(Low-level Agent) , 应用分层强化学习联合训练这两个模块 。
3. 课程学习(Curriculum Learning) 。 为了加强探索效率 , 根据 SrcExp 的长度将数据划分为从易到难的多个课程 。 模型先在最简单的课程上进行训练 , 而后逐渐将更难的课程加入训练 。
实验结果Lake 等人建立了一套基准数据集 SCAN , 用于评测语义解析系统的组合泛化能力[4] 。 该数据集上衍生出了多个子任务 , 用于度量不同方面的组合泛化能力 。 例如 , ADD_JUMP 子任务用于度量模型是否能够处理新引入元素的组合;LENGTH 子任务用于度量模型是否能够生成超出训练数据中已知长度的组合 。 研究实验结果表明 , LANE 在这些子任务上均达到了100%的准确度 。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐