机器学习中处理缺失值的9种方法( 二 )
3、用新特性获取NAN值这种技术在数据不是完全随机丢失的情况下最有效 。 在这里 , 我们在数据集中添加一个新列 , 并将所有NaN值替换为1 。
优点
· 容易实现
· 获取了了NaN值的重要性
缺点
· 创建额外的特性(维度诅咒)
import numpy as npdf['age_nan']=np.where(df['Age'].isnull(),1,0)## It will create one new column that contains value 1 in the rows where Age value is NaN, otherwise 0. 4、End of Distribution在这种技术中 , 我们用第3个标准偏差值(3rd standard deviation)替换NaN值 。 它还用于从数据集中删除所有异常值 。 首先 , 我们使用std()计算第3个标准偏差 , 然后用该值代替NaN 。 优点
· 容易实现 。
· 抓住了缺失值的重要性 , 如果有的话 。
缺点
· 使变量的原始分布失真 。
· 如果NAN的数量很大 。 它将掩盖分布中真正的异常值 。
· 如果NAN的数量较小 , 则替换后的NAN可以被认为是一个离群值 , 并在后续的特征工程中进行预处理 。
def impute_nan(df,variable,median,extreme):df[variable+"_end_distribution"]=df[variable].fillna(extreme)extreme=df.Age.mean()+3*df.Age.std() ##73.27--> 3rd std deviation impute_nan(df,'Age',df.Age.median(),extreme)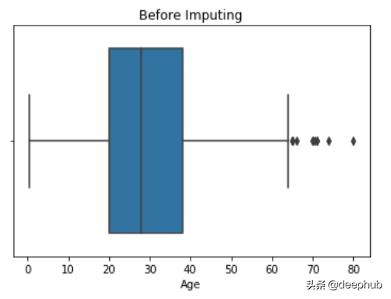 文章插图
文章插图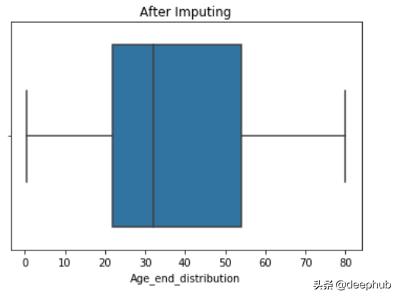 文章插图
文章插图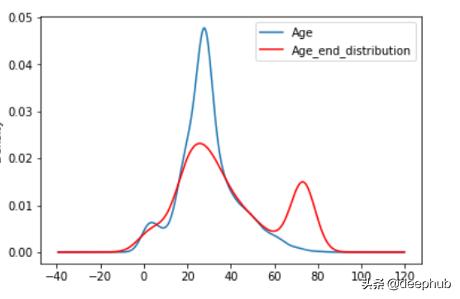 文章插图
文章插图
5、任意值替换在这种技术中 , 我们将NaN值替换为任意值 。 任意值不应该更频繁地出现在数据集中 。 通常 , 我们选择最小离群值或最后离群值作为任意值 。
优点
· 容易实现
· 获取了缺失值的重要性 , 如果有的话
缺点
· 必须手动确定值 。
def impute_nan(df,var):df[var+'_zero']=df[var].fillna(0) #Filling with 0(least outlier)df[var+'_hundred']=df[var].fillna(100) #Filling with 100(last)impute_nan(df,'Age')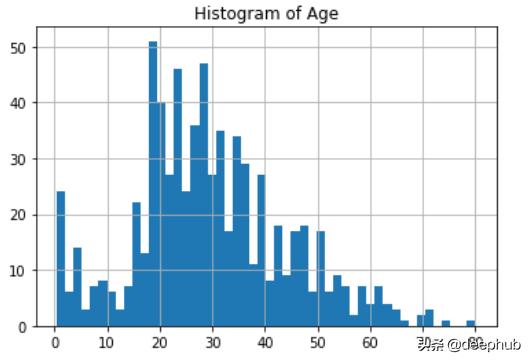 文章插图
文章插图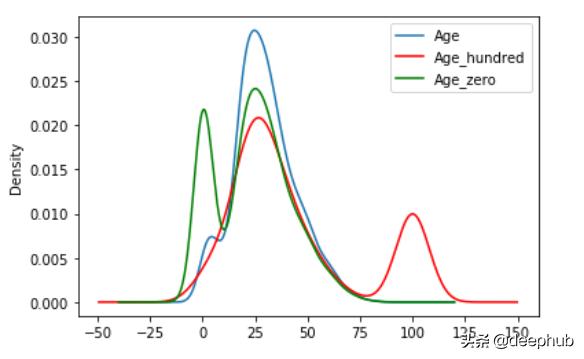 文章插图
文章插图
6、频繁类别归责该技术用于填充分类数据中的缺失值 。 在这里 , 我们用最常见的标签替换NaN值 。 首先 , 我们找到最常见的标签 , 然后用它替换NaN 。
优点
· 容易实现
缺点
· 由于我们使用的是更频繁的标签 , 所以如果有很多NaN值 , 它可能会以一种过度表示的方式使用它们 。
· 它扭曲了最常见的标签之间的关系 。
def impute_nan(df,variable):most_frequent_category=df[variable].mode()[0] ##Most Frequentdf[variable].fillna(most_frequent_category,inplace=True)for feature in ['Cabin']:##List of Categorical Featuresimpute_nan(df,feature)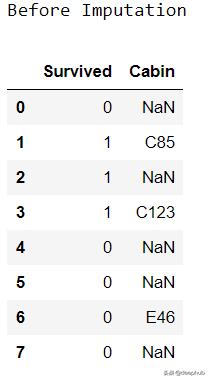 文章插图
文章插图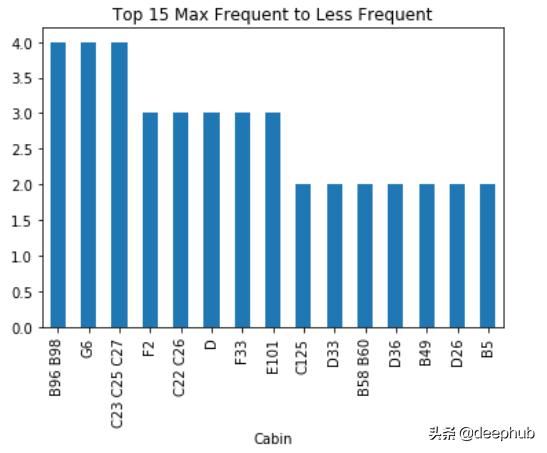 文章插图
文章插图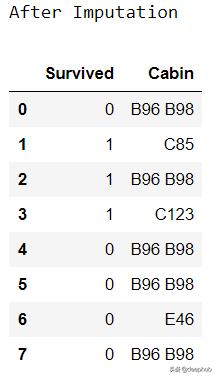 文章插图
文章插图
7、nan值视为一个新的分类在这种技术中 , 我们只需用一个新的类别(如Missing)替换所有NaN值 。
df['Cabin']=df['Cabin'].fillna('Missing') ##NaN -> Missing8、使用KNN填充在这项技术中 , 我们使用sklearn创建一个KNN imputer模型 , 然后我们将该模型与我们的数据进行拟合 , 并预测NaN值 。 它被用来计算数值 。 这是一个5步的过程 。
· 创建列列表(整数、浮点)
· 输入估算值 , 确定邻居 。
· 根据数据拟合估算 。
· 转换的数据
· 使用转换后的数据创建一个新的数据框架 。
优点
· 容易实现
· 结果一般情况下会最好
缺点
· 只适用于数值数据
我们在上篇文章中已经有过详细的介绍 , 这里就不细说了
在python中使用KNN算法处理缺失的数据
9、删除所有NaN值它是最容易使用和实现的技术之一 。 只有当NaN值小于10%时 , 我们才应该使用这种技术 。
优点:
1. 容易实现
1. 快速处理
缺点:
1. 造成大量的数据丢失
df.dropna(inplace=True) ##Drop all the rows that contains NaN总结还有更多处理丢失值的其他技术 。 我们的目标是找到最适合我们的问题的技术 , 然后实施它 。 处理丢失的值总是一个更好的主意 , 但有时我们不得不删除所有的值 。 它基本上取决于数据的类型和数量 。
最有 , 所有的代码在这里都能找到:
作者:Abhay Parashar
deephub翻译组
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 中国|浅谈5G移动通信技术的前世和今生
- 操盘|中兴统一操盘中兴、努比亚、红魔三大品牌
- Blade|售价2798元 中兴Blade 20 Pro 5G手机发布 骁龙765G配四摄
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- 垫底|5G用户突破2亿:联通垫底,电信月增700万,中国移动有多少?
- 计费|5G是如何计费的?