按关键词阅读:
 文章插图
文章插图
作者 | 顾荣Photo Creidt @ 轻零
导读:为了解决大数据、AI 等数据密集型应用在云原生计算存储分离场景下 , 存在的数据访问延时高、联合分析难、多维管理杂等痛点问题 , 南京大学 PASALab、阿里巴巴、Alluxio 在 2020 年 9 月份联合发起了开源项目 Fluid 。
近期 Fluid 0.4 版本正式发布 , 主要新增了以下四项重要功能 , 分别是:
- 通过 DataLoad 自定义资源 , 提供简单易用且可定制的数据预热能力
- 增强海量小文件数据集的支撑能力 , 扩展 Fluid 对 AI 应用的支持场景
- 开放 HDFS 文件系统兼容接口 , 支持 Spark 等框架的数据访问
- 支持多数据集单节点混合部署 , 适应生产环境中的共享集群环境
与 Fluid 0.3 类似 , 上述功能的开发需求同样来自众多社区用户的生产实际反馈 , 此外 , Fluid v0.4 还进行了一些 bug 修复和文档更新 , 欢迎使用体验 Fluid v0.4!感谢为此版本做出贡献的社区小伙伴 , 在接下来的版本功能迭代中 , 我们会继续广泛关注和采纳社区建议 , 推动 Fluid 项目的发展 , 期待听到大家更多的反馈!下文是本次新版本发布功能的进一步介绍 。
支持主动的数据预热在进行 AI 应用的模型训练时 , 数据预热是一种常见的优化手段 。 数据预热是指在应用运行前 , 将应用所需要的数据预先从远程存储系统中拉取到本地的计算集群 , 供之后应用运行时使用 。 数据预热通过一种顺序的、有规则的并行数据读取模式 , 避免了数据密集型应用直接消费远程存储系统数据时 , 因为随机数据读取造成的许多不必要的通信开销 。
因此 , 在 Fluid 0.4 版本中 , 我们实现了一个新的 Kubernetes 自定义资源 - DataLoad , 以 Kubernetes 资源的方式为用户提供了声明式的 API 接口 , 以控制数据预热的相关行为 。 DataLoad 自定义资源的一个简单示例如下所示:
apiVersion: data.fluid.io/v1alpha1kind: DataLoadmetadata:name: imagenet-dataloadspec:dataset:name: imagenetnamespace: default【Fluid0.4新版本正式发布:支持数据预热,优化小文件场景】另外 , 通过少量的额外配置 , DataLoad 还可实现子目录加载、缓存副本数量控制、元数据同步等许多可定制的功能 , 更多与 DataLoad 使用相关的细节请参考 Github 上的示例文档 。有关 DataLoad 使用与优化效果的演示视频如下:
增强海量小文件数据集的支撑能力Fluid 是云原生环境下数据密集型应用的高效支撑平台 , 因此我们自始至终都在密切关注着 Fluid 提供的数据集支撑能力在不同场景下的适用性 。 在 Fluid 0.4 版本之前 , Fluid 已经提供了诸如抽象、管理、加速、可观测性等一系列数据集支撑能力 , 然而 , 根据社区成员的使用反馈 , 上述能力在海量小文件场景下的支持还是非常初级 。
考虑到海量小文件数据集在真实生产环境 , 尤其是 AI 应用场景的普遍性 , 我们对海量小文件带来的问题进行了深入的探究 , 提出了如异步元数据加载查询、流式数据处理等解决方案 , 这些解决方案目前均已集成至 Fluid 0.4 版本中 , 以增强 Fluid 对海量小文件数据集的支撑能力 。
以下是 Fluid 使用 Alluxio Runtime 在 400 万小文件场景下的优化后的部分性能对比评估结果:
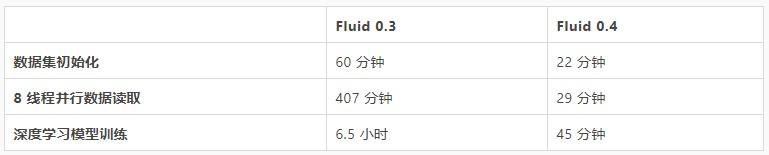 文章插图
文章插图海量小文件的存储管理是许多存储系统都会遇到的棘手难题 , 在后续的版本中 , 我们会继续关注这个场景以及它所带来的问题 。
方便 Spark 等大数据计算框架提供数据访问支持除了 AI 应用外 , Fluid 0.4 同样支持 Spark 等大数据应用在其上运行 。 通过向用户暴露 Alluxio 分布式缓存引擎的 Hadoop 文件系统兼容接口 (HCFS) , 使得 Hadoop MapReduce, Apache Spark 等大数据计算框架编写的数据分析应用 , 能够在不修改应用代码的情况下 , 直接运行于 Fluid 之上 , 并享受到由 Fluid 提供的分布式缓存加速等能力 。
更多关于通过 HCFS 接口访问数据的细节 , 请参考 Github 上的示例文档 。
多数据集单节点混合部署在真实的生产环境中 , 用户会在 Kubernetes 集群中的 GPU 节点上训练多个任务使用多个数据集 , 在 Fluid 0.4 版本之前 , 单节点无法同时进行多个数据集的混合部署 , 因此 , 如果多个用户同时期望在同一个节点访问各自所需的数据集 , 会出现某个用户的数据集无法创建的情况 。
在 Fluid 0.4 版本中 , 我们为 Fluid 增加了多数据集单节点混合部署的能力 , 这意味着 , 只要该节点上的资源足够 , 来自不同用户的多个数据集部署冲突的问题将不再发生 , 该能力将使得 Fluid 更加适应实际生产环境的需求 。 另一方面 , 混合部署能够有效利用空闲资源 , 增加集群中各个节点的集群资源利用率 , 进一步提高 Fluid 带来的成本收益 。
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2X3H020.html
标题:Fluid0.4新版本正式发布:支持数据预热,优化小文件场景