"全能选手"召回表征算法实践( 三 )
2. 获取User Embedding
我们第一阶段获取到Item Embedding , 怎么由Item Embedding得到User Embedding?主要是两种思路:策略的方法和模型的方法 。
① 策略快速落地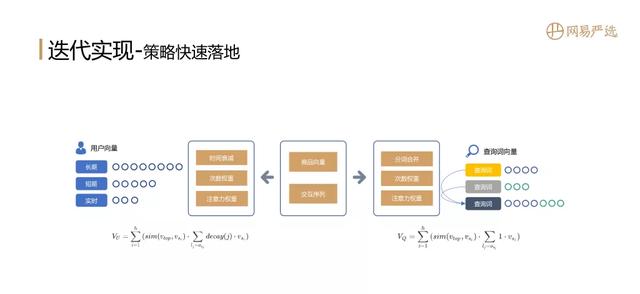 文章插图
文章插图
策略是能快速落地的方案 , 是一个很好很稳定的baseline 。 我们可以利用已知的商品隐向量和session中用户的交互行为序列 , 基于时间衰减、次数权重和注意力机制来得到用户的向量表征 。 同样的在搜索场景下也可以通过查询词的分词合并、次数权重、注意力权重得到查询词的向量表征 。
② 经典DNN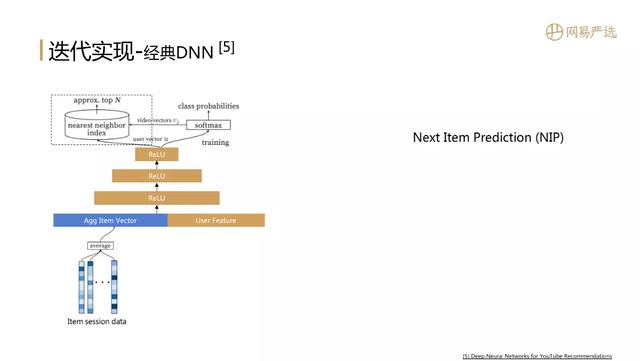 文章插图
文章插图
接下来还有一个经典模型DNN , 直接通过模型得到用户的向量 。 参考图中YouTube的这篇经典论文 , 模型本质上是一个有监督的NextItemPrediction训练过程 , 用户的Item session data , 做一个简单average聚合 , 再加上user feature作为深度模型的输入特征数据 。 输入特征数据经过层层传播 , 到达最后一层得到用户向量 , 用户向量和item向量做softmax , 完成一个概率分布的预测 , 也就得到了模型的loss 。 模型训练完成后同时得到User和Item的向量表示 。
③ 学习session表征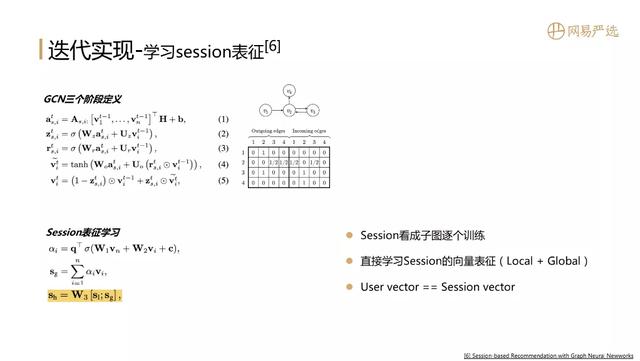 文章插图
文章插图
我们当然希望通过图模型得到用户的向量 。 用户的行为基于session来表示的 , 如果有一个方法能直接对session进行向量表示 , 那就可以直接得到行为序列下的用户向量 。 下图中的论文就是通过学习session向量的表示来解决这个问题 , 它同时也有GCN三个阶段的定义 , 在定义过程中还引入了门的参数来设置最终向量的表示过程 。 最有价值的点是它做了session的表征学习 , 在训练过程中每个session看成子图进行逐个训练 , 然后用local向量 ( session中最后一个item向量 ) 加上global向量 ( session中其他item向量经过attention聚合得到一个global向量 ) 来作为session向量 , 最后用session向量来代表用户向量 。 在离线评估中这个模型的效果是较为突出的 。
④ 多个用户向量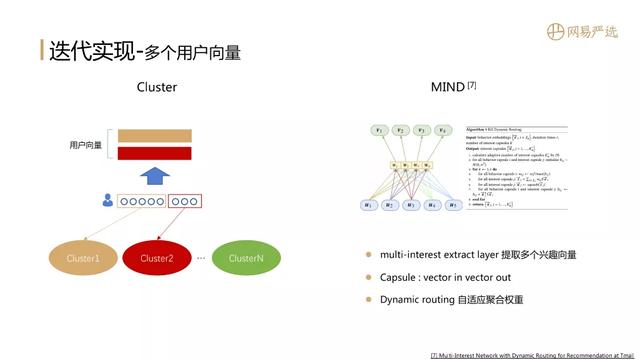 文章插图
文章插图
我们之前一直用单个向量对用户进行表征 , 那么能不能用多个用户向量对用户的兴趣进行表征呐?答案是可以的 , 因为如果用户的兴趣比较广泛 , 用一个向量进行表征会存在信息丰富度的丢失 , 而用多个向量来表示用户 , 效果可能会更好 。
第一种思路是聚类方法:先将item K-means聚类得到多个cluster , 每个cluster有一个向量表征 。 用户行为序列中的商品如果涉及多个cluster , 就将属于相同cluster的向量聚合表征用户 。 聚合的方法可以和cluster向量计算权重后按位相加 , 用户向量个数等于序列中所属cluster的个数 。
第二种思路是MIND:它利用胶囊网络来形成多个兴趣向量 , 结构中有一个multi-interest extract layer负责提取多个兴趣向量 , 图示中u1、u2是用户行为序列中item的向量 , 他们作为胶囊网络的输入 , v1、v2是用户的多个兴趣向量也是胶囊网络的输出 。 同时胶囊网络还支持动态路由 , 多次迭代自适应的得到聚合权重 。
3. 效果对比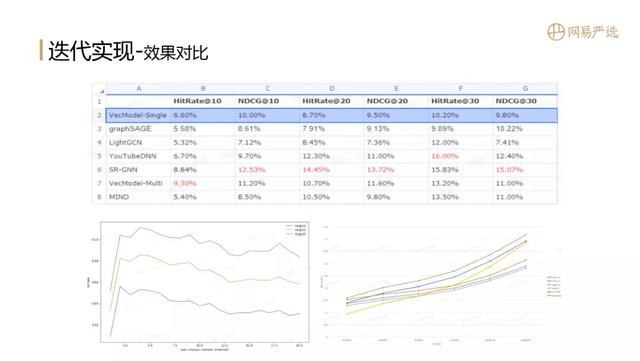 文章插图
文章插图
接下来我们对这几种网络模型做一个对比 , 对比的指标是HitRate和NDCG 。 我们采用VecModel-Single ( 序列模型Session Based Embedding Model ) 作为基线模型 。
在我们场景数据中 , graphSAGE作为GCN的一个工业落地实现指标并不突出 , 在NDCG@30时略微超出基线模型 。 LightGCN是通过缩减数据来适配目前已有的最大锅 , 进而生产出最大的饼;LightGCN以矩阵方式去做向量表征学习 , 相比基线模型效果也不是特别突出 , 只在个别指标HitRate@30上有一些提升 。 YouTubeDNN在4个指标上都有较为明显的提升 。 SR-GNN是直接对session做用户向量表征 , 通过模型参数学习求得用户向量 , 也是目前离线效果最好的模型 。 VecModel-Multi是在序列模型的基础上 , 增加聚类的用户多兴趣向量表示 , MIND是基于胶囊网络的多兴趣向量模型;在我们数据实验中 , VecModel-Multi要比MIND的效果更好 。
左下图是不同用户行为分组的模型效果 , X轴是用户的行为数量 , Y轴是HitRate 。 刚开始用户没有行为时无法感知用户偏好 , 模型效果是比较差的 ( User Type Embedding实现NIP ) 。 当用户有1、2个行为之后 , 效果指标大幅提升 。 这也比较好理解 , 因为新用户来到一个场景产生初始行为时兴趣是比较聚焦的 , 但是随着用户行为数量增多 , 仅仅用向量模型做召回和排序 , 指标就会下降 , 这时候就需要接精排、重排模型去进一步提升业务效果 。 右下图是多个模型在HitRate@N的效果 , 其中绿色曲线为使用策略将多个模型结果融合后的表现 , 可以看到只是做了简单的合并 , 相比于其他单一模型就有明显提升 。 后续还可以采用粗排模型合并各个表征模型的结果 , 效果应该还会有提升 ( 用于合并的粗排模型还在进行中 ) 。
- X50|vivo X50 Pro+深度测评:全能影像机皇登场
- 示该站点|虾秘功能大揭秘之订单监测&广告概况
- 京东另类科学实验室之"5G来了"
- ICPC--1200:数组的距离时间限制&1201:众数问题
- "财富梦"AI外贸配方?国货搭载AI"火箭营销"?
- ICPC--1206: 字符串的修改&1207:字符排列问题
- ICPC--1204: 剔除相关数&1205: 你爱我么?
- 音乐平台"改头换面",是新一轮社交平台,还是生活放松圈
- MITRE ATT&CK系列文章之Windows管理共享风险检测
- 极品"看片"神器!震撼来袭~手机端盒子端全部通用