ConcurrentHashMap核心原理,彻底给整明白了( 二 )
5.新增完成之后 check 需不需要扩容 , 需要的话去扩容 。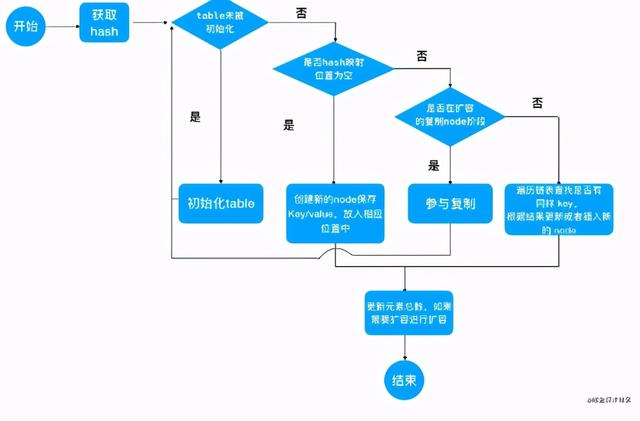 文章插图
文章插图
ConcurrentHashMap在put过程中 , 采用了哪些手段来保证线程安全呢?
数组初始化时的线程安全
数组初始化时 , 首先通过自旋来保证一定可以初始化成功 , 然后通过 CAS 设置 SIZECTL 变量的值 , 来保证同一时刻只能有一个线程对数组进行初始化 , CAS 成功之后 , 还会再次判断当前数组是否已经初始化完成 , 如果已经初始化完成 , 就不会再次初始化 , 通过自旋 + CAS + 双重 check 等手段保证了数组初始化时的线程安全
那么接下来我们就来看看 initTable 方法 。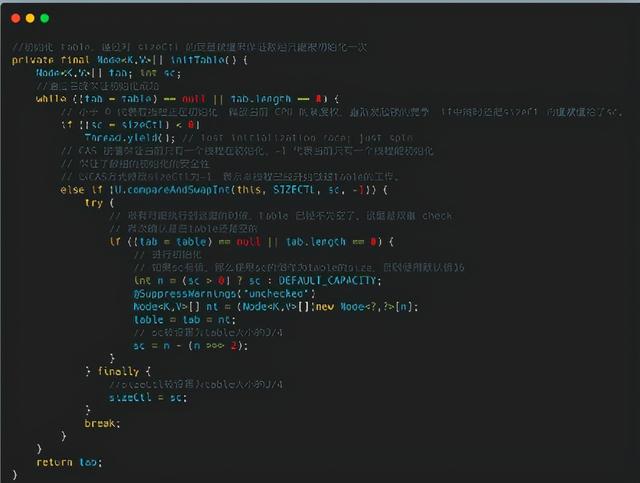 文章插图
文章插图
注意里面有个关键的值 sizeCtl , 这个值有多个含义 。
1、-1 代表有线程正在创建 table;
2、-N 代表有 N-1 个线程正在复制 table;
3、在 table 被初始化前 , 代表根据构造函数传入的值计算出的应被初始化的大小;
4、在 table 被初始化后 , 则被设置为 table 大小 的 75% , 代表 table 的容量(数组容量) 。
新增槽点值时的线程安全
此时为了保证线程安全 , 做了四处优化:
1.通过自旋死循环保证一定可以新增成功 。
在新增之前 , 通过 for (Node
2.当前槽点为空时 , 通过 CAS 新增 。
Java 这里的写法非常严谨 , 没有在判断槽点为空的情况下直接赋值 , 因为在判断槽点为空和赋值的瞬间 , 很有可能槽点已经被其他线程复制了 , 所以我们采用 CAS 算法 , 能够保证槽点为空的情况下赋值成功 , 如果恰好槽点已经被其他线程赋值 , 当前 CAS 操作失败 , 会再次执行 for 自旋 , 再走槽点有值的 put 流程 , 这里就是自选 + CAS 的结合 。
3.当前槽点有值 , 锁住当前槽点 。
put 时 , 如果当前槽点有值 , 就是 key 的 hash 冲突的情况 , 此时槽点上可能是链表或红黑树 , 我们通过锁住槽点 , 来保证同一时刻只会有一个线程能对槽点进行修改
V oldVal = null;//锁定当前槽点 , 其余线程不能操作 , 保证了安全synchronized (f) {复制代码4.红黑树旋转时 , 锁住红黑树的根节点 , 保证同一时刻 , 当前红黑树只能被一个线程旋转
Hash算法spread方法源码分析
哈希算法的逻辑 , 决定 ConcurrentHashMap 保存和读取速度 。
static final int spread(int h) {return (h ^ (h >>> 16)) }复制代码传入的参数h为 key 对象的 hashCode , spreed 方法对 hashCode 进行了加工 。 重新计算出 hash 。
hash 值是用来映射该 key 值在哈希表中的位置 。 取出哈希表中该 hash 值对应位置的代码如下 。
【ConcurrentHashMap核心原理,彻底给整明白了】tabAt(tab, i = (n - 1) 复制代码我们先看这一行代码的逻辑 , 第一个参数为哈希表 , 第二个参数是哈希表中的数组下标 。 通过 (n - 1)--tt-darkmode-color: #A3A3A3;">15的二进制高位都为0 , 低位都是1 。 那么经过 --tt-darkmode-color: #A3A3A3;">1、数组大小可以为 17 , 或者 18 吗?
2、如果为了保证不越界为什么不直接用 % 计算取余数?
3、为什么不直接用 key 的 hashCode , 而是使用经 spreed 方法加工后的 hash 值?
数组大小必须为 2 的 n 次方
第一个问题的答案是数组大小必须为 2 的 n 次方 , 也就是 16、32、64….不能为其他值 。 因为如果不是 2 的 n 次方 , 那么经过计算的数组下标会增大碰撞的几率
如果hash值的二进制是 10000(十进制16)、10010(十进制18)、10001(十进制17) , 和10100做 --tt-darkmode-color: #A3A3A3;">但如果数组长度n为2的n次方 , 2进制的数值为10 , 100 , 1000 , 10000……n-1后对应二进制为1 , 11 , 111 , 1111……这样和hash值低位 --tt-darkmode-color: #A3A3A3;">同时(n - 1)--tt-darkmode-color: #FF5D6C;">hash%n 。 那么为什么不直接用hash%n呢?
这是因为按位的操作效率会更高 。
为什么不直接用 key 的 hashCode?
其实说到底还是为了减少碰撞的概率 。 我们先看看 spreed 方法中的代码做了什么事情:
h ^ (h >>> 16)复制代码这个意思是把 h 的二进制数值向右移动 16 位 。 我们知道整形为 32 位 , 那么右移 16 位后 , 就是把高 16 位移到了低 16 位 。 而高 16 位清0了 。
^为异或操作 , 二进制按位比较 , 如果相同则为 0 , 不同则为 1 。 这行代码的意思就是把高低16位做异或 。 如果两个hashCode值的低16位相同 , 但是高位不同 , 经过如此计算 , 低16位会变得不一样了 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 体验|vivo的OriginOS怎么样?体验报告来袭:虽惊艳但核心问题未解决
- 山东国晶|山东企业攻克OLED面板蒸镀源核心技术瓶颈
- 媒介|智媒介:软文发布文案的核心写作技巧介绍
- 并发容器ConcurrentHashMap
- 随机森林(Random Forest)算法原理
- C/C++协程学习笔记丨C/C++实现协程及原理分析视频
- C++核心准则?:标准库array或vector好于C数组
- 「书讯」移动互联网对企业核心能力影响研究
- 领导者的核心是战略定力