交互式分析领域,为何 ClickHouse 能够杀出重围?( 二 )
(1)逻辑数据模型
从用户使用角度看 , ClickHouse 的逻辑数据模型与关系型数据库有一定的相似:一个集群包含多个数据库 , 一个数据库包含多张表 , 表用于实际存储数据 。
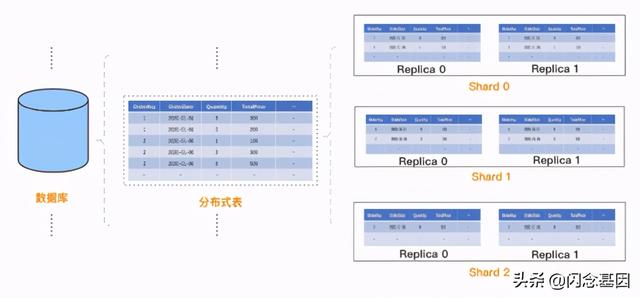
与传统关系型数据库不同的是 , ClickHouse 是分布式系统 , 如何创建分布式表呢?ClickHouse 的设计是:先在每个 Shard 每个节点上创建本地表(即 Shard 的副本) , 本地表只在对应节点内可见;然后再创建分布式表 , 映射到前面创建的本地表 。 这样用户在访问分布式表时 , ClickHouse 会自动根据集群架构信息 , 把请求转发给对应的本地表 。 创建分布式表的具体样例如下:
# 首先 , 创建本地表CREATE TABLE table_local ON CLUSTER cluster_test(OrderKeyUInt32,# 列定义OrderDateDate,QuantityUInt8,TotalPriceUInt32,……)ENGINE = MergeTree()# 表引擎PARTITION BY toYYYYMM(OrderDate)# 分区方式ORDER BY (OrderDate, OrderKey);# 排序方式SETTINGS index_granularity = 8192;# 数据块大小 # 然后 , 创建分布式表CREATE TABLE table_distribute ON CLUSTER cluster_test AS table_localENGINE = Distributed(cluster_test, default, table_local, rand())# 关系映射引擎其中部分关键概念介绍如下 , 分区、数据块、排序等概念会在物理存储模型部分展开介绍:- MergeTree :ClickHouse 中使用非常多的表引擎 , 底层采用 LSM Tree 架构 , 写入生成的小文件会持续 Merge 。
- Distributed :ClickHouse 中的关系映射引擎 , 它把分布式表映射到指定集群、数据库下对应的本地表上 。
 文章插图
文章插图(2)物理存储模型
接下来 , 我们来介绍每个分片副本内部的物理存储模型 , 具体如下:
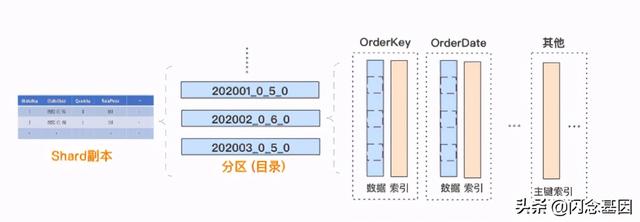
- 数据分区 :每个分片副本的内部 , 数据按照 PARTITION BY 列进行分区 , 分区以目录的方式管理 , 本文样例中表按照时间进行分区 。
- 列式存储 :每个数据分区内部 , 采用列式存储 , 每个列涉及两个文件 , 分别是存储数据的 .bin 文件和存储偏移等索引信息的 .mrk2 文件 。
- 数据排序 :每个数据分区内部 , 所有列的数据是按照 ORDER BY 列进行排序的 。 可以理解为:对于生成这个分区的原始记录行 , 先按 ORDER BY 列进行排序 , 然后再按列拆分存储 。
- 数据分块 :每个列的数据文件中 , 实际是分块存储的 , 方便数据压缩及查询裁剪 , 每个块中的记录数不超过 index_granularity , 默认 8192 。
- 主键索引 :主键默认与 ORDER BY 列一致 , 或为 ORDER BY 列的前缀 。 由于整个分区内部是有序的 , 且切割为数据块存储 , ClickHouse 抽取每个数据块第一行的主键 , 生成一份稀疏的排序索引 , 可在查询时结合过滤条件快速裁剪数据块 。
 文章插图
文章插图三、ClickHouse核心特性
ClickHouse 为什么会有如此高的性能 , 获得如此快速的发展速度?下面我们来从 ClickHouse 的核心特性角度来进一步介绍 。
1. 列存储ClickHouse 采用列存储 , 这对于分析型请求非常高效 。 一个典型且真实的情况是:如果我们需要分析的数据有 50 列 , 而每次分析仅读取其中的 5 列 , 那么通过列存储 , 我们仅需读取必要的列数据 , 相比于普通行存 , 可减少 10 倍左右的读取、解压、处理等开销 , 对性能会有质的影响 。
这是分析场景下 , 列存储数据库相比行存储数据库的重要优势 。 这里引用 ClickHouse 官方一个生动形象的动画 , 方便大家理解:
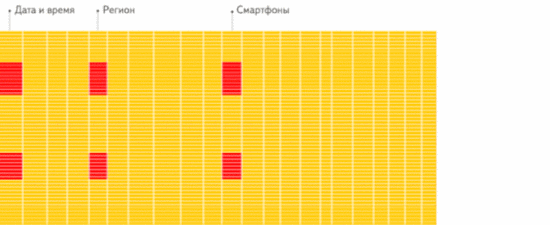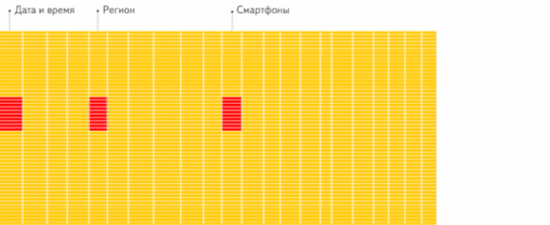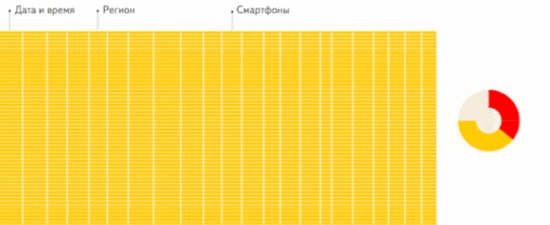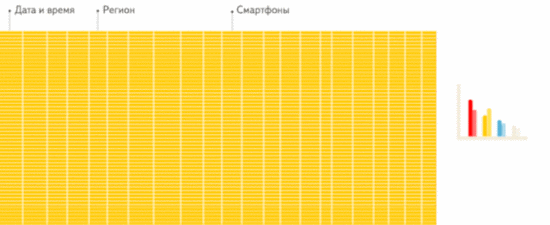
行存储 :从存储系统读取所有满足条件的行数据 , 然后在内存中过滤出需要的字段 , 速度较慢:
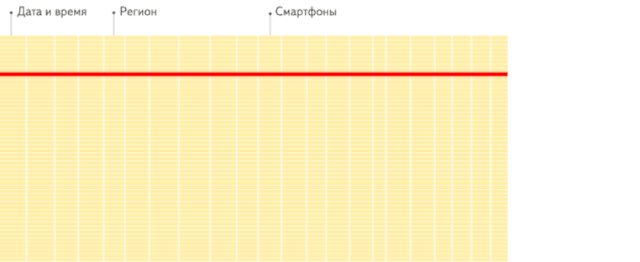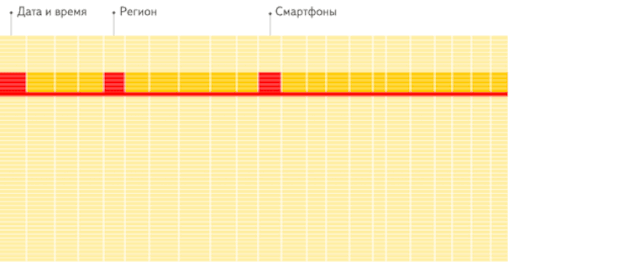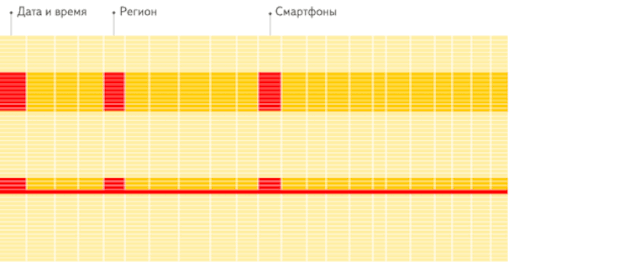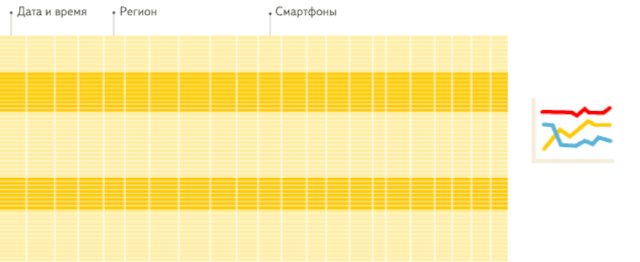 文章插图
文章插图列存储 :仅从存储系统中读取必要的列数据 , 无用列不读取 , 速度非常快:
 文章插图
文章插图2. 向量化执行在支持列存的基础上 , ClickHouse 实现了一套面向 向量化处理 的计算引擎 , 大量的处理操作都是向量化执行的 。
- 率先|还在相片美颜?OPPO已进军视频美妆领域,周冬雨或率先体验
- 制药领域|为什么AI制药这么火,为什么是现在?
- 资本|2020年中国人工智能医疗行业发展现状分析 处于成长期且资本热度高
- 用户|密室逃脱行业发展及用户分析报告:哪些人在沉迷密室逃脱?
- 框架|三种数据分析思维框架的构建方法
- 分析师|真香定律或再被验证,iPhone12将大卖,分析师给出两个原因
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- 文章|局座张召忠:分析局座历年的文章发现,我发现这些秘密
- 博会|第17届东博会:设置5400个实体展位 多领域成果丰硕
- 主题|GNN、RL崛起,CNN初现疲态?ICLR 2021最全论文主题分析