可变形卷积在视频学习中的应用:利用带有稀疏标记数据的视频帧( 二 )
作者还通过在现有的Mask-RCNN模型中附加一个掩码传播头来提出用于实例分割的掩码传播 , 其中可以将时间t的预测实例分割传播到其相邻帧t +δ 。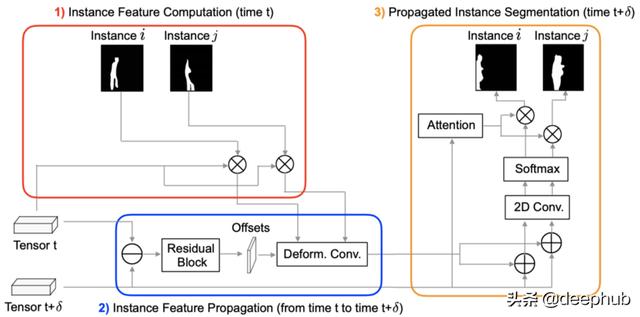 文章插图
文章插图
【可变形卷积在视频学习中的应用:利用带有稀疏标记数据的视频帧】该网络结构类似于上面讨论的姿势估计网络 , 但有点复杂 。它包括三个部分:1)帧t的实例分割预测; 2)帧t与t +δ之间的偏移优化和分割变形; 3)特征图聚合 , 用于最终预测帧t +δ处的实例分割 。在这里 , 作者还使用乘法层来滤除噪声 , 仅关注对象实例存在的特征 。通过相邻帧的特征聚合 , 可以缓解遮挡 , 模糊的问题 。
结论将可变形卷积引入到具有给定偏移量的视频学习任务中 , 通过实现标签传播和特征聚合来提高模型性能 。 与传统的一帧一标记学习方法相比 , 提出了利用相邻帧的特征映射来增强表示学习的多帧一标记学习方法 。 这样 , 模型就可以通过训练看到被相邻帧的其他眼睛遮挡或模糊的部分 。
引用Deformable Convolutional Networks, 2017 (arxiv.org/1703.06211)
Learning Temporal Pose Estimation from Sparsely-Labeled Videos, (2019 arxiv.org/1906.04016)
Classifying, Segmenting, and Tracking Object Instances in Video with Mask Propagation, 2020 (arxiv.org/1912.04573)
作者:Shuchen Du
deephub翻译组
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 行业|现在行业内客服托管费用是怎么算的
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 看过明年的iPhone之后,现在下手的都哭了