阿里深度召回模型实践( 三 )
如下图的左图所示 , 如果只做传统的 Positive Feedback Loss 的话 , 我们的模型可以拉近用户向量和喜欢的 Item(正向样本)的距离并拉大其和未观测 Item 的距离 , 但是不喜欢的 Item(负向样本)的距离可能并不会被拉开 , 我们希望我们的模型可以向右图一样 , 在做到上述特性的同时 , 拉大用户向量与不喜欢的 Item 的距离: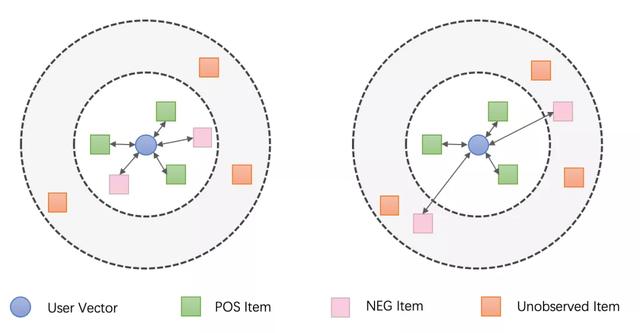 文章插图
文章插图
图 3 优化目标对比
因此我们使用了 Positive Feedback 和 Negative Feedback 结合的优化目标:
对于 Positive Feedback , 我们使用 Sampled Softmax Loss 来优化 。 在之前的很多工作中[12-13] , Sampled Softmax Loss 已经被证明非常适用于大规模推荐召回模型 , 它的定义如下: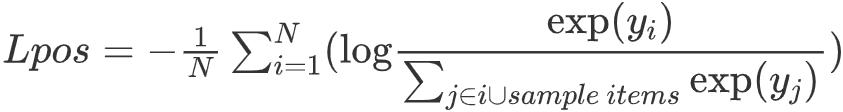 文章插图
文章插图
在使用 Tensorflow 实现的时候 , sampled_softmax 默认使用的采样器为log_uniform_candidate_sampler ( TF 版 Word2Vec 基于此实现 ) , 它基于 Zipfian 分布来采样 , 每个 Item 被采样的概率只跟他词频的排序相关 , 采样概率不是词的频率 , 但是推荐中的商品和 NLP 中的词可能不同 , 因此我们尝试了另外两个采样器:
- uniform_candidate_sampler:使用均匀分布来采样
- learned_unigram_candidate_sampler:这个分布会动态统计训练过程中的词表 , 然后计算概率并进行采样
对于 Negative Feedback , 我们直接使用 Sigmoid Cross Entropy Loss 来优化 , 将播放完成率低的 Item 全部看成负例 , 使其打分尽量低:
最终的总 Loss 则为两者的加和:
03
实验
1. 分布式训练
推荐场景的词表大小和数据量通常是巨大的 , 因此我们采用了 TensorFlow 中的 ParameterServer 策略来实现分布式训练的代码 。 调优过程中也积累了一些经验:
① 需要注意 Embedding 分片的问题 , 一个是 tf.fixed_size_partitioner 中的 size , 另外一个是embedding_lookup 中的 partition_strategy , 需要保持他们在 Training 和 Inference 过程中的设置是相同的 。
② sample_softmax 中的代码需要根据自己的场景来做优化 , 比如在我们的场景中 , 同一个 batch 中的重复 sample item 比例比较高 , 把里面的 embedding_lookup 加上 unique , 可以大幅提升训练速度 。
③ 灵活使用 Mask 机制 , 可以有效的实现各种不同的 Attention 策略 。
2. 实验结果
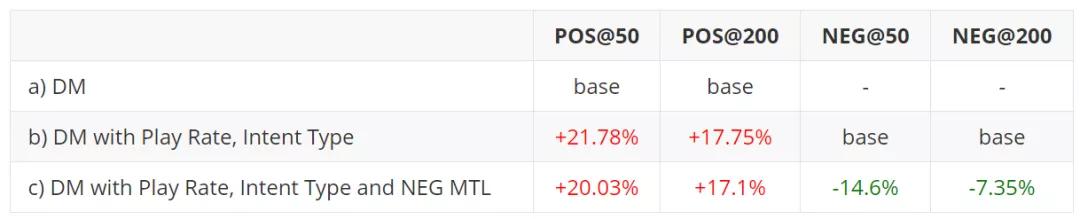
离线实验的指标采用 R@N , 即打分排序的前 N 项结果包含Target Item 的比例 , 对于正向样本 , 指标称为 POS@N , 我们希望这个值越高越好 , 对于负向样本 , 指标称为 NEG@N , 我们希望这个值越低越好 。 由于篇幅限制 , 我们只列出一组主要的实验结果 , 这组实验验证了 Multitask Learning 和 Negative Feedback 的效果 , 我们在其他策略都采用上述最优的情况下(比如优化器 , 采样方法等) , a 采用传统 DM 方式训练 , 只保留完播率较高的正反馈 Item 来构建行为序列 , b 在 a 的基础上加入 Play Rate、Play Type 特征 , c 在 b 的基础上再加入负向反馈信号进行多任务训练:
 文章插图
文章插图可以看出 , 加入反馈信号(Play Rate)和歌曲点播 query 意图信号(Intent Type)后 , b 的效果要优于 a , 再加入 Negative Feedback 目标进行 Multitask Learning 后 , c 可以保证 POS@N 微小变化的情况下明显降低 NEG@N 。
我们在猜你喜欢的线上场景中也证明了新方法的有效性 , 和基于 DM 原方案的分桶相比 , 新模型(DM with Play Rate/Intent Type and NEG MTL)分桶的人均播放时长提高了 +9.2%;同时该方法已经应用于天猫精灵推荐的更多场景中并取得了不错的收益 。
【阿里深度召回模型实践】作者:韩宇、张跃伟 阿里巴巴
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 注册|阿里申请注册“爆改吧!小店”商标,打造线下特色实体小店
- 耽误|被阿里耽误的虾米的一生
- 采用|iPhone12mini和iPhone7深度对比:值得升级吗
- 设计|未来创意拒绝被垄断:欧拉共创成果深度解读!
- X50|vivo X50 Pro+深度测评:全能影像机皇登场
- 广度|华住创始人季琦:深度重要于广度
- 租赁物业|居然之家(000785)牵手阿里与小米
- NeurIPS 2020论文分享第一期|深度图高斯过程 | 深度图