GPU|干货|基于 CPU 的深度学习推理部署优化实践( 三 )
图 11 是通过 Vtune 工具抓取的原始应用线程 , 可以看到 OpenCV 单一解码线程一直处于繁忙状态(棕色) , 而 OMP 推理线程常常处于等待状态(红色) 。 整个应用的瓶颈位于 Opencv 的解码及预处理部分 。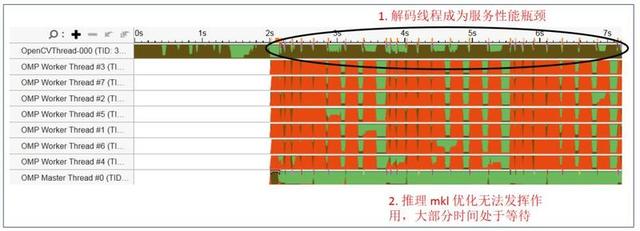 文章插图
文章插图
图 11. 应用优化前线程状态
图 12 显示优化后的服务线程状态 , 通过生成多个进程并发进行视频流解码 , 并以 batch 的方式进行预处理;处理后的数据以 batch 的方式传入 OMP threads 进行推理来进行服务的优化 。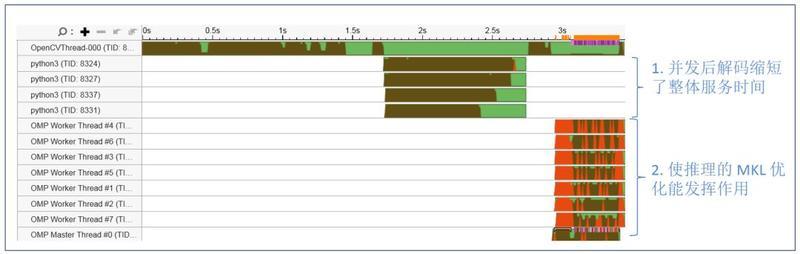 文章插图
文章插图
图 12. 应用并发优化后线程状态
经过上述简单的并发优化后 , 对 720 帧视频码流的处理时间 , 从 7 秒提升到了 3.5 秒 , 性能提升一倍 。 除此之外 , 我们还可以通过流水设计 , 专用解码硬件加速等方法进一步提升服务整体性能 。
2.6 如何进行算法级的优化?
常见的算法级优化提升推理服务性能的方法包括 batchsize 的调整、模型剪枝、模型量化等 。 其中模型剪枝和量化因涉及到模型结构和参数的调整 , 通常需要算法同学帮助一起进行优化 , 以保证模型的精度能满足要求 。
2.7 Batchsize 的选取在 CPU 上对服务性能的影响是怎样的?
Batchsize 选取的基本原则是延时敏感类服务选取较小的 batchsize , 吞吐量敏感的服务选取较大的 batchsize 。
图 13 是选取不同的 batchsize 对推理服务吞吐量及延时的影响 。 测试结果可以看 batchsize 较小时适当增大 batchsize(例如 bs 从 1 到 2) , 对延时的影响较小 , 但是可以迅速提升吞吐量的性能;batchsize 较大时再增加其值(例如从 8 到 32) , 对服务吞吐量的提升已没有帮助 , 但是会极大影响服务延时性能 。 因此实践中需根据部署服务节点 CPU 核数及服务性能需求来优化选取 batchsize 。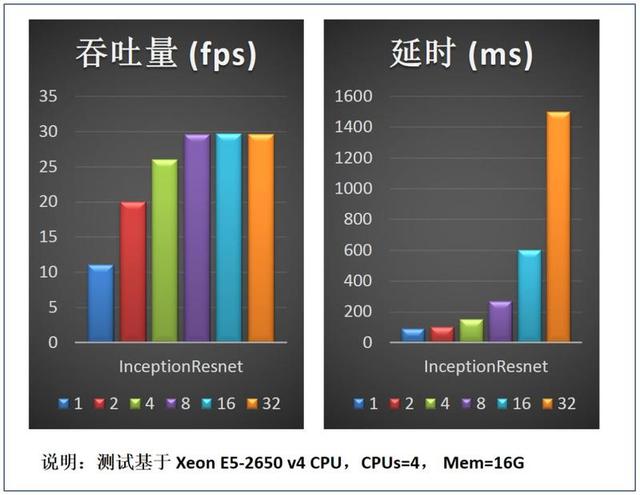 文章插图
文章插图
图 13. Batchsize 对服务性能影响
总结与展望以上介绍的系统级优化方法 , 已在深度学习云平台落地超过 10+ 应用和算法 , 部署上千 core 的服务 , 平均性能提升在 1~9 倍 。 更详细的使用方法可以参考文末相关链接 。
对于深度学习的推理服务优化 , 深度学习云平台还计划加入更多的异构计算资源来加速特定任务 , 例如 VPU、FPGA 等计算资源 。 同时在服务的弹性和优化调度、部署参数的自动优化选取等方面 , 我们也会继续深入优化 , 以充分发挥云平台的计算资源和能力 , 加速深度学习推理服务的落地 。
相关链接
(1)OpenVINO:
(2)Vtune 性能分析工具:
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- AI芯片“点燃”北京!GTIC 2020 AI芯片创新峰会大咖演讲全干货
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 如何基于Python实现自动化控制鼠标和键盘操作
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 蓝鲸专访|水滴CTO邱慧:基于业务场景做技术创新,用户需求可分析并唤醒
- 小店|抖音小店无货源模式,干货来了,抖音小店店群怎么做?
- Python编程:一个基于PyQt的Led控件库,建议收藏
- 干货:阿里巴巴提升组织能力的5大经典管理工具
- 终于活成了安兔兔?3DMark新增跨平台GPU测试项目