bilibili 实时计算平台架构与实践( 四 )
 文章插图
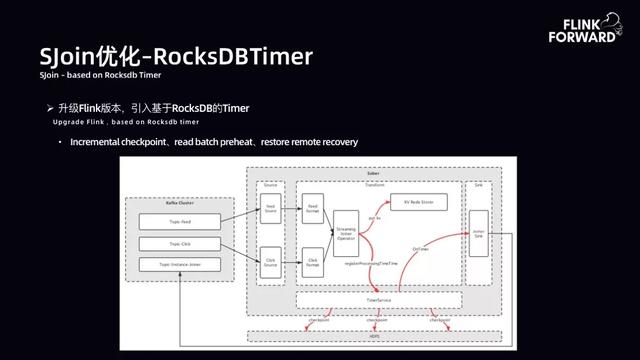
文章插图- SJoin 优化-RocksDBTimer:升级 Flink 版本 , 引入基于 RocksDB 的 Timer 。 升级后架构如下图所示 。 数据从 Kafka 获取 Topic-Feed 和 Topic-Click , 首先对其进行一层清洗 , 然后进入自定义的 Joiner Operator 算子 。 算子做两件事 , 将主流数据吐到 Redis 中 , 由 Redis 做 State , 同时将需要开窗口的 Key 存储注册到 Timer Service 中 。 接下来利用 Timer Service 原生的 CheckPoint 开启增量 CheckPoint 过程 。 当 OnTimer 到达时间后 , 就可以吐出数据 。 非常此方案契合 SJoin 在高吞吐作业下的要求 。
 文章插图
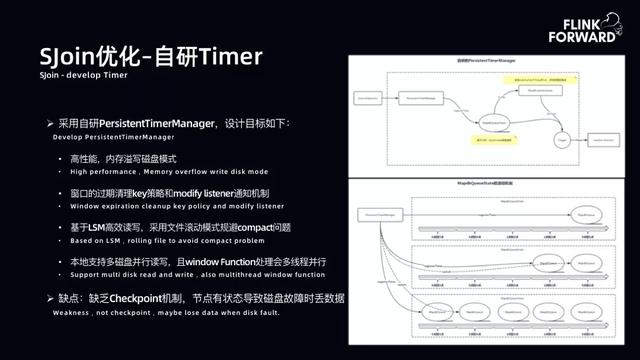
文章插图- SJoin 优化-引入 KVStore:Flink 原生 State 无法满足要求 , 在对 Value、IO 要求高时抖动严重 , RocksDBState 实际使用中会出现抖动问题 。 对此 , bilibili 尝试过多种改进方案 。 开 1 小时窗口 , 数据量约 700G , 双流 1 小时窗口总流量达到 TB 级别 。 采用分布式 KVStore 存储 , 后续进行压缩后数据量约 700G 。
 文章插图
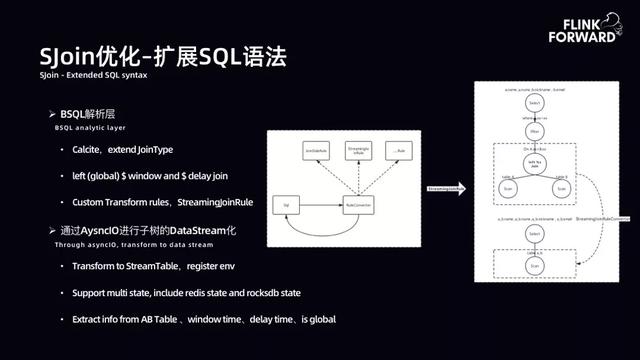
文章插图- SJoin 优化-扩展 SQL 语法:扩展 SQL 的功能诉求是展现流等待 1 小时窗口 , 当点击流到达时 , 不立即吐出 Join 完成的数据 , 而等待窗口结束后再吐出 。 故扩展了 SQL 语法 , 虽然目前未达到通用 , 但是能满足诸多部门的 AI 需求 。 语法支持 Select * from A left(global)$time window and $time delay join B on A.xx=B.xx where A.xx=xx 。 给用户带来了很大收益 。
 文章插图
文章插图进行 SQL 语义扩展主要有两个关键点 。 SQL 语义的定义顶层通过 Calcite 扩展 JoinType 。 首先将 SQL 展开成 SQL 树 。 SQL 树的一个节点为 left(global)$time window and $time delay join 。 抽取出该子树 , 自定义逻辑转换规则 。 在此定义了 StreamingJoinRute , 将该子树转换为新的节点 。 通过 Flink 提供的异步 IO 能力 , 将异步子树转换为 Streaming Table , 并将其注册到 Flink 环境中 。 通过以上过程支持 SQL 表达 。
 文章插图
文章插图- DJoin-工程背景:bilibili 对于维表数据要求不同 。 比如一些维表数据很大 , 以 T 为单位 , 此时如果用 Redis 存储会造成浪费 。 而有一些维表数据很小 , 如实时特征 。 同时 , 维表数据更新粒度不同 , 可以按天更新、按小时更新、按分钟更新等 。 另外 , 维表性能要求很高 。 因为 AI 场景会进行很多实验 , 例如某一个特征比较好 , 就会开很多模型、调整不同参数进行实验 。 单作业下实验组越多 , QPS 越高 , RT 要求越高 。 不同维表存储介质有差异 , 对稳定性有显著影响 。 调研中有两种场景 。 当量比较小 , 可以使用 Redis 存储 , 稳定性较好 。 当量很大 , 使用 Redis 成本高 , 但 HBase CP 架构无法保证稳定性 。
 文章插图
文章插图- DJoin-工程优化:需要针对维表 Join 的 SQL 进行语法支持 。 包括 Cache 优化 , 当用户写多条 SQL 的维表 Join 时 , 需要提取多条 SQL 维表的 Key , 并通过请求合并查询维表 , 以提高 IO , 以及流量均衡优化等 。 第二 , KV 存储分场景支持 , 比如 JDBC、KV 。 KV 场景中 , 对百 G 级别使用 Redis 实时更新实时查询 。 T 级别使用 HBase 多集群 , 比如通过两套 HBase , Failover+LoadBalance 模式保证 99 线 RT 小于 20ms , 以提高稳定性 。
 文章插图
文章插图- DJoin-语法扩展:DJoin 语法扩展与 SJoin 语法扩展类似 , 对 SQL 树子树进行转化 , 通过 AsyncIO 进行扩展 , 实现维表 。
- 计算机学科|机器视觉系统是什么
- 好友聊天|《QQ》能量值计算规则
- 研发|腾讯成立云计算西安分公司,将成总部之外最大云研发中心
- 动手做|动手做一个最简单的加法计算器
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- 腾讯最重要的云研发中心之一——腾讯云计算(西安)有限责任公司揭牌