"全能选手"召回表征算法实践
本文主要分享 "全能选手" 召回表征算法实践 。 首先简单介绍下业务背景:
网易严选人工智能部 , 主要有三个方向:NLP、搜索推荐、供应链 , 我们主要负责搜索推荐 。 搜索推荐与营销端的业务场景密切相关 , 管理着严选最大的流量入口 。 我们团队的主要目标是优化转化率和GMV相关指标 , 具体业务是搜索、推荐、广告 ( 包含内部资源位广告以及外部的DPS广告 ) 。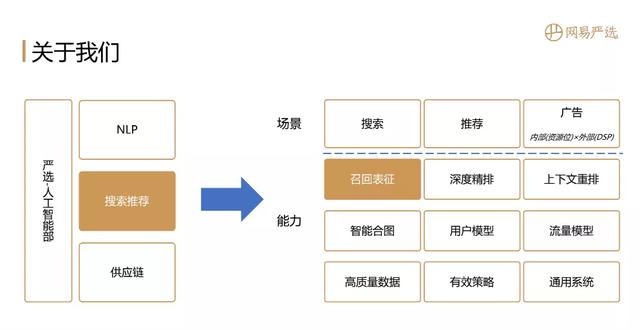 文章插图
文章插图
如图所示 , 在这些个性化场景下是我们具备的能力矩阵 。 刚接到邀请的时候我是想聊一聊在严选业务场景下的个性化相关事情 , 但是我们业务基本都做了2~3年 , 想在短时间聊完 , 只能介绍我们做了哪些工作以及取得什么样的业务价值 。 但是每个人的业务场景差异较大 , 我们这边最优的实现方案在其他场景可能并不是最优方案 , 大家听完之后 , 可能没有太大的收获 。 与其这样 , 还不如聚焦在一个小模块上详细聊一下 , 所以今天就选召回表征这个部分 , 也就引出了本次分享主题:"全能选手"召回表征算法实践 , 主要内容包括:
- 问题定义:召回表征究竟是要解决什么问题
- 模型价值:召回表征的价值或收益是什么
- 迭代实现:一步步迭代演化的过程
- 业务落地:业务落地的案例
问题定义
1. 模型目标
 文章插图
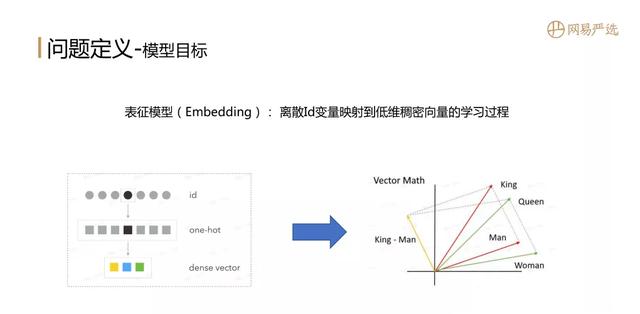
文章插图首先说一下问题的定义 , 就是模型的目标是想做什么?表征模型 ( Embedding ):是将离散id变量映射到低维稠密向量的学习过程 。 用离散id做特征时一般先做one-hot编码 , 然后再映射成dense vector 。 Embedding的目标是在大数据中体现相关性的主体 , 通过Embedding向量表征学习到主体的向量信息 , 使用向量度量公式也能体现出主体间的相关性 , 比如右边这个例子 , 红色线表示King和Man , 假如这个King和Man都已经训练出一个向量表征的结果 , 我们希望King和Man的内积要大于Queen和Man的內积 , 这样就得到一个Embedding的目标 。
2. 数据处理
 文章插图
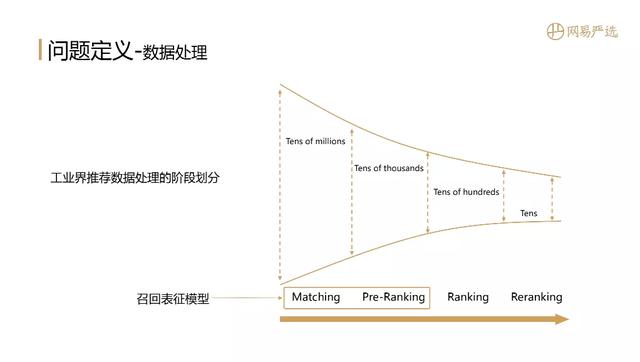
文章插图其实Embedding是一个非常通用的模型用于主体的学习和表达 , 它在NLP、搜索、推荐、图像中都有广泛应用 。 那么到具体业务场景在搜索推荐中Embedding到底是如何发挥作用的?下面这个图是一个非常经典的工业界推荐数据处理的阶段划分 , 从左到右是一个数据逐层递减的过程 , 依次是召回 ( Matching )、粗排 ( Pre-Ranking )、精排 ( Ranking )、重排 ( Reranking ) 。 那我们的召回表征模型的作用范围主要是召回和粗排两个阶段 , 它在搜索推荐中起到基石的作用 。
3. 模型能力
 文章插图
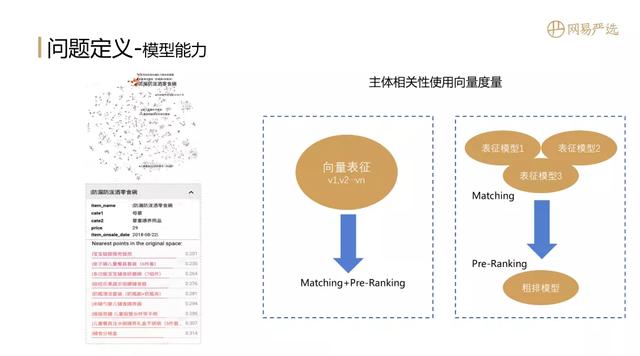
文章插图当模型训练出来后 , 主体的相关性是可以用向量相似度来衡量的 , 下图是一些item的表征形式 , 如果几个item相似 , 那么他们的距离就比较小 , 内积比较大 , 比如和零食碗相似的都是一些相同类目下的商品 。 如果我们只有一个向量表征模型 , 那么模型的Embedding既可用于召回 , 也可以利用两个item的Embedding向量內积来作为粗排的依据 , 这样召回和粗排两个场景可以一次搞定 。 但是大多数情况下会存在多种表征模型 , 每种表征模型都会去做召回 , 这种情况下需要引入粗排模型将多个表征模型的召回结果进行合并、排序 。 用于合并的粗排能力可以策略结合蒸馏模型 , 这里先不展开介绍 。
02
模型价值
表征模型为什么值得深入去做?
1. 应用场景广泛
 文章插图
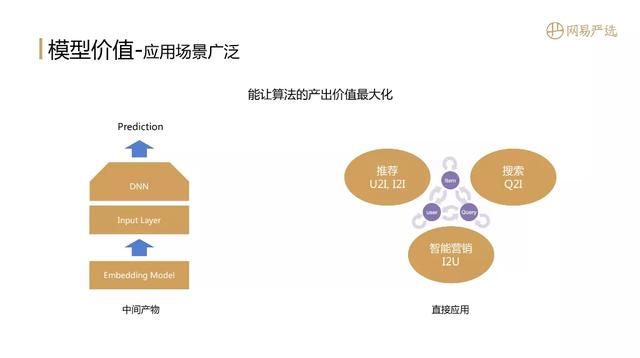
文章插图接下来介绍表征模型为什么值得深入去做?它能产生什么价值?问题答案跟文章标题密切相关:Embedding是一个全能选手 , 应用非常广泛 , 能让算法产出价值最大化 。 应用场景包括:
- 中间产物:Embedding结果作为精排模型向量特征的初始化权重 。
- 排序呈现:拿到主体Embedding的向量 , 计算內积完成召回、排序的功能 。
- 场景复用:端到端的场景使用 , 例如推荐中U2I、I2I的召回、粗排 , 搜索中的Q2I语义匹配 , 智能营销上的I2U精准触达 。
 文章插图
文章插图Embedding向量已经有了 , 还需要向量搜索引擎来将向量推到线上使用 , 具备online的响应能力 。 基于向量搜索引擎提供的接口可以找到与给定向量内积最大的或距离最近的TopN个向量 。 第一个是Facebook较早提出的Faiss的方案 , 第二个是Google提出的SCANN的方案;这两个方案都很好 , 能大幅降低工程门槛 。
- X50|vivo X50 Pro+深度测评:全能影像机皇登场
- 示该站点|虾秘功能大揭秘之订单监测&广告概况
- 京东另类科学实验室之"5G来了"
- ICPC--1200:数组的距离时间限制&1201:众数问题
- "财富梦"AI外贸配方?国货搭载AI"火箭营销"?
- ICPC--1206: 字符串的修改&1207:字符排列问题
- ICPC--1204: 剔除相关数&1205: 你爱我么?
- 音乐平台"改头换面",是新一轮社交平台,还是生活放松圈
- MITRE ATT&CK系列文章之Windows管理共享风险检测
- 极品"看片"神器!震撼来袭~手机端盒子端全部通用