可变形卷积在视频学习中的应用:利用带有稀疏标记数据的视频帧
 文章插图
文章插图
卷积层是卷积神经网络的基本层 。 虽然它在计算机视觉和深度学习中得到了广泛的应用 , 但也存在一些不足 。 例如 , 对于某些输入特征图 , 核权值是固定的 , 不能 适应局部特征的变化 , 因此需要更多的核来建模复杂的特征图幅 , 这是多余的 , 效率不高 。 体积膨胀 , 由于输出转换的接受野始终是矩形的 , 作为层叠卷积的累积 效应 , 接受野会越来越大 , 接受野中会包含一些与输出转换无关的背景 。 不相关的背景会给输出位移的训练带来噪声 。
为了克服上述问题 , 你想对传统的卷积层做一个小小的改变:内核可以适应局部特征的变化 , 接受场可以收敛到与输出对应的语义背景 。 虽然这些想法看起来很复杂 , 但是幸运的是 , 它已经被实现 了 , 这个改进的卷积层叫做可变形卷积层 。
在这篇文章中 , 我将介绍以下主题:
1. 可变形卷积
1. 使用可变形卷积增强关键点估计的性能
1. 使用可变形卷积增强实例分割的性能
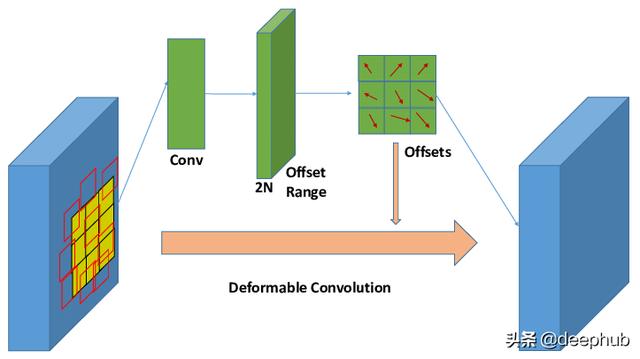
可变形卷积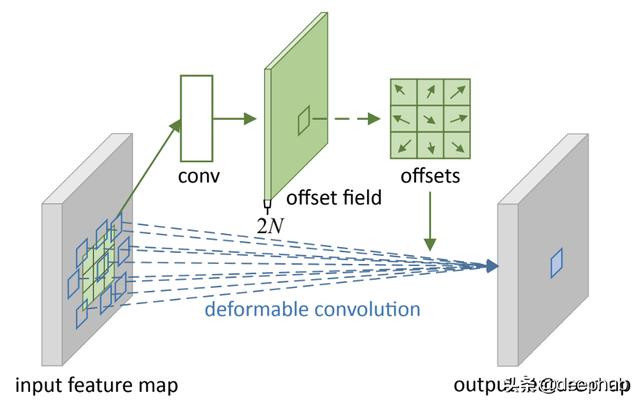 文章插图
文章插图
可变形卷积是一个卷积层加上偏移量学习 。如上所示 , 对于卷积核的每个足迹 , 都学习了2D偏移量 , 以便将足迹引导到最适合训练的位置 。偏移量学习部分也是卷积层 , 其输出通道数是输入通道数的两倍 , 因为每个像素都有两个偏移量坐标 。基于这种方法 , 内核可以适应局部特征变化 , 这对于语义特征学习是有效的 。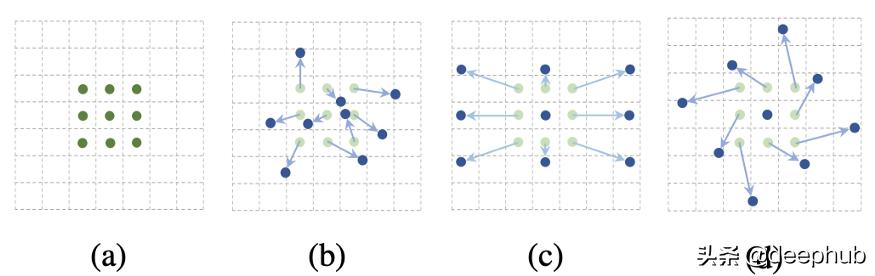 文章插图
文章插图
这是补偿学习的例证 。a是传统的卷积 , 其中内核足迹完全不动 。b , c和d说明了足迹移动 。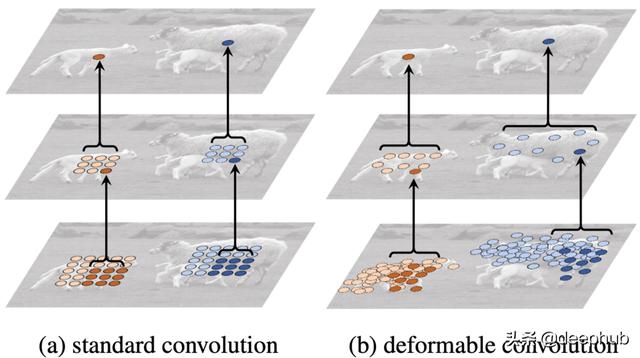 文章插图
文章插图
在可变形的卷积中 , 深像素的接收场集中到相应的物体 。如上所示 , 在中 , 深蓝色像素(上方)属于大绵羊 。但是 , 其矩形接受区域(底部)在左底部包含小绵羊 , 这可能会给诸如实例分割之类的任务带来歧义 。在b中 , 感受野变形并集中在大羊身上 , 避免了歧义 。
了解可变形卷积中的偏移如上所述 , 偏移量有利于局部特征的核适应和接受场的集中 。 顾名思义 , 偏移量用于使内核足迹局部变形 , 从而最终使接收场整体变形 。
现在棘手的部分来了:由于可以学习偏移以适应当前图片中的对象 , 因此我们可以将当前图片中的对象适应到另一张图片中的对象 , 并在它们之间提供偏移吗?
让我们具体说吧 。 假设我们有一个视频 , 其中每个帧都与其相邻帧相似 。 然后我们稀疏地选择一些帧 , 并在像素级别上对其进行标记 , 例如语义分割或关键点等 。 由于这些像素级别的标注会需要昂贵成本 , 是否可以使用未标记的相邻帧来提高泛化的准确性?具体地说 , 通过一种使未标记帧的特征图变形为其相邻标记帧的方法 , 以补偿标记帧α中的丢失信息 。
学习稀疏标记视频的时间姿态估计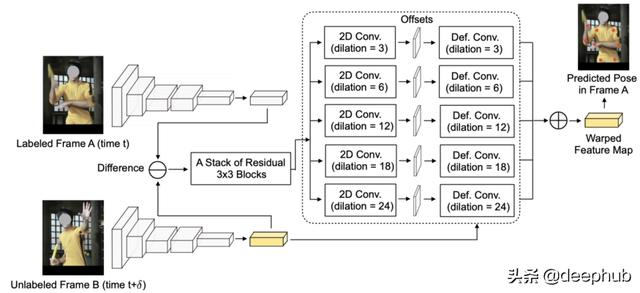 文章插图
文章插图
这项研究是对上面讨论的一个很好的解决方案 。 由于标注成本很昂贵 , 因此视频中仅标记了少量帧 。 然而 , 标记帧图像中的固有问题(如遮挡 , 模糊等)阻碍了模型训练的准确性和效率 。 为了解决这个问题 , 作者使用可变形卷积将未标记帧的特征图变形为其相邻标记帧的特征图 , 以修补上述固有问题 。 偏移量就是带标记的帧和未带标记的相邻帧之间优化后的特征差 。 利用多分辨率特征金字塔构造可变形部分 , 并采用不同的扩张方法 。 该方法的优点在于 , 我们可以利用相邻的未标记帧来增强已标记帧的特征学习 , 因为相邻帧相似 , 我们无需对视频的每一帧进行标记 。 这种可变形的方法 , 也被作者称为"扭曲"方法 , 比其他一些视频学习方法 , 如光流或3D卷积等 , 更便宜和更有效 。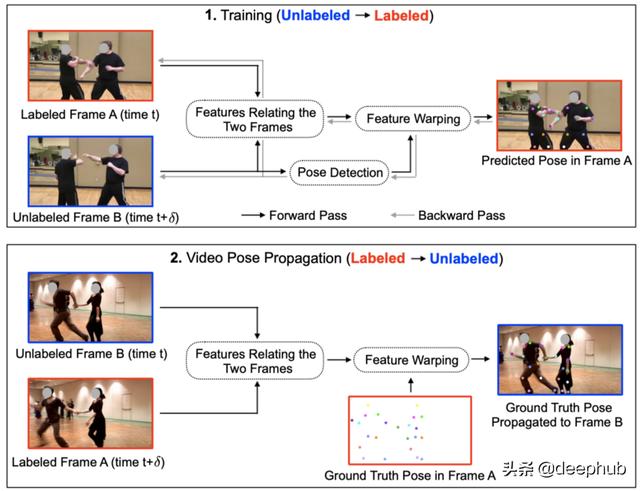 文章插图
文章插图
如上所示 , 在训练过程中 , 未标记帧B的特征图会扭曲为其相邻的标记帧A的特征图 。 在推理过程中 , 可以使用训练后的翘曲模型传播帧A的正确的标注值(ground truth) , 以获取A的关键点估计 。此外 , 可以合并更多相邻帧 , 并合并其特征图 , 以提高关键点估计的准确性 。
具有遮罩传播的视频实例分割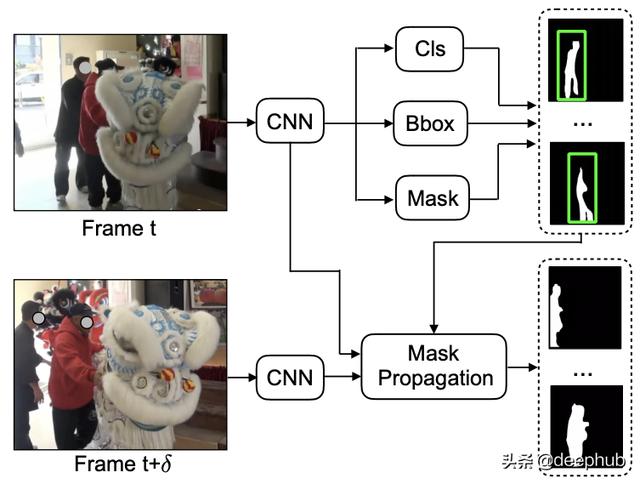 文章插图
文章插图
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 行业|现在行业内客服托管费用是怎么算的
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 看过明年的iPhone之后,现在下手的都哭了