半监督学习入门基础(二):最基础的3个概念
作者:Neeraj varshney
编译:ronghuaiyang
导读
今天给大家介绍半监督学习中的3个最基础的概念:一致性正则化 , 熵最小化和伪标签 , 并介绍了两个经典的半监督学习方法 。
半监督学习 (SSL) 是一种非常有趣的方法 , 用来解决机器学习中缺少标签数据的问题 。 SSL利用未标记的数据和标记的数据集来学习任务 。 SSL的目标是得到比单独使用标记数据训练的监督学习模型更好的结果 。 这是关于半监督学习的系列文章的第2部分 , 详细介绍了一些基本的SSL技术 。
一致性正则化 , 熵最小化 , 伪标签SSL的流行方法是在训练期间往典型的监督学习中添加一个新的损失项 。 通常使用三个概念来实现半监督学习 , 即一致性正则化、熵最小化和伪标签 。 在进一步讨论之前 , 让我们先理解这些概念 。
一致性正则化 强制数据点的实际扰动不应显著改变预测器的输出 。 简单地说 , 模型应该为输入及其实际扰动变量给出一致的输出 。 我们人类对于小的干扰是相当鲁棒的 。 例如 , 给图像添加小的噪声(例如改变一些像素值)对我们来说是察觉不到的 。 机器学习模型也应该对这种扰动具有鲁棒性 。 这通常通过最小化对原始输入的预测与对该输入的扰动版本的预测之间的差异来实现 。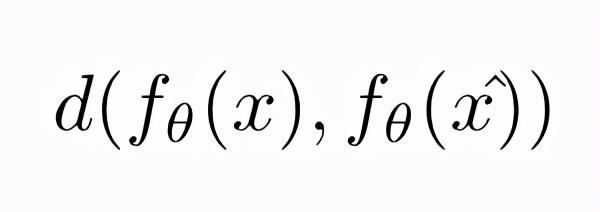 文章插图
文章插图
模型对输入x及其扰动x^的一致性度量
d(.,.) 可以是均方误差或KL散度或任何其他距离度量 。
一致性正则化是利用未标记数据找到数据集所在的平滑流形的一种方法 。 这种方法的例子包括π模型、Temporal Ensembling , Mean Teacher , Virtual Adversarial Training等 。
熵最小化 鼓励对未标记数据进行更有信心的预测 , 即预测应该具有低熵 , 而与ground truth无关(因为ground truth对于未标记数据是未知的) 。 让我们从数学上理解下这个 。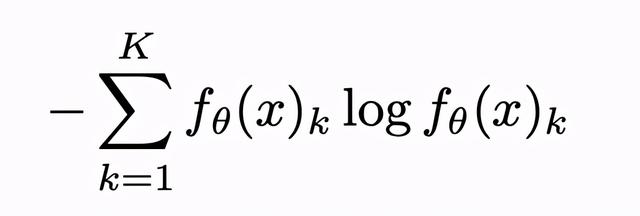 文章插图
文章插图
熵的计算
这里 , K是类别的数量 , fθ(x)k是模型对x预测是否属于类别k的置信度 。
此外 , 输入示例中所有类的置信度之和应该为1 。 这意味着 , 当某个类的预测值接近1 , 而其他所有类的预测值接近0时 , 熵将最小化 。 因此 , 这个目标鼓励模型给出高可信度的预测 。
理想情况下 , 熵的最小化将阻止决策边界通过附近的数据点 , 否则它将被迫产生一个低可信的预测 。 请参阅下图以更好地理解此概念 。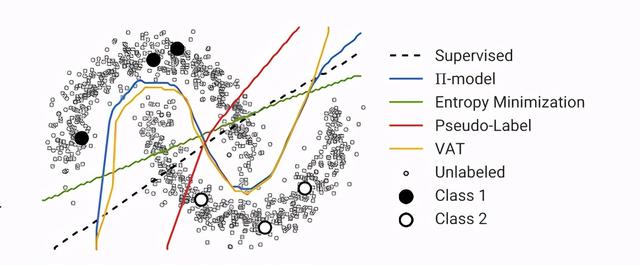 文章插图
文章插图
由不同的半监督学习方法生成的决策边界
伪标签 是实现半监督学习最简单的方法 。 一个模型一开始在有标记的数据集上进行训练 , 然后用来对没有标记的数据进行预测 。 它从未标记的数据集中选择那些具有高置信度(高于预定义的阈值)的样本 , 并将其预测视为伪标签 。 然后将这个伪标签数据集添加到标记数据集 , 然后在扩展的标记数据集上再次训练模型 。 这些步骤可以执行多次 。 这和自训练很相关 。
在现实中视觉和语言上扰动的例子视觉:
翻转 , 旋转 , 裁剪 , 镜像等是图像常用的扰动 。 文章插图
文章插图
语言
反向翻译是语言中最常见的扰动方式 。 在这里 , 输入被翻译成不同的语言 , 然后再翻译成相同的语言 。 这样就获得了具有相同语义属性的新输入 。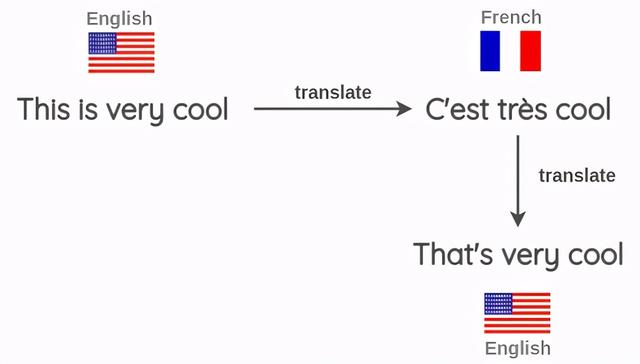 文章插图
文章插图
NLP中的反向翻译
半监督学习方法π model:
这里的目标是一致性正则化 。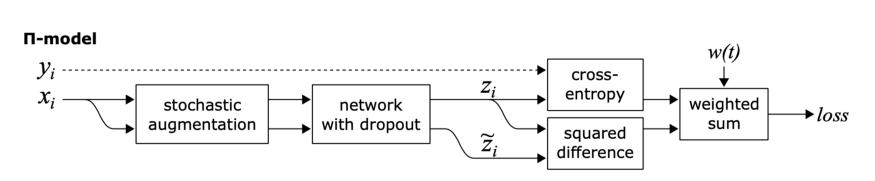 文章插图
文章插图
π模型鼓励模型对两个相同的输入(即同一个输入的两个扰动变量)输出之间的一致性 。
π模型有几个缺点 , 首先 , 训练计算量大 , 因为每个epoch中单个输入需要送到网络中两次 。 第二 , 训练目标zi?是有噪声的 。
Temporal Ensembling:
这个方法的目标也是一致性正则化 , 但是实现方法有点不一样 。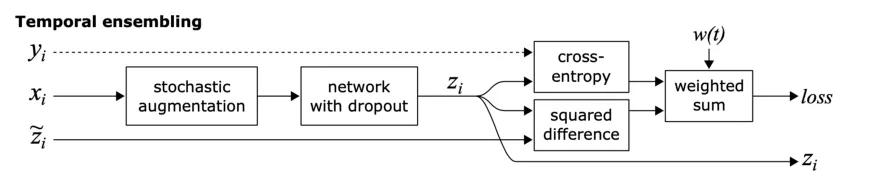 文章插图
文章插图
众所周知 , 与单一模型相比 , 模型集成通常能提供更好的预测 。 通过在训练期间使用单个模型在不同训练时期的输出来形成集成预测 , 这一思想得到了扩展 。
简单来说 , 不是比较模型的相同输入的两个扰动的预测(如π模型) , 模型的预测与之前的epoch中模型对该输入的预测的加权平均进行比较 。
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局
- 关华为P50Pro|华为P50Pro概念图:半圆形6摄,看完iPhone12劝你暂时别买
- 联盟|天津半导体集成电路人才联盟成立
- 美国半导体行业协会|中国光伏新增装机量领跑全球
- 科技|联咏科技将从明年下半年开始为iPad提供LCD驱动芯片
- 换头像|从不换“头像”的人,多半都是这几张原因,你是哪一种?
- 华为P40Pro|发布半年跌至6099,10倍光学变焦加持,这幸福来得太突然
- 用于|用于半监督学习的图随机神经网络
- 时代|5G时代“半斤机”当道,vivo S7e只改了这几点就变得与众不同
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价