bilibili 实时计算平台架构与实践
【bilibili 实时计算平台架构与实践】基于对 bilibili 实时计算的痛点分析 , 详细介绍了 bilibili Saber 实时计算平台架构与实践 。 本次分享主要围绕以下四个方面:实时计算的痛点、Saber 的平台演进、结合 AI 的案例实践、未来的发展与思考 。
01
实时计算的痛点
1. 痛点
各个业务部门进行业务研发时都有实时计算的需求 。 早期 , 在没有平台体系做支撑时开发工作难度较大 , 由于不同业务部门的语言种类和体系不同 , 导致管理和维护非常困难 。 其次 , bilibili 有很多关于用户增长、渠道投放的分析等 BI 分析任务 。 而且还需要对实时数仓的实时数据进行清洗 。 此外 , bilibili 作为一个内容导向的视频网站 , AI 推荐场景下的实时计算需求也比较强烈 。
2. 痛点共性
- 开发门槛高:基于底层实时引擎做开发 , 需要关注的东西较多 。 包括环境配置、语言基础 , 而编码过程中还需要考虑数据的可靠性、代码的质量等 。 其次 , 市场实时引擎种类多样 , 用户选择有一定困难 。
 文章插图
文章插图- 运维成本高:运维成本主要体现在两方面 。 首先是作业稳定性差 。 早期团队有 Spark 集群、YARN 集群 , 导致作业稳定性差 , 容错等方面难以管理 。 其次 , 缺乏统一的监控告警体系 , 业务团队需要重复工作 , 如计算延时、断流、波动、故障切换等 。
 文章插图
文章插图- AI 实时工程难:bilibili 客户端首页推荐页面依靠 AI 体系的支撑 , 早期在 AI 机器学习方面遇到非常多问题 。 机器学习是一套算法与工程交叉的体系 。 工程注重的是效率与代码复用 , 而算法更注重特征提取以及模型产出 。 实际上 AI 团队要承担很多工程的工作 , 在一定程度上十分约束实验的展开 。 另外 , AI 团队语言体系和框架体系差异较大 , 所以工程是基建体系 , 需要提高基建才能加快 AI 的流程 , 降低算法人员的工程投入 。
 文章插图
文章插图3. 基于 Apache Flink 的流式计算平台
为解决上述问题 , bilibili 希望根据以下三点要求构建基于 Apache Flink 的流式计算平台:
- 第一点 , 需要提供 SQL 化编程 。 bilibili 对 SQL 进行了扩展 , 称为 BSQL 。 BSQL 扩展了 Flink 底层 SQL 的上层 , 即 SQL 语法层 。
- 第二点 , DAG 拖拽编程,一方面用户可以通过画板来构建自己的 Pipeline , 另一方面用户也可以使用原生 Jar 方式进行编码 。
- 第三点 , 作业的一体化托管运维 。
 文章插图
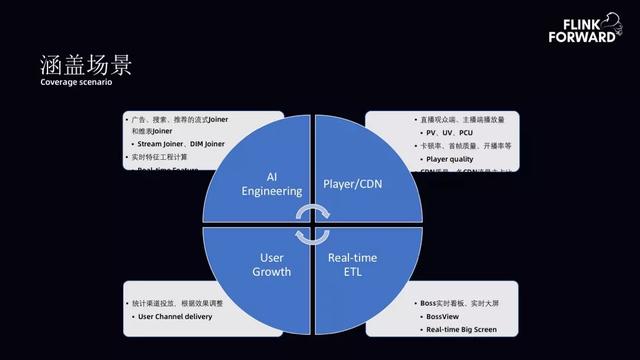
文章插图涵盖场景:bilibili 流式计算平台主要涵盖四个方面的场景 。
- AI 工程方向 , 解决了广告、搜索、推荐的流式 Joiner 和维表 Joiner;
- 实时计算的特征支持 , 支持 Player 以及 CDN 的质量监控 。 包括直播、PCU、卡顿率、CDN 质量等;
- 用户增长 , 即如何借助实时计算进行渠道分析、调整渠道投放效果;
- 实时 ETL , 包括 Boss 实时播报、实时大屏、看板等 。
 文章插图
文章插图02
Saber 的平台演进
1. 平台架构
实时平台由实时传输和实时计算两部分组成 , 平台底层统一管理元数据、血缘、权限以及作业运维等 。 实时传输主要负责将数据传入到大数据体系中 。 实时计算基于 BSQL 提供各种应用场景支持 。
如下图所示 , 实时传输有 APP 日志、数据库 Binlog、服务端日志或系统日志 。 bilibili 内部的 Lancer 系统解决数据落地到 Kafka 或 HDFS 。 计算体系主要围绕 Saber 构建一套 BSQL , 底层基于 YARN 进行调度管理 。
上层核心基于 Flink 构建运行池 。 再向上一层满足多种维表场景 , 包括 MySQL、Redis、HBase 。 状态(State)部分在 RocksDB 基础上 , 还扩展了 MapDB、Redis 。 Flink 需要 IO 密集是很麻烦的问题 , 因为 Flink 的资源调度体系内有内存和 CPU , 但 IO 单位未做统一管理 。 当某一个作业对 IO 有强烈的需求时 , 需要分配很多以 CPU 或内存为单位的资源 , 且未必能够很好的满足 IO 的扩展 。 所以本质上 bilibili 现阶段是将 IO 密集的资源的 State 转移到 Redis 上做缓解 。 数据经过 BSQL 计算完成之后传输到实时数仓 , 如 Kafka、HBase、ES 或 MySQL、TiDB 。 最终到 AI 或 BI、报表以及日志中心 。
- 计算机学科|机器视觉系统是什么
- 好友聊天|《QQ》能量值计算规则
- 研发|腾讯成立云计算西安分公司,将成总部之外最大云研发中心
- 动手做|动手做一个最简单的加法计算器
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- 腾讯最重要的云研发中心之一——腾讯云计算(西安)有限责任公司揭牌