模型|重点!11个重要的机器学习模型评估指标( 二 )
这看似很简单 。 然而在有些情况下 , 数据科学家更关心查准率和查全率的问题 。 稍稍改变上面的表达式 , 包含一个可调参数β来实现该目的 , 得出: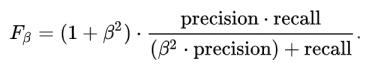 文章插图
文章插图
Fbeta衡量模型对用户的有效性 , 用户对查全率的重视程度是查准率的β倍 。 文章插图
文章插图
3. 增益图和提升图
增益图和提升图主要用于检查概率的顺序 。 以下是构建提升图/增益图的步骤:
步骤1:计算每个样本的概率 。
步骤2:按降序排列这些概率 。
步骤3:每组构建十分位数时都有近10%的样本 。
步骤4:计算每个十分位数的响应率 , 分为Good( Responders )、Bad( Non-responders )和总数 。
你会获得下表 , 需要据此绘制增增益图或提升图: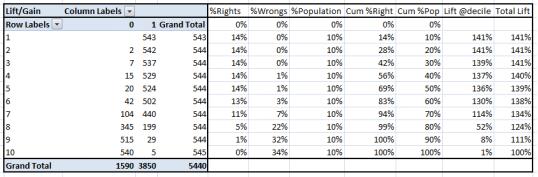 文章插图
文章插图
表格提供了大量信息 。 累积增益图介于累计 %Right和累计 %Population图之间 。 下面是对应的案例图: 文章插图
文章插图
该图会告诉你的模型responders与non-responders的分离程度 。 例如 , 第一个十分位数有10%的数量 , 和14%的responders 。 这意味着在第一个十分位数时有140%的升力 。
在第一个十分位数可以达到的最大升力是多少?从第一个表中可以知道responders的总数是3,850人 , 第一个十分位数也包含543个样本 。 因此 , 第一个十分位数的最大升力值可能是543/3850约为14.1% 。 所以该模型近乎完美 。
现在绘制升力曲线 。 升力曲线是总升力和 %population之间的关系曲线 。 注意:对于随机模型 , 此值始终稳定在100%处 。 这是目前案例对应的提升图: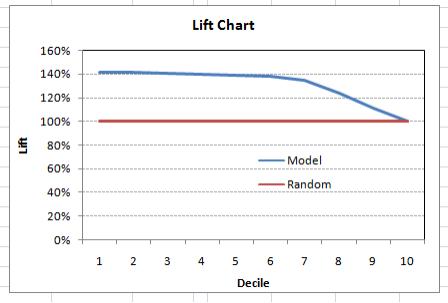 文章插图
文章插图
也可以使用十分位数绘制十分位升力: 文章插图
文章插图
这个图说明什么?这表示模型运行到第7个十分位数都挺好 。 每个十分位数都会倾向non-responders 。 在3分位数和7分位数之间 , 任何升力在100%以上的模型(@十分位数)都是好模型 。 否则可能要先考虑采样 。
提升图或增益图表广泛应用于目标定位问题 。 这告诉我们 , 在特定的活动中 , 可以锁定客户在哪个十分位数上 。 此外 , 它会告诉你对新目标数据期望的响应量 。文章插图
4. K-S图
K-S或Kolmogorov-Smirnov图表衡量分类模型的性能 。 更准确地说 , K-S是衡量正负例分布分离程度的指标 。 如果分数将人数划分为单独两组 , 其中一组含所有正例 , 另一组含所有负例 , 则K-S值为100 。
另一方面 , 如果模型不能区分正例和负例 , 那么就如同模型从总体中随机选择案例一样 , K-S为0 。 在大多数分类模型中 , K-S值将从0和100之间产生 , 并且值越高 , 模型对正例和负例的区分越好 。
对于以上案例 , 请看表格: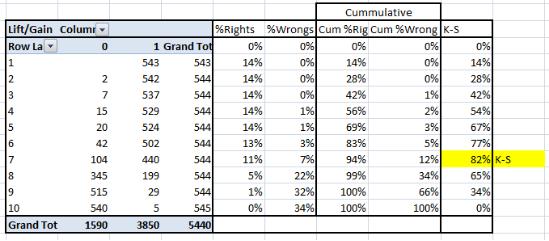 文章插图
文章插图
还可以绘制 %Cumulative Good和Bad来查看最大分离 。 下面是示例图: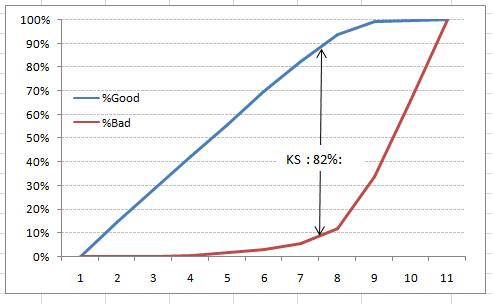 文章插图
文章插图
到目前为止 , 所涵盖的指标主要用于分类问题 。 直到这里 , 已经了解了混淆矩阵、增益图和提升图以及kolmogorov-smirnov图 。 接下来继续学习一些更重要的指标 。文章插图
5. AUC曲线( AUC-ROC )
这又是业内常用的指标之一 。 使用ROC曲线的最大优点是不受responders比例变化的影响 。 下文会讲得更清楚 。
首先试着去理解什么是ROC(接收器操作特性)曲线 。 如果看下面的混淆矩阵 , 就会观察到对于概率模型 , 每个指标的值不同 。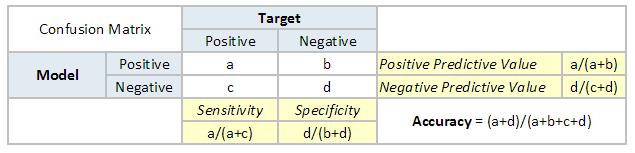 文章插图
文章插图
因此 , 对于每种敏感度 , 都会有不同的特异度 。 两者差异如下: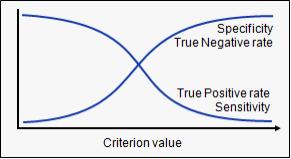 文章插图
文章插图
ROC曲线是敏感度和(1-特异度)之间的曲线 。 (1-特异性)也称为假正率 , 敏感度也称为真正率 。 下图本案例的ROC曲线 。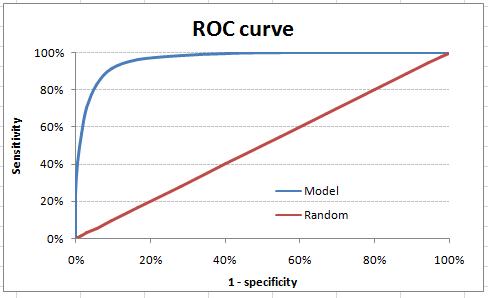 文章插图
文章插图
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 智慧|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 建筑|国产第一台掘进机模型亮相“2020长江·三峡建筑产业博览会”
- 家庭|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 「数据架构」TOGAF建模:概念数据模型图
- 五种IO模型详解
- 老年人助听器选配需重点注意哪些?
- 用模型再骗20亿美金?又一个造车界大忽悠被扒
- 头文件|阿里面试题 | Nginx 所使用的 epoll 模型是什么?