通过深层神经网络生成音乐
深度学习改善了我们生活的许多方面 , 无论是明显的还是微妙的 。 深度学习在电影推荐系统、垃圾邮件检测和计算机视觉等过程中起着关键作用 。
尽管围绕深度学习作为黑匣子和训练难度的讨论仍在进行 , 但在医学、虚拟助理和电子商务等众多领域都存在着巨大的潜力 。
在艺术和技术的交叉点 , 深度学习可以发挥作用 。 为了进一步探讨这一想法 , 在本文中 , 我们将研究通过深度学习过程生成机器学习音乐的过程 , 许多人认为这一领域超出了机器的范围(也是另一个激烈辩论的有趣领域!) 。
目录
- 机器学习模型的音乐表现
- 音乐数据集
- 数据处理
- 模型选择
- RNN
- 时间分布全连接层
- 状态
- Dropout层
- Softmax层
- 优化器
- 音乐生成
- 摘要
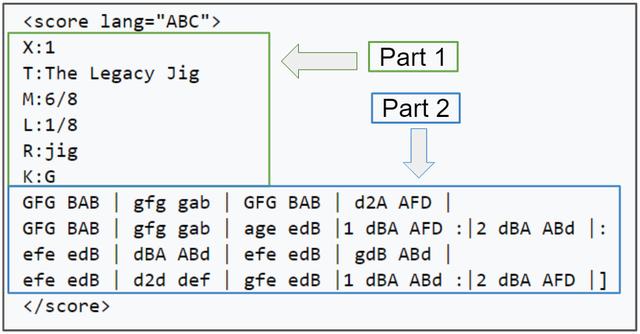
这种形式的符号开始时是一种ASCII字符集代码 , 以便于在线音乐共享 , 为软件开发人员添加了一种新的简单的语言 , 便于使用 。 以下是ABC音乐符号 。
 文章插图
文章插图乐谱记谱法第1部分中的行显示一个字母后跟一个冒号 。 这些表示曲调的各个方面 , 例如当文件中有多个曲调时的索引(X:)、标题(T:)、时间签名(M:)、默认音符长度(L:)、曲调类型(R:)和键(K:) 。 键名称后面代表旋律 。
音乐数据集【通过深层神经网络生成音乐】在本文中 , 我们将使用诺丁汉音乐数据库ABC版上提供的开源数据 。 它包含了1000多首民谣曲调 , 其中绝大多数已被转换成ABC符号:
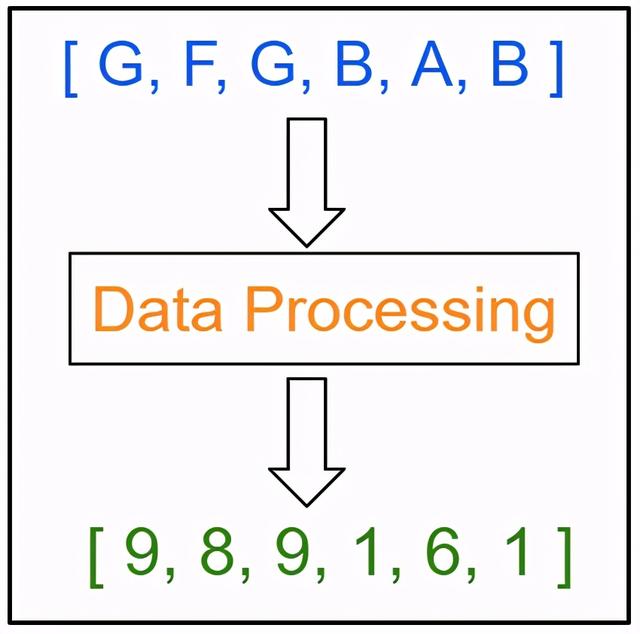
数据处理数据当前是基于字符的分类格式 。 在数据处理阶段 , 我们需要将数据转换成基于整数的数值格式 , 为神经网络的工作做好准备 。
 文章插图
文章插图这里每个字符都映射到一个唯一的整数 。 这可以通过使用一行代码来实现 。 “text”变量是输入数据 。
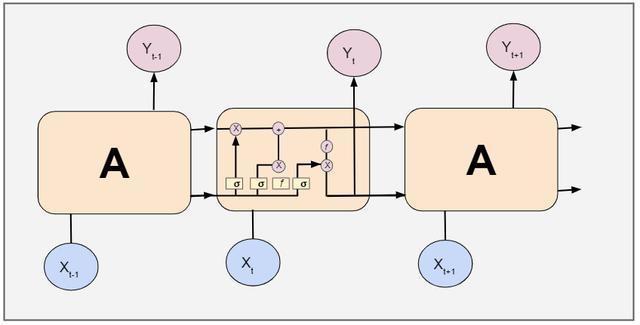
char_to_idx = { ch: i for (i, ch) in enumerate(sorted(list(set(text)))) }为了训练模型 , 我们使用vocab将整个文本数据转换成数字格式 。T = np.asarray([char_to_idx[c] for c in text], dtype=np.int32)机器学习音乐生成的模型选择在传统的机器学习模型中 , 我们无法存储模型的前一阶段 。 然而 , 我们可以用循环神经网络(通常称为RNN)来存储之前的阶段 。RNN有一个重复模块 , 它从前一级获取输入 , 并将其输出作为下一级的输入 。 然而 , RNN只能保留最近阶段的信息 , 因此我们的网络需要更多的内存来学习长期依赖关系 。 这就是长短期记忆网络(LSTMs) 。
LSTMs是RNNs的一个特例 , 具有与RNNs相同的链状结构 , 但有不同的重复模块结构 。
 文章插图
文章插图这里使用RNN是因为:
- 数据的长度不需要固定 。 对于每一个输入 , 数据长度可能会有所不同 。
- 可以存储序列 。
- 可以使用输入和输出序列长度的各种组合 。
 文章插图
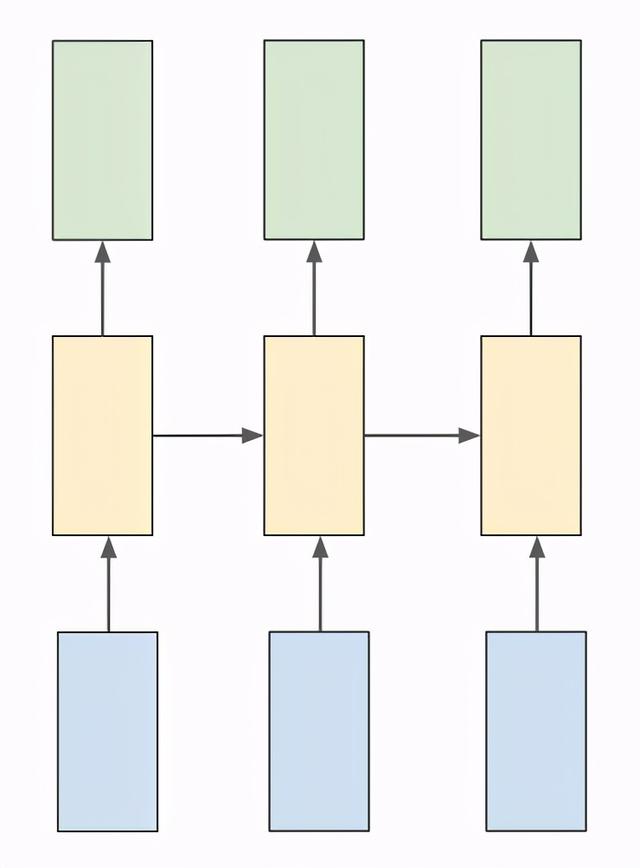
文章插图RNN由于我们需要在每个时间戳上生成输出 , 所以我们将使用许多RNN 。 为了实现多个RNN , 我们需要将参数“return_sequences”设置为true , 以便在每个时间戳上生成每个字符 。 通过查看下面的图5 , 你可以更好地理解它 。
 文章插图
文章插图在上图中 , 蓝色单位是输入单位 , 黄色单位是隐藏单位 , 绿色单位是输出单位 。 这是许多RNN的简单概述 。 为了更详细地了解RNN序列 , 这里有一个有用的资源:
时间分布全连接层为了处理每个时间戳的输出 , 我们创建了一个时间分布的全连接层 。 为了实现这一点 , 我们在每个时间戳生成的输出之上创建了一个时间分布全连接层 。
状态通过将参数stateful设置为true , 批处理的输出将作为输入传递给下一批 。 在组合了所有特征之后 , 我们的模型将如下面图6所示的概述 。
- 操作|[LIVE On]黄敏贤和郑多彬充满心碎的下午:机器操作每次都不能通过测试
- 五金|我院承担的顺德区家居五金国际质量比对项目顺利通过成果验收
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 用于|用于半监督学习的图随机神经网络
- Reno5|通过HDR10+认证!OPPO Reno5惊喜果然不止这几点
- 方式|富维薄膜计划通过公开招标方式出售Dornier生产线
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 发布|三星Smart Tag跟踪器已通过认证 或于明年1月发布
- 商家|今年双十二 近900万实体商家通过支付宝发券上百亿
- Pro|三星Galaxy Buds Pro通过认证 或与三星S21一同发布