YOLOv4团队开源最新力作!1774fps、COCO最高精度,分别适合高低端GPU的YOLO
本文是YOLOv4的原班人马(包含CSPNet一作与YOLOv4一作AB大神)在YOLO系列的继续扩展 , 从影响模型扩展的几个不同因素出发 , 提出了两种分别适合于低端GPU和高端GPU的YOLO 。
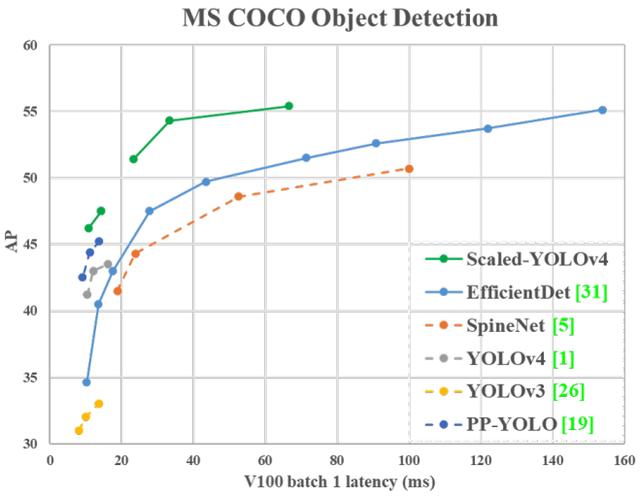
该文所提出的YOLO-large在MSCOCO取得前所未有的精度(已公开的研究成果中最佳) , 且可以保持实时推理;所提出的YOLO-tiny在RTX 2080Ti显卡上结合TensorRT+FP16等技术 , 可以达到惊人的1774FPS@batch=4. 文章插图
文章插图
论文标题:Scaled-YOLOv4:Scaling Cross Stage Partial Network
论文链接:
开源代码:
1 介绍
本文提出一种“网路扩展(Network Scaling)”方法 , 它不仅针对深度、宽度、分辨率进行调整 , 同时调整网络结果 , 作者将这种方法称之为Scaled-YOLOv4 。
由此得到的YOLOv4-Large取得了SOTA结果:在MS-COCO数据集上取得了55.4%AP(73.3% AP50) , 推理速度为15fps@Tesla V100;在添加TTA后 , 该模型达到了55.8%AP(73.2%AP50) 。 截止目前 , 在所有公开论文中 , YOLOv-Large在COCO数据集上取得最佳指标 。
由此得到的YOLOv4-tiny取得了22.0%AP(42.0%AP50) , 推理速度为443fps@TRX 2080Ti;经由TensorRT加速以及FP16推理 , batchsize=4时其推理速度可达1774fps 。
本文的主要贡献包含以下几点:
- 设计了一种强有力的“网络扩展”方法用于提升小模型的性能 , 可以同时平衡计算复杂度与内存占用;
- 设计了一种简单而有效的策略用于扩展大目标检测器;
- 分析了模型扩展因子之间的相关性并基于最优划分进行模型扩展;
- 通过实验证实:FPN structure is inherently a once-for-all structure
- 基于前述分析设计了两种高效模型:YOLOv4-tiny与YOLOv4-Large 。
 文章插图
文章插图模型扩展原则
在这部分内容里面 , 我们将讨论一下模型扩展的一些准则 。
从三个方面展开介绍:
(1) 量化因子的分析与设计;
(2) 低端GPU上tiny目标检测器的量化因子;
(3) 高端GPU上目标检测器的量化因子设计分析 。
模型扩展通用原则When the scale is up/down, the lower/higher the quantitative cost we want to increase/decrease, the better. ----author
上面给出了模型扩展所需要考虑的一些因素 。 接下来 , 我们将分析几种不同的CNN模型(ResNet, ResNeXt, DarkNet)并尝试理解其相对于输入大小、层数、通道数等的定量损失 。
对于包含k层b个通道的CNN而言 , ResNet的计算量为:
ResNeXt的为:
DarkNet的为:
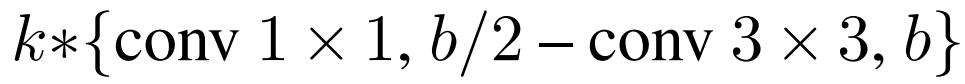 文章插图
文章插图假设用于调整图像大小、层数以及通道数的因子分别为
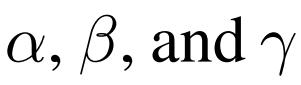 文章插图
文章插图, 其调整对应的FLOPs变化见下表 , 可以看到:它们与FLOPs提升的关系分别是
square, linear, square 。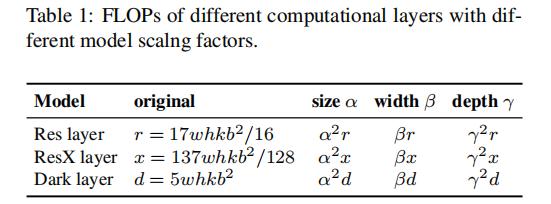 文章插图
文章插图CSPNet可以应用与不同的CNN架构中 , 且可以降低参数量与计算量 , 同时还可以提升精度与降低推理耗时 。
下表给出了CSPNet应用到ResNet , ResNeXt与DarkNet时的FLOPs变化 , 可以看到:新的架构可以极大的降低计算量 , ResNet降低23.5% , ResNeXt降低46.7% , DarkNet降低50.0% 。
因此CSP-ized是适合模型扩张的最佳模型 。
 文章插图
文章插图为低端设备扩展Tiny Model对于低端设备而言 , 模型的推理速度不仅受计算量、模型大小影响 , 更重要的是 , 外部设备的硬件资源同样需要考虑 。 因此 , 当进行tiny模型扩展时 , 我们必须考虑带宽、MACs、DRAM等因素 。 为将上述因素纳入考量范围 , 其设计原则需要包含西面几个原则:
让计算复杂度少于 .
相比大模型 , 轻量型模型的不同之处在于:参数利用率更高(保采用更少的计算量获得更高的精度) 。
当进行模型扩展时 , 我们期望计算复杂度要尽可能的低 。 下表给出了两种可以高效利用参数的模型对比 。
 文章插图
文章插图对于通用CNN来说 , 之间的性见上表 。 因此 , DenseNet的计算复杂度为,OSANet的计算复杂度为 。
两者的计算复杂度阶段都比ResNet的更低 。 在这里作者选用了OSANet作为tiny模型的选型 。
最小化/平衡特征图大小
为获得最佳的推理速度-精度均衡 , 作者提出了一个新的概念用于在CPSOSANet计算模块之间进行梯度截断 。 如果把CSPNet设计思想用到DenseNet或者R二十Net架构中 , 由于第层的输出是到的集成融合 , 我们必须把完整的计算模块当做一个整体来看待 。 由于OSANet的计算模块属于PlainNet架构的范畴 , 这就使得CSPNet的任一层都可以得到有效的梯度截断 。
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 工程师|AWS偏爱Rust,已将Rust编译器团队负责人收入囊中
- 团队|为什么项目管理非常重要?
- 高学历|薇娅一夜带货53.2亿,少不了这支高学历团队!
- 视觉|首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金
- 驱动|开源之系统:Ubuntu20.04电脑安装无线网卡驱动并解决包依赖关系
- 新媒体工作室|勇当政法新媒体高质量发展排头兵,曲阜检察团队风采展
- 首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金
- 「开源资讯」Gradle 6.7 发布,增量构建改进
- 这款开源图表库让你的开发溜到飞起