监督学习和kNN分类初学者教程( 二 )
我来给你看看这个分数是怎么计算的 。 首先 , 我们使用knn模型对X_test特征进行预测 。 然后与实际标签进行比较 。 以下是在后台实际计算准确度的方法:
y_pred = knn.predict(X_test)number_of_equal_elements = np.sum(y_pred==y_test)number_of_equal_elements/y_pred.shape[0] 文章插图
文章插图
过拟合与欠拟合以下是我在Amazon机器学习课程文档中发现的模型过拟合和欠拟合的一个很好的解释:
“当模型在训练数据上表现不佳时 , 模型对训练数据的拟合不足 。 这是因为模型无法捕获输入示例(特性)和目标值(标签)之间的关系 。 当你看到模型在训练数据上表现良好 , 但在评估数据上表现不佳时 , 该模型会过拟合你的训练数据 。 这是因为模型正在记忆它所看到的数据 , 并且无法将其推广到未看到的示例中 。 ”
现在 , 让我们编写一个for循环 , 它将帮助我们了解数据在不同的邻居值中的表现 。 此函数还将帮助我们分析模型的最佳性能 , 这意味着更准确的预测 。
neighbors = np.arange(1, 9)train_accuracy = np.empty(len(neighbors))test_accuracy = np.empty(len(neighbors))for i, k in enumerate(neighbors):# 定义knn分类器knn = KNeighborsClassifier(n_neighbors = k)# 将分类器与训练数据相匹配knn.fit(X_train, y_train)# 在训练集上计算准确度train_accuracy[i] = knn.score(X_train, y_train)# 在测试集上计算准确度test_accuracy[i] = knn.score(X_test, y_test)现在 , 让我们用图形表示结果:
plt.title('k-NN: Performance by Number of Neighbors') plt.plot(neighbors, test_accuracy, label = 'Testing Accuracy') plt.plot(neighbors, train_accuracy, label = 'Training Accuracy') plt.legend() plt.xlabel('# of Neighbors') plt.ylabel('Accuracy') plt.show()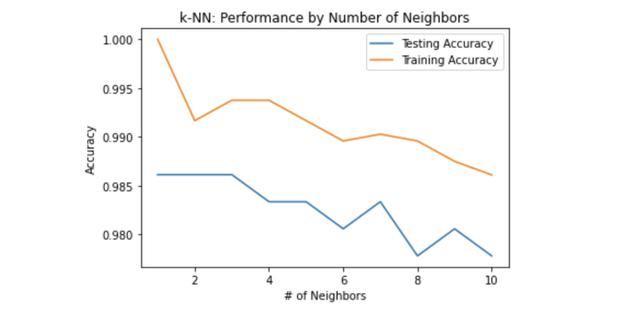 文章插图
文章插图
这个图证明了更多的邻居并不总是意味着更好的性能 。 当然 , 这主要取决于模型和数据 。 在我们的例子中 , 正如我们所看到的 , 1-3个邻居准确度是最高的 。 之前 , 我们用7个邻居训练了knn模型 , 得到了0.983的准确度 。 所以 , 现在我们知道我们的模型在两个邻居的情况下表现更好 。 让我们重新训练我们的模型 , 看看我们的预测将如何改变 。
knn = KNeighborsClassifier(n_neighbors = 2) knn.fit(X_train, y_train) print(knn.score(X_test, y_test)) 文章插图
文章插图
结论【监督学习和kNN分类初学者教程】很完美!你已经使用scikit learn模块创建了一个监督学习分类器 。 我们还学习了如何检查分类器模型的性能 。 我们还学习了过拟合和欠拟合 , 这使我们能够改进预测 。 深度学习是如此有趣和神奇 。 我将分享更多深入学习的文章 。 敬请期待!
- 中国|浅谈5G移动通信技术的前世和今生
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 二维码|村网通?澳大利亚一州推出疫情追踪二维码 还考虑采用人脸识别和地理定位
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 花15.5亿元与中粮包装握手言和 加多宝离上市又进一步?|15楼财经 | 清远加多宝
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐
- 内容|浅谈内容行业的一些规律和壁垒,聊聊电商平台孵化小红书难点(外部原因)