GPU|干货|基于 CPU 的深度学习推理部署优化实践( 二 )
算法级的优化主要针对深度学习模型本身 , 利用诸如超参数设置、网络结构裁剪、量化等方法来减小模型大小和计算量 , 从而加速推理过程 。 文章插图
文章插图
图 6. 深度学习服务性能优化方法及分析工具
2.2 如何进行系统级的优化?
CPU 上系统级优化实践中我们主要采用数学库优化(基于 MKL-DNN)和深度学习推理 SDK 优化(Intel OpenVINO)两种方式 。 这两种方式均包含了 SIMD 指令集的加速 。
数学库优化对主流的深度学习框架(tensorflow , caffe , mxnet , pytorch 等)均有官方源支持 。 以 tensorflow 为例 , 使用方法如下所示: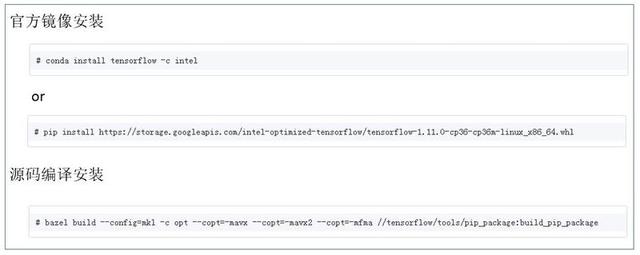 文章插图
文章插图
图 7. 基于 MKL-DNN 优化的 Tensorflow 使用方法
深度学习推理 SDK 优化方法 , 需要首先将原生深度学习模型进行转换 , 生成 IR 中间模型格式 , 之后调用 SDK 的接口进行模型加载和推理服务封装 。 具体流程如下所示: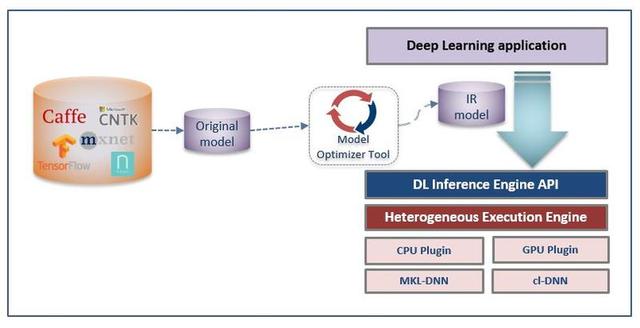 文章插图
文章插图
图 8. OpenVINO 优化推理服务流程
2.3 选用哪种系统级优化方式?
两种优化方式的比较如图 9 所示: 文章插图
文章插图
图 9. 系统级优化方式比较
基于两种优化方式的特点 , 实践中可首先使用基于 MKL-DNN 的优化方式进行服务性能测试 , 如满足服务需求 , 可直接部署;对于性能有更高要求的服务 , 可尝试进行 OpenVINO SDK 优化的方法 。
2.4 系统级优化使用中有哪些影响性能的因素?
以上两种系统级优化方法 , 使用过程中有以下因素会影响服务性能 。
(1)OpenMP 参数的设置
两种推理优化方式均使用了基于 OMP 的并行计算加速 , 因此 OMP 参数的配置对性能有较大的影响 。 主要参数的推荐配置如下所示:
? OMP_NUM_THREADS = “number of cpu cores in container”
? KMP_BLOCKTIME = 10
? KMP_AFFINITY=granularity=fine, verbose, compact,1,0
(2)部署服务的 CPU 核数对性能的影响
CPU 核数对推理服务性能的影响主要是:
? Batchsize 较小时(例如在线类服务) , CPU 核数增加对推理吞吐量提升逐渐减弱 , 实践中根据不同模型推荐 8-16 核 CPU 进行服务部署;
? Batchsize 较大时(例如离线类服务) , 推理吞吐量可随 CPU 核数增加呈线性增长 , 实践中推荐使用大于 20 核 CPU 进行服务部署;
(3)CPU 型号对性能的影响
不同型号的 CPU 对推理服务的性能加速也不相同 , 主要取决于 CPU 中 SIMD 指令集 。 例如相同核数的 Xeon Gold 6148 的平均推理性能是 Xeon E5-2650 v4 的 2 倍左右 , 主要是由于 6148 SIMD 指令集由 avx2 升级为 avx-512 。
目前线上集群已支持选择不同类型的 CPU 进行服务部署 。
(4)输入数据格式的影响
除 Tensorflow 之外的其他常用深度学习框架 , 对于图像类算法的输入 , 通常推荐使用 NCHW 格式的数据作为输入 。 Tensorflow 原生框架默认在 CPU 上只支持 NHWC 格式的输入 , 经过 MKL-DNN 优化的 Tensorflow 可以支持两种输入数据格式 。
使用以上两种优化方式 , 建议算法模型以 NCHW 作为输入格式 , 以减少推理过程中内存数据重排带来的额外开销 。
(5)NUMA 配置的影响
对于 NUMA 架构的服务器 , NUMA 配置在同一 node 上相比不同 node 上性能通常会有 5%-10% 的提升 。
2.5 如何进行应用级的优化?
进行应用级的优化 , 首先需要将应用端到端的各个环节进行性能分析和测试 , 找到应用的性能瓶颈 , 再进行针对性优化 。 性能分析和测试可以通过加入时间戳日志 , 或者使用时序性能分析工具 , 例如 Vtune , timeline 等。 优化方法主要包括并发和流水设计、数据预取和预处理、I/O 加速、特定功能加速(例如使用加速库或硬件进行编解码、抽帧、特征 embedding 等功能加速)等方式 。
下面以视频质量评估服务为例 , 介绍如何利用 Vtune 工具进行瓶颈分析 , 以及如何利用多线程 / 进程并发进行服务的优化 。
视频质量评估服务的基本流程如图 10 所示 , 应用读入一段视频码流 , 通过 OpenCV 进行解码、抽帧、预处理 , 之后将处理后的码流经过深度学习网络进行推理 , 最后通过推理结果的聚合得到视频质量的打分 , 来判定是何种类型视频 。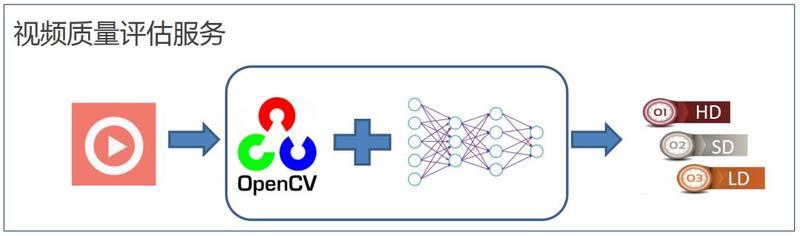 文章插图
文章插图
图 10. 视频质量评估服务流程
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- AI芯片“点燃”北京!GTIC 2020 AI芯片创新峰会大咖演讲全干货
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 如何基于Python实现自动化控制鼠标和键盘操作
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 蓝鲸专访|水滴CTO邱慧:基于业务场景做技术创新,用户需求可分析并唤醒
- 小店|抖音小店无货源模式,干货来了,抖音小店店群怎么做?
- Python编程:一个基于PyQt的Led控件库,建议收藏
- 干货:阿里巴巴提升组织能力的5大经典管理工具
- 终于活成了安兔兔?3DMark新增跨平台GPU测试项目