机器学习中处理缺失值的9种方法
数据科学就是关于数据的 。 它是任何数据科学或机器学习项目的关键 。 在大多数情况下 , 当我们从不同的资源收集数据或从某处下载数据时 , 几乎有95%的可能性我们的数据中包含缺失的值 。 我们不能对包含缺失值的数据进行分析或训练机器学习模型 。 这就是为什么我们90%的时间都花在数据预处理上的主要原因 。 我们可以使用许多技术来处理丢失的数据 。 在这个文章中 , 我将分享处理数据缺失的9种方法 , 但首先让我们看看为什么会出现数据缺失以及有多少类型的数据缺失 。 文章插图
文章插图
不同类型的缺失值缺失的值主要有三种类型 。
· 完全随机缺失(MCAR):当数据为MCAR时 , 如果所有观测的缺失概率都相同 , 则一个变量完全随机缺失 , 这意味着数据缺失与数据集中任何其他观察到的或缺失的值完全没有关系 。 换句话说 , 那些缺失的数据点是数据集的一个随机子集 。
· 丢失数据不是随机的(MNAR):顾名思义 , 丢失的数据和数据集中的任何其他值之间存在某种关系 。
· 随机丢失(MAR):这意味着数据点丢失的倾向与丢失的数据无关 , 但与数据集中其他观察到的数据有关 。
数据集中缺少值的原因有很多 。 例如,在数据集的身高和年龄,会有更多年龄列中缺失值,因为女孩通常隐藏他们的年龄相同的如果我们准备工资的数据和经验,我们将有更多的薪水中的遗漏值因为大多数男人不喜欢分享他们的薪水 。 在更大的情况下 , 比如为人口、疾病、事故死亡者准备数据 , 纳税人记录通常人们会犹豫是否记下信息 , 并隐藏真实的数字 。 即使您从第三方资源下载数据 , 仍然有可能由于下载时文件损坏而丢失值 。 无论原因是什么 , 我们的数据集中丢失了值 , 我们需要处理它们 。 让我们看看处理缺失值的9种方法 。
这里使用的也是经典的泰坦尼克的数据集
让我们从加载数据集并导入所有库开始 。
import pandas as pddf=pd.read_csv("data/titanic.csv",usecols=['Age','Cabin','Survived'])df.isnull().mean()df.dtypes运行上述代码块后 , 您将看到Age、Cabin和装载装载包含空值 。 Age包含所有整数值 , 而Cabin包含所有分类值 。
1、均值、中值、众数替换在这种技术中 , 我们将null值替换为列中所有值的均值/中值或众数 。
平均值(mean):所有值的平均值
def impute_nan(df,column,mean):df[column+'_mean']=df[column].fillna(mean) ##NaN -> meanimpute_nan(df,'Age',df.Age.mean()) ##mean of Age(29.69)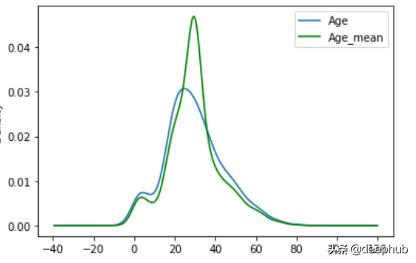 文章插图
文章插图
中值(median):所有值的中心值
def impute_nan(df,column,median):df[column+'_mean']=df[column].fillna(median)impute_nan(df,'Age',df.Age.median()) ##median of Age(28.0)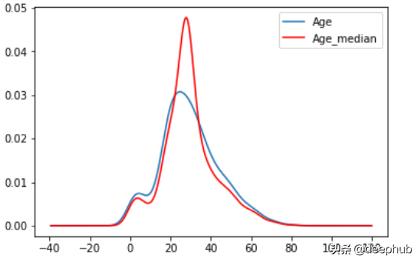 文章插图
文章插图
众数(mode):最常见的值
def impute_nan(df,column,mode):df[column+'_mean']=df[column].fillna(mode)impute_nan(df,'Age',df.Age.mode()) ##mode of Age(24.0)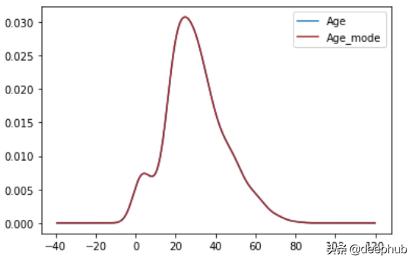 文章插图
文章插图
优点
· 易于实现(对异常值健壮)
· 获得完整数据集的更快方法
缺点
· 原始方差的变化或失真
· 影响相关性
· 对于分类变量 , 我们需要众数 。 平均值和中位数都不行 。
2、随机样本估算在这种技术中 , 我们用dataframe中的随机样本替换所有nan值 。 它被用来输入数值数据 。 我们使用sample()对数据进行采样 。 在这里 , 我们首先取一个数据样本来填充NaN值 。 然后更改索引 , 并将其替换为与NaN值相同的索引 , 最后将所有NaN值替换为一个随机样本 。
优点
· 容易实现
· 方差失真更小
缺点
· 我们不能把它应用于每一种情况
【机器学习中处理缺失值的9种方法】用随机样本注入替换年龄列NaN值
def impute_nan(df,variable):df[variable+"_random"]=df[variable]##It will have the random sample to fill the narandom_sample=df[variable].dropna().sample(df[variable].isnull().sum(),random_state=0)##pandas need to have same index in order to merge the datasetrandom_sample.index=df[df[variable].isnull()].index #replace random_sample index with NaN values index#replace where NaN are theredf.loc[df[variable].isnull(),variable+'_random']=random_samplecol=variable+"_random"df = df.drop(col,axis=1)impute_nan(df,"Age")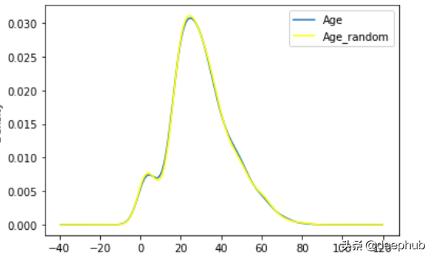 文章插图
文章插图
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 中国|浅谈5G移动通信技术的前世和今生
- 操盘|中兴统一操盘中兴、努比亚、红魔三大品牌
- Blade|售价2798元 中兴Blade 20 Pro 5G手机发布 骁龙765G配四摄
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- 垫底|5G用户突破2亿:联通垫底,电信月增700万,中国移动有多少?
- 计费|5G是如何计费的?