ConcurrentHashMap核心原理,彻底给整明白了
ConcurrentHashMap , 它在技术面试中出现的频率相当之高 , 所以我们必须对它深入理解和掌握 。
谈到 ConcurrentHashMap , 就一定会想到 HashMap 。 HashMap 在我们的代码中使用频率更高 , 不需要考虑线程安全的地方 , 我们一般都会使用 HashMap 。 HashMap 的实现非常经典 , 如果你读过 HashMap 的源代码 , 那么对 ConcurrentHashMap 源代码的理解会相对轻松 , 因为两者采用的数据结构是类似的
这篇文章主要讲解ConcurrentHashMap的核心原理 , 并注释详细源码 , 文章篇幅较长 , 可收藏再看
基本结构ConcurrentHashMap 是一个存储 key/value 对的容器 , 并且是线程安全的 。 我们先看 ConcurrentHashMap 的存储结构 , 如下图: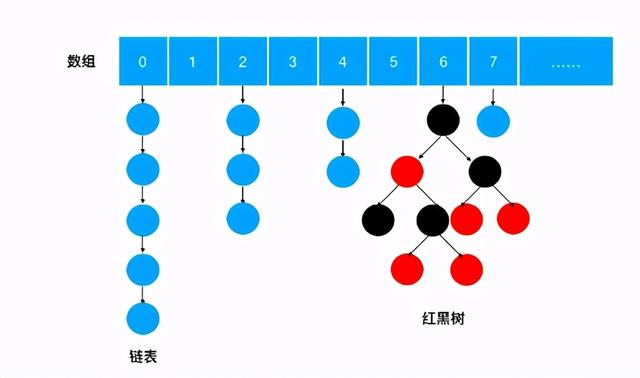 文章插图
文章插图
虽然 ConcurrentHashMap 的底层数据结构 , 和方法的实现细节和 HashMap 大体一致 , 但两者在类结构上却没有任何关联 , 我们看下 ConcurrentHashMap 的类图: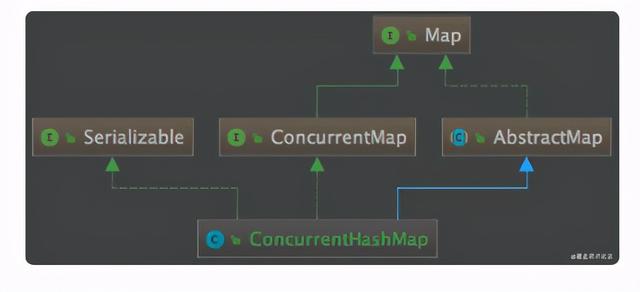 文章插图
文章插图
看 ConcurrentHashMap 源码 , 我们会发现很多方法和代码和 HashMap 很相似 , 有的同学可能会问 , 为什么不继承 HashMap 呢?
继承的确是个好办法 , 但ConcurrentHashMap 都是在方法中间进行一些加锁操作 , 也就是说加锁把方法切割了 , 继承就很难解决这个问题 。
ConcurrentHashMap和HashMap两者的相同之处:
数组、链表结构几乎相同 , 所以底层对数据结构的操作思路是相同的(只是思路相同 , 底层实现不同);
都实现了 Map 接口 , 继承了 AbstractMap 抽象类 , 所以大多数的方法也都是相同的 , HashMap 有的方法 , ConcurrentHashMap 几乎都有 , 所以当我们需要从 HashMap 切换到 ConcurrentHashMap 时 , 无需关心两者之间的兼容问题 。
不同之处:
红黑树结构略有不同 , HashMap 的红黑树中的节点叫做 TreeNode , TreeNode 不仅仅有属性 , 还维护着红黑树的结构 , 比如说查找 , 新增等等;ConcurrentHashMap 中红黑树被拆分成两块 , TreeNode 仅仅维护的属性和查找功能 , 新增了 TreeBin , 来维护红黑树结构 , 并负责根节点的加锁和解锁;
新增 ForwardingNode (转移)节点 , 扩容的时候会使用到 , 通过使用该节点 , 来保证扩容时的线程安全 。
这些概念名词文章后面都会依次介绍
基本构成 重要属性
我们来看看 ConcurrentHashMap 的几个重要属性
//这个Node数组就是ConcurrentHashMap用来存储数据的哈希表 。 transient volatile Node[] table//这是默认的初始化哈希表数组大小private static final int DEFAULT_CAPACITY = 16;//转化为红黑树的链表长度阈值static final int TREEIFY_THRESHOLD = 8//这个标识位用于识别扩容时正在转移数据static final int MOVED = -1//计算哈希值时用到的参数 , 用来去除符号位static final int HASH_BITS = 0x7fffffff;//数据转移时 , 新的哈希表数组private transient volatile Node[] nextTable;复制代码重要组成元素
Node
“
链表中的元素为Node对象 。 他是链表上的一个节点 , 内部存储了key、value值 , 以及他的下一个节点的引用 。 这样一系列的Node就串成一串 , 组成一个链表 。
”
ForwardingNode
“
当进行扩容时 , 要把链表迁移到新的哈希表 , 在做这个操作时 , 会在把数组中的头节点替换为ForwardingNode对象 。 ForwardingNode中不保存key和value , 只保存了扩容后哈希表(nextTable)的引用 。 此时查找相应node时 , 需要去nextTable中查找 。
”
TreeBin
“
当链表转为红黑树后 , 数组中保存的引用为 TreeBin , TreeBin 内部不保存 key/value , 他保存了 TreeNode的list以及红黑树 root 。
”
TreeNode
“
红黑树的节点 。
”
下面依次讲解各个核心方法 , 有详细注释
Put方法public V put(K key, V value) {return putVal(key, value, false);}复制代码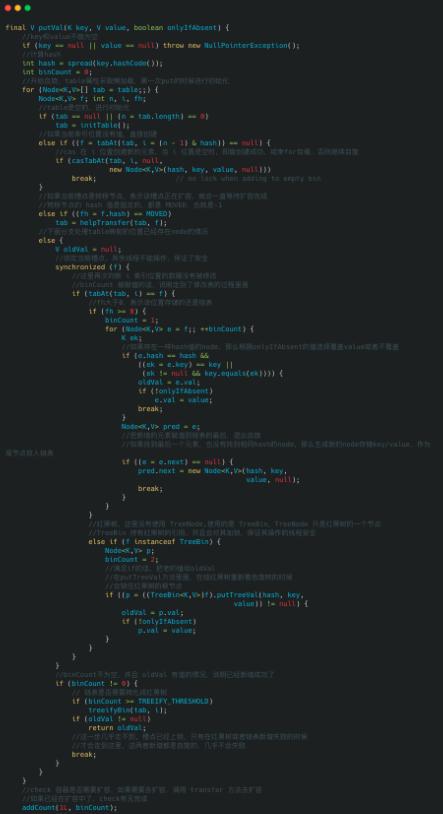 文章插图
文章插图
ConcurrentHashMap 在 put 方法上的整体思路和 HashMap 相同 , 但在线程安全方面写了很多保障的代码 , 我们先来看下大体思路:
1.如果数组为空 , 初始化 , 初始化完成之后 , 走 2;
2.计算当前槽点有没有值 , 没有值的话 , cas 创建 , 失败继续自旋(for 死循环) , 直到成功 , 槽点有值的话 , 走 3;
3.如果槽点是转移节点(正在扩容) , 就会一直自旋等待扩容完成之后再新增 , 不是转移节点走 4;
4.槽点有值的 , 先锁定当前槽点 , 保证其余线程不能操作 , 如果是链表 , 新增值到链表的尾部 , 如果是红黑树 , 使用红黑树新增的方法新增;
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 体验|vivo的OriginOS怎么样?体验报告来袭:虽惊艳但核心问题未解决
- 山东国晶|山东企业攻克OLED面板蒸镀源核心技术瓶颈
- 媒介|智媒介:软文发布文案的核心写作技巧介绍
- 并发容器ConcurrentHashMap
- 随机森林(Random Forest)算法原理
- C/C++协程学习笔记丨C/C++实现协程及原理分析视频
- C++核心准则?:标准库array或vector好于C数组
- 「书讯」移动互联网对企业核心能力影响研究
- 领导者的核心是战略定力