时序数据异常检测做到这种段位,还怕什么告警风暴( 三 )
比如对于CPU Load曲线 , 往往波动剧烈 , 如果设置固定阈值 , 瞬时的高涨会经常产生误告 , SRE和研发人员需要不断调整阈值和检测窗口来减少误告 。
当前 , 通过Radar(美团内部系统)监控系统提供的动态阈值策略 , 然后参考历史数据可以在一定程度上避免这一情况 。 如果系统能够提前预判该时序数据类型 , 给出合理的策略配置建议 , 就可以提升告警配置体验 , 甚至做到自动化配置 。
而且在异常检测中 , 时序数据分类通常也是智能化的第一步 , 只有实现智能化分类 , 才能自动适配相应的策略 。
目前 , 时间序列分类主要有两种方法 , 无监督的聚类和基于监督学习的分类 。
Yading[4]是一种大规模的时序聚类方法 , 它采用PAA降维和基于密度聚类的方法实现快速聚类 , 有别于K-Means和K-Shape[5]采用互相关统计方法 , 它基于互相关的特性提出了一个新颖的计算簇心的方法 , 且在计算距离时尽量保留了时间序列的形状 。
对KPI进行聚类 , 也分为两种方法 , 一种是必须提前指定类别数目(如K-Means、K-Shape等)的方法 , 另一种是无需指定类别数目(如DBSCAN等) , 无需指定类别数目的聚类方法 , 类别划分的结果受模型参数和样本影响 。 至于监督学习的分类方法 , 经典的算法主要包括Logistics、SVM等 。
1)分类器选择
根据当前监控系统中时序数据特点 , 以及业内的实践 , 我们将所有指标抽象成三种类别:周期型、平稳型和无规律波动型[6] 。
而我们主要经历了以下三个阶段的探索:
- 单分类器分类:本文训练了SVM、DBSCAN、One-Class-SVM(S3VM)三种分类器 , 平均分类准确率达到80%左右 , 但无规律波动型指标的分类准确率只有50%左右 , 不满足使用要求;
- 多弱分类器集成决策分类:参考集成学习相关原理 , 通过对SVM、DBSCAN、S3VM三种分类器集成投票 , 提高分类准确率 , 最终分类准确率提高7个百分点 , 达到87%;
- 卷积神经网络分类:参考对Human Activity Recognition(HAR)进行分类的实践[7] , 我们用CNN(卷积神经网络)实现了一个分类器 , 该分类器在时序数据分类上表现优秀 , 准确率能达到95%以上 。 CNN在训练中会逐层学习时序数据的特征 , 不需要成本昂贵的特征工程 , 大大减少了特征设计的工作量 。
我们选择CNN分类器进行时序数据分类 , 分类过程如下图6所示 , 主要步骤如下:
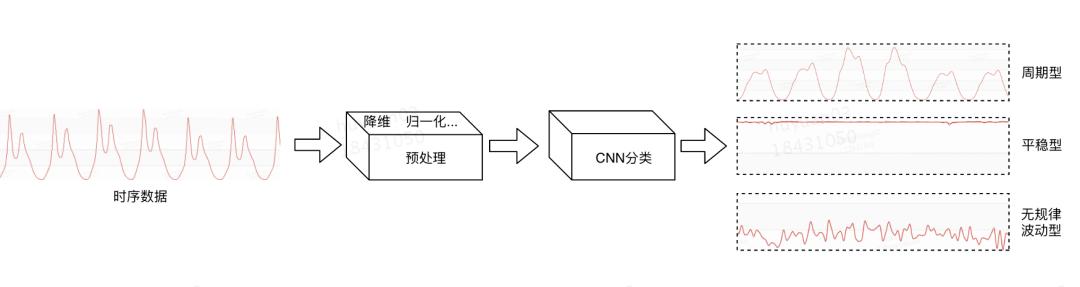 文章插图
文章插图图6 时序数据分类处理流程
- 缺失值填充:时序数据存在少量数据丢失或者部分时段无数据等现象 , 因此在分类前先对数据先进行缺失值填充;
- 标准化:本文采用方差标准化对时序数据进行处理;
- 降维处理:按分钟粒度的话 , 一天有1440个点 , 为了减少计算量 , 我们进行降维处理到144个点 。
- PCA、PAA、SAX等一系列方法是常用的降维方法 , 此类方法在降低数据维度的同时还能最大程度地保持数据的特征 。 通过比较 , PAA在降到同样的维度(144维)时 , 还能保留更多的时序数据细节 , 具体对比如下图7所示;
- 模型训练:使用标注的样本数据 , 在CNN分类器中进行训练 , 最终输出分类模型 。
 文章插图
文章插图图7 PAA、SAX降维方法对比
3、周期型指标异常检测
1)异常检测方法
基于上述时序数据分类工作 , 本文能够相对准确地将时序数据分为周期型、平稳型和无规律波动型三类 。
在这三种类型中 , 周期型最为常见 , 占比30%以上 , 并且包含了大多数业务指标 , 业务请求量、订单数等核心指标均为周期型 , 所以本文优先选择周期型指标进行自动异常检测的探索 。
对于大量的时序数据 , 通过规则进行判断已经不能满足 , 需要通用的解决方案 , 能对所有周期型指标进行异常检测 , 而非一个指标一套完全独立的策略 , 机器学习方法是首选 。
论文Opprentice[8]和腾讯开源的Metis[9]采用监督学习的方式进行异常检测 , 其做法如下:
首先 , 进行样本标注得到样本数据集 , 然后进行特征提取得到特征数据集 , 使用特征数据集在指定的学习系统上进行训练 , 得到异常分类模型 , 最后把模型用于实时检测 。
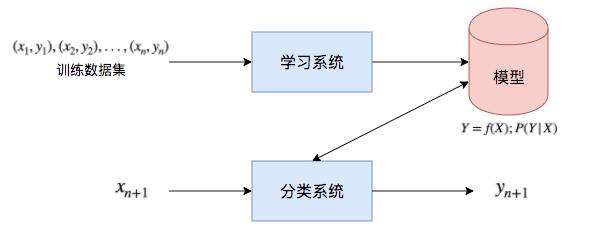 文章插图
文章插图
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元
- Veeam|Veeam让企业数据拥有“第二次生命”