通过深层神经网络生成音乐( 二 )
 文章插图
文章插图
模型体系结构的代码片段如下:
model = Sequential()model.add(Embedding(vocab_size, 512, batch_input_shape=(BATCH_SIZE, SEQ_LENGTH)))for i in range(3):model.add(LSTM(256, return_sequences=True, stateful=True))model.add(Dropout(0.2))model.add(TimeDistributed(Dense(vocab_size)))model.add(Activation('softmax'))model.summary()model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])我强烈建议你使用层来提高性能 。
Dropout层Dropout层是一种正则化技术 , 在训练过程中 , 每次更新时将输入单元的一小部分归零 , 以防止过拟合 。
Softmax层音乐的生成是一个多类分类问题 , 每个类都是输入数据中唯一的字符 。 因此 , 我们在我们的模型上使用了一个softmax层 , 并将分类交叉熵作为一个损失函数 。
这一层给出了每个类的概率 。 从概率列表中 , 我们选择概率最大的一个 。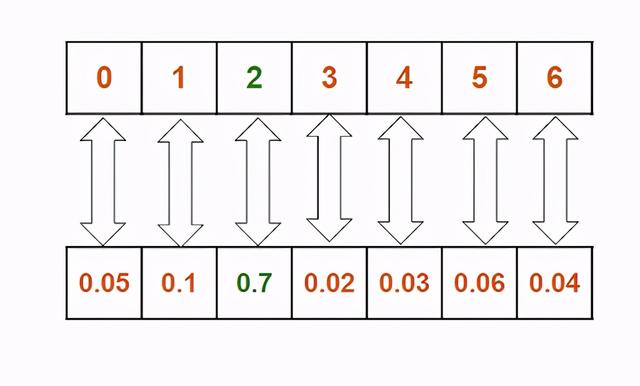 文章插图
文章插图
优化器为了优化我们的模型 , 我们使用自适应矩估计 , 也称为Adam , 因为它是RNN的一个很好的选择 。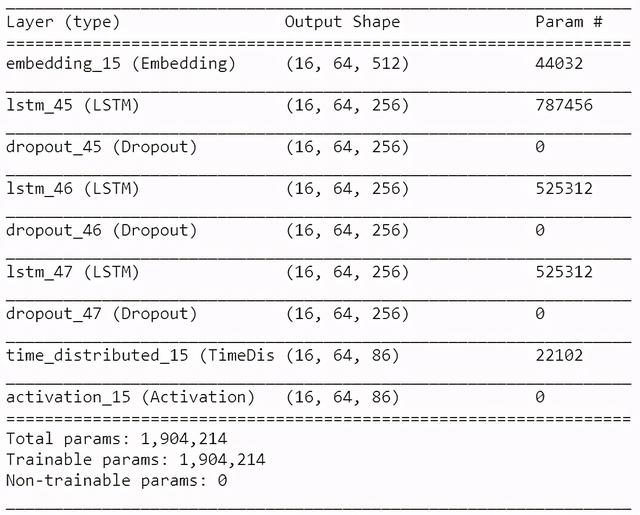 文章插图
文章插图
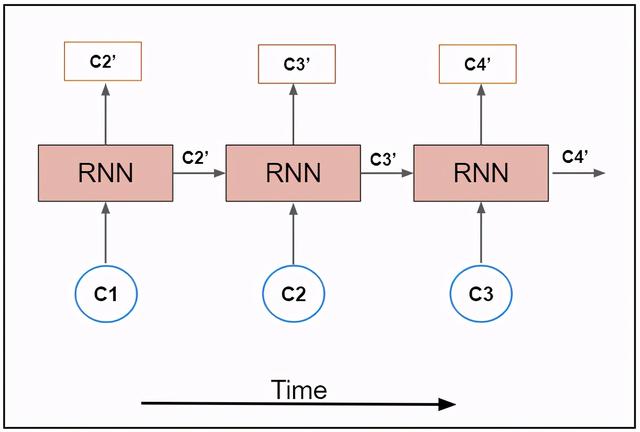
生成音乐到目前为止 , 我们创建了一个RNN模型 , 并根据我们的输入数据对其进行训练 。 该模型在训练阶段学习输入数据的模式 。 我们把这个模型称为“训练模型” 。
在训练模型中使用的输入大小是批大小 。 对于通过机器学习产生的音乐来说 , 输入大小是单个字符 。 所以我们创建了一个新的模型 , 它和""训练模型""相似 , 但是输入一个字符的大小是(1,1) 。 在这个新模型中 , 我们从训练模型中加载权重来复制训练模型的特征 。
model2 = Sequential()model2.add(Embedding(vocab_size, 512, batch_input_shape=(1,1)))for i in range(3):model2.add(LSTM(256, return_sequences=True, stateful=True))model2.add(Dropout(0.2))model2.add(TimeDistributed(Dense(vocab_size)))model2.add(Activation(‘softmax’))我们将训练好的模型的权重加载到新模型中 。 这可以通过使用一行代码来实现 。
model2.load_weights(os.path.join(MODEL_DIR,‘weights.100.h5’.format(epoch)))model2.summary()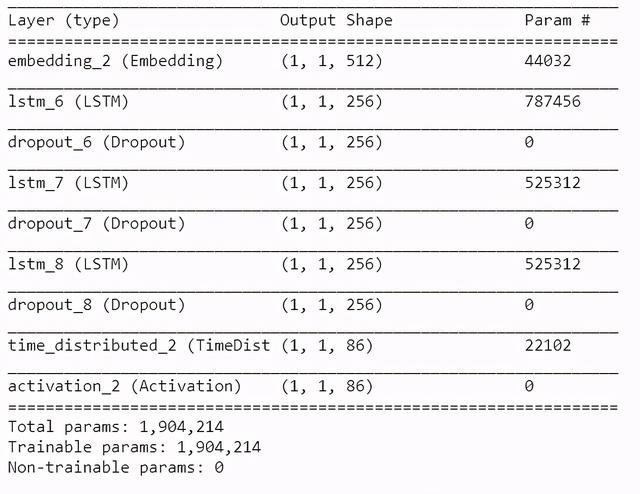 文章插图
文章插图
在音乐生成过程中 , 从唯一的字符集中随机选择第一个字符 , 使用先前生成的字符生成下一个字符 , 依此类推 。 有了这个结构 , 我们就产生了音乐 。 文章插图
文章插图
下面是帮助我们实现这一点的代码片段 。
sampled = []for i in range(1024):batch = np.zeros((1, 1))if sampled:batch[0, 0] = sampled[-1]else:batch[0, 0] = np.random.randint(vocab_size)result = model2.predict_on_batch(batch).ravel()sample = np.random.choice(range(vocab_size), p=result)sampled.append(sample)print("sampled")print(sampled)print(''.join(idx_to_char[c] for c in sampled))以下是一些生成的音乐片段:
- 通过灵感提升艺术家的创造力
- 作为开发新思想的生产力工具
- 作为艺术家作品的附加曲调
- 完成未完成的工作
- 作为一首独立的音乐
目前 , 我们的模式产生了一些假音符 , 音乐也不例外 。 我们可以通过增加训练数据集来减少这些错误并提高音乐质量 。
总结在这篇文章中 , 我们研究了如何处理与神经网络一起使用的音乐 , 深度学习模型如RNN和LSTMs的工作原理 , 我们还探讨了如何调整模型可以产生音乐 。 我们可以将这些概念应用到任何其他系统中 , 在这些系统中 , 我们可以生成其他形式的艺术 , 包括生成风景画或人像 。
谢谢你的阅读!如果你想亲自体验这个定制数据集 , 可以在这里下载带注释的数据 , 并在Github上查看我的代码:
- 操作|[LIVE On]黄敏贤和郑多彬充满心碎的下午:机器操作每次都不能通过测试
- 五金|我院承担的顺德区家居五金国际质量比对项目顺利通过成果验收
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 用于|用于半监督学习的图随机神经网络
- Reno5|通过HDR10+认证!OPPO Reno5惊喜果然不止这几点
- 方式|富维薄膜计划通过公开招标方式出售Dornier生产线
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 发布|三星Smart Tag跟踪器已通过认证 或于明年1月发布
- 商家|今年双十二 近900万实体商家通过支付宝发券上百亿
- Pro|三星Galaxy Buds Pro通过认证 或与三星S21一同发布