阿里深度召回模型实践( 二 )
② Position Embedding
对于行为序列任务 , 我们需要使用位置嵌入来捕获行为序列中的顺序信息 。 我们采用不同于 Transformer 原论文[8]中的 sin 和 cos 方法 , 直接使用 Max Sequence Length 个 Embedding 来表示不同的位置 。
③ Play Rate Embedding
播放完成率是用户对于 Item 接受程度的一个重要反馈 , 在天猫精灵上 , 对于不喜欢的歌曲 , 用户通常会直接使用“下一首”指令将其切掉 , 这些歌曲的播放完成率就会比较低 。 播放完成率是一个值域在 [0, 1] 间的连续值 , 为了实现后面将要提到的连续值特征和离散值特征的交互 , 我们参照了[9]中方案 , 将 Play Rate 映射到了与 Item Embedding 相同的低维向量空间 , 具体来说 , 我们将 Play Rate Embedding 表示为:
其中 , Xr 是 Play Rate , Vr 是随机初始化的 Embedding , Er 是最终得到的 Play Rate Embedding , 由于我们 Train Set 1 数据只有播放时长较高的歌曲 , 并且没有播放完成率的信息 , 因此对于 Train Set 1 , 我们固定所有 Play Rate 为 0.99:
④ Intent Type Embedding
用户意图类型表示了用户进入这个 Item 的方式 , 比如在天猫精灵端 , 点播(用户明确点播出的歌曲)和推荐(天猫精灵为用户推荐的歌曲)就是两种不同的 Intent Type(天猫精灵的实际场景中类型会更多) , 类似 Item 本身的表示 , 我们把 Intent Type 也映射到了一个固定的低维向量空间:
我们不知道 Train Set 1 数据中的 Intent Type , 在此我们假设所有的 Train Set 1 数据的 Intent Type 全部为点播:
2. Factorized Embedding Parameterization
在推荐的任务中 , Vocabulary Size 通常是巨大的 , 这导致了我们无法使用太大的 Embedding Size 来表示 Item , 否则显存放不下 , 但很多使用 Transformer 的工作证明 , 提高 Hidden Size 可以有效的提升模型效果[10] , 参照 ALBERT[11] 压缩模型的方式 , 我们首先把 Item 的 One-Hot 向量映射到一个低维度的空间 , 大小为E , 然后再映射回高维度的空间再输入Transformer , 从而把参数量从 O(V×H) 降低到了 O(V×E+E×H) , 当 E?H 时参数量会明显减少 。
3. Feedback-Aware Multi-Head Self-Attention
在获得用户行为序列的特征表示后 , 我们就可以准备构建用户向量了 , 我们采用了注意力机制来编码用户的行为序列 。 如 Transformer[8] 中所述 , 注意力机制可以被描述为一个将 Query 和一系列的 Key-Value Pairs 映射到 Output 的函数 , 其中 Query , Key , Value 和 Output 都是向量 , Output 被计算为 Value 的加权和 , 其中分配给每个 Value 的权重由 Query 与对应 Key 的打分函数计算 , 由于召回模型的限制 , 我们无法使用 Target Item 提前和用户行为序列中的 Item 做运算 , 因此采用 Self-Attention 的方式 , 直接把用户行为序列作为 Query , Key , Value 来进行计算 。 具体来说 , 我们使用了 Multi-Head Self-Attention 的方式来提升模型对于复杂交互的建模能力: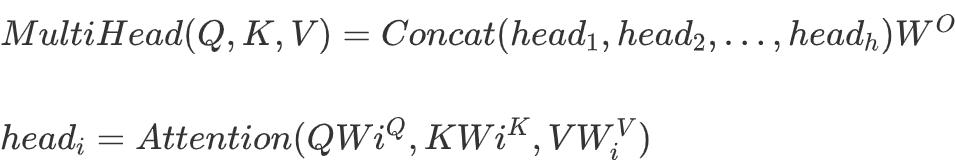 文章插图
文章插图
其中 ,WiQ、WiK、WiV 是线性投影矩阵 , h 是 head 的数量 。 在经典的 Transformer 结构中 , Q , K , V 由 Item Embedding 和 Position Embedding 构成 , 在我们的模型中 , 我们将外部信息(播放完成率和用户意图类型)引入到 Attention 中来 , 我们称之为 Feedback-Aware Attention , 通过对这些信息的引入 , 我们的模型就有能力结合用户的反馈信息感知用户对于各个歌曲的不同的偏好程度了:
除此之外我们还参照 ALBERT[11] , 尝试了 Cross-layer Parameter Sharing 的方案 , 这种方案让每层 Transformer Layer 全部共享一组参数 , 同样量级(层数相同)下的 Transformer 采用该方案后实际上的效果是会有所下降的 , 但是参数量减少了很多 , 训练速度也会快很多 , 对于推荐这种数据规模比较庞大的场景 , 采用这种策略可以在尽量节约训练时间的前提下提升模型性能 。
4. Sampled Softmax Loss For Positive Feedback and Sigmoid CE Loss For Negative Feedback
在获得用户的向量表示后 , 就可以定义多任务学习的目标了 , 由于之前我们已经统一了 Train Set 1 和 Train Set 2 的数据表示 , 因此这两个任务可以放在一起进行联合多任务训练 。 具体来说 , 我们的任务类似于语言模型:给定前 t 个已经听过的音乐 , 预测第 t+1 步用户想要听什么音乐 , 我们根据播放完成率的高低将信号分成两种(实际实现时会使用一个阈值来区分) , 一种是 Positive Feedback , 这种的优化目标是使其打分排序尽量靠前 , 另一种是 Negative Feedback , 这种的优化目标是使其打分排序尽量靠后 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 注册|阿里申请注册“爆改吧!小店”商标,打造线下特色实体小店
- 耽误|被阿里耽误的虾米的一生
- 采用|iPhone12mini和iPhone7深度对比:值得升级吗
- 设计|未来创意拒绝被垄断:欧拉共创成果深度解读!
- X50|vivo X50 Pro+深度测评:全能影像机皇登场
- 广度|华住创始人季琦:深度重要于广度
- 租赁物业|居然之家(000785)牵手阿里与小米
- NeurIPS 2020论文分享第一期|深度图高斯过程 | 深度图