模型|重点!11个重要的机器学习模型评估指标( 五 )
以下是Kaggle得分的一个例子!
对于TFI比赛 , 以下是个人的三个解决方案和分数(越小越好):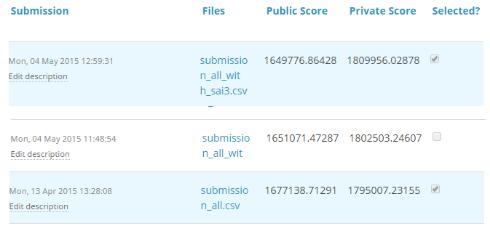 文章插图
文章插图
可以注意到 , 公共分数最差的第三个条目成为了私人排行榜上的最佳模型 。 “submission_all.csv”之前有20多个模型 , 但笔者仍然选择“submission_all.csv”作为最终条目(实践证明确实很有效) 。 是什么导致了这种现象?笔者的公共和私人排行榜的差异是过度拟合造成的 。
模型变得高度复杂时 , 过度拟合也会开始捕捉噪音 。 这种“噪音”对模型没有任何价值 , 只会让其准确度降低 。
下一节中 , 笔者将讨论在真正了解测试结果之前 , 如何判断解决方案是否过度拟合 。
概念:交叉验证
交叉验证是任何类型数据建模中最重要的概念之一 。 就是说 , 试着留下一个样本集 , 但并不在这个样本集上训练模型 , 在最终确定模型之前测试依据该样本集建立的模型 。 文章插图
文章插图
上图显示了如何使用及时样本集验证模型 。 简单地将人口分成2个样本 , 在一个样本上建立模型 。 其余人口用于及时验证 。
上述方法会有不好的一面吗?
这种方法一个消极面就是在训练模型时丢失了大量数据 。 因此 , 模型的偏差会很大 。 这不会给系数做出最佳估测 。 那么下一个最佳选择是什么?
如果 , 将训练人口按50:50的比例分开 , 前50用于训练 , 后50用于验证 。 然后两组颠倒过来进行实验 。 通过这种方式 , 在整个人口基础上训练模型 , 但一次只借用50% 。 这样可以减少偏差 , 因为样品选择在一定程度上可以提供较小的样本来训练模型 。 这种方法称为2折交叉验证 。
k折交叉验证
最后一个例子是从2折交叉验证推断到k折交叉验证 。 现在 , 尝试将k折交叉验证的过程可视化 。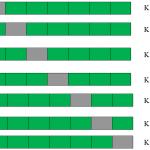 文章插图
文章插图
这是一个7折交叉验证 。
真实情况是这样:将整个人口划分为7个相同的样本集 。 现在在6个样本集(绿色框)上训练模型 , 在1个样本集(灰色框)上进行验证 。 然后 , 在第二次迭代中 , 使用不同的样本集训练模型作为验证 。 在7次迭代中 , 基本上在每个样本集上都构建了模型 , 同时作为验证 。 这是一种降低选择偏差、减少预测方差的方法 。 一旦拥有所有这7个模型 , 就可以利用平均误差项找到最好的模型 。
这是如何帮助找到最佳(非过度拟合)模型的?
k折交叉验证广泛用于检查模型是否是过度拟合 。 如果k次建模中的每一次的性能指标彼此接近 , 那么指标的均值最高 。 在Kaggle比赛中 , 你可能更多地依赖交叉验证分数而不是Kaggle公共分数 。 这样就能确保公共分数不单单是偶然出现 。
如何使用任何型号实现k折?
R和Python中的k折编码非常相似 。 以下是在Python中编码k-fold的方法:
from sklearn import cross_validation model = RandomForestClassifier(n_estimators=100) #Simple K-Fold cross validation. 5 folds. #(Note: in older scikit-learn versions the "n_folds" argument is named "k".) cv = cross_validation.KFold(len(train), n_folds=5, indices=False) results = [] # "model" can be replaced by your model object # "Error_function" can be replaced by the error function of your analysis for traincv, testcv in cv: probas = model.fit(train[traincv], target[traincv]).predict_proba(train[testcv]) results.append( Error_function ) #print out the mean of the cross-validated results print "Results: " + str( np.array(results).mean() )
但是如何选择k呢?
这是棘手的部分 。 需要权衡来选择k 。
对于小k , 有更高的选择偏差但性能差异很小 。
对于大k , 有小的选择偏差但性能差异很大 。
想想极端情况:
k = 2:只有2个样本 , 类似于50-50个例子 。 在这里 , 每次仅在50%的人口中构建模型 。 但由于验证会有很多人 , 所以 验证性能的差异是最小的 。
k =样本数( n ):这也称为“留一法” 。 有n次样本 , 建模重复n次 , 只留下一个样本集进行交叉验证 。 因此 , 选择偏差很小 , 但验证性能的差异非常大 。
通常 , 针对大多数情况 , 建议使用k = 10的值 。 文章插图
文章插图
结语
在训练样本上评估模型毫无意义 。 留出大量的样本来验证模型也是在浪费数据 。 k折交叉验证为我们提供了一种使用单个数据点的方法 , 可以在很大程度上减少选择偏差 。 同时 , K折交叉验证可以与任何建模技术一起使用 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 智慧|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 建筑|国产第一台掘进机模型亮相“2020长江·三峡建筑产业博览会”
- 家庭|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 「数据架构」TOGAF建模:概念数据模型图
- 五种IO模型详解
- 老年人助听器选配需重点注意哪些?
- 用模型再骗20亿美金?又一个造车界大忽悠被扒
- 头文件|阿里面试题 | Nginx 所使用的 epoll 模型是什么?