bilibili 实时计算平台架构与实践( 三 )
 文章插图
文章插图
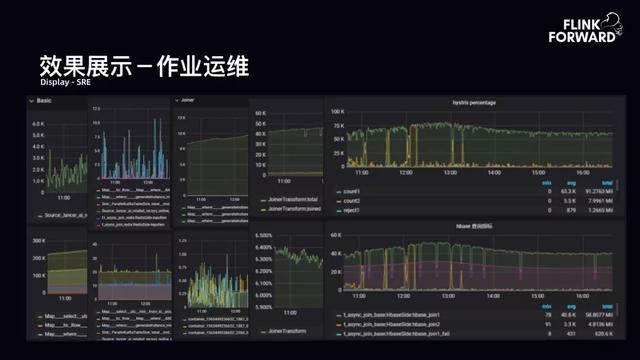
- 效果展示-作业运维:平台提供给用户一些监控指标、用户可自定义扩展的指标以及 bilibili 实现的一些特殊 SQL 的自定义指标 。 下图所示为部分队列的运行情况 。
 文章插图
文章插图03
结合 AI 的案例实践
1. AI - 机器学习现状
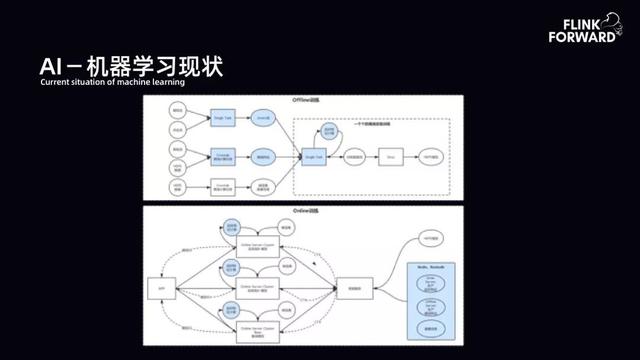
AI 体系中有 Offline 和 Online 过程 。 Online(线上训练)根据流量做 A/B 实验 , 根据不同实验的效果做推荐 。 同时每个实验需要有相应的模型 push 到线上 。 AI 的痛点集中在 Offline(离线训练) 。 Offline 则通过流式方式进行训练 。 下图是 Offline 流式训练早期情况 。 用户需要构建流和流的实时 join , 从而产出实时 label 流 。 而流和维表及特征信息的 join 来产出实时 instance 流 , 但早期相关的工程服务存在着单点问题 , 服务质量、稳定性带来的维护成本也很高 , 致使 AI 在早期 Pipeline 的构建下投入非常大 。
 文章插图
文章插图2. 弊端与痛点
- 数据时效性:数据时效性无法得到保证 。 很多数据是通过离线方式进行计算 , 但很多特征的时效性要求非常高 。
- 工程质量:单点工程不利于服务扩展以及稳定性保障 。
- 工程效率:每一个实验都有较高门槛 , 需要做 Label 生产 , Features 计算以及 Instance 拼接 。 在不同业务线 , 不同场景的推荐背后 , 算法同学做工程工作 。 他们掌握的语言不同 , 导致工程上语言非常乱 。 另外 , 流、批不一致 , 模型的训练在实时环境与离线批次环境的工程差异很大 , 其背后的逻辑相似 , 导致人员投入翻倍增长 。
构建一套基于 Saber-BSQL、Flink 引擎的数据计算 Pipeline , 极大简化 Instance 流的构建 。 其核心需要解决以下三个问题:Streaming Join Streaming(流式 SJoin) , Streaming Join Table(维表 DJoin) , Real-time Feature(实时特征) 。
 文章插图
文章插图- SJoin-工程背景:流量规模大 , 如 bilibili 首页推荐的流量 , AI 的展现点击 Join , 来自全站的点击量和展现 。 此外 , 不仅有双流 Join , 还有三流及以上的 Join , 如广告展现流、点击流、搜索查询流等 。 第三 , 不同 Join 对 ETL 的清洗不同 。 如果不能通过 SQL 的方式进行表达 , 则需要为用户提供通用的扩展 , 解决不同业务对 Join 之前的定制化 ETL 清洗 。 第四 , 非典型 A Left Join B On Time-based Window 模型 。 主流 A 在窗口时间内 Join 成功后 , 需要等待窗口时间结束再吐出数据 , 延长了主流 A 在窗口的停留时间 。 此场景较为关键 , bilibili 内部不仅广告、AI、搜索 , 包括直播都需要类似的场景 。 因为 AI 机器学习需要正负样本均匀以保证训练效果 , 所以第四点问题属于强需求 。
- SJoin-工程规模:基于线上实时推荐 Joiner 。 原始 feed 流与 click 流 , QPS 高峰分别在 15w 和 2w , Join 输出 QPS 高峰达到 10w , 字节量高峰为 200 M/s 。 keyState 状态查询量维持在高峰值 60w , 包括 read、write、exist 等状态 。 一小时 window 下 , Timer 的 key 量 15w * 3600 = 54 亿条 , RocksDBState 量达到 200M * 3600 = 700G 。 实际过程中 , 采用原生 Flink 在该规模下会遇到较多的性能问题 , 如在早期 Flink 1.3.* 版本 , 其稳定性会较差 。
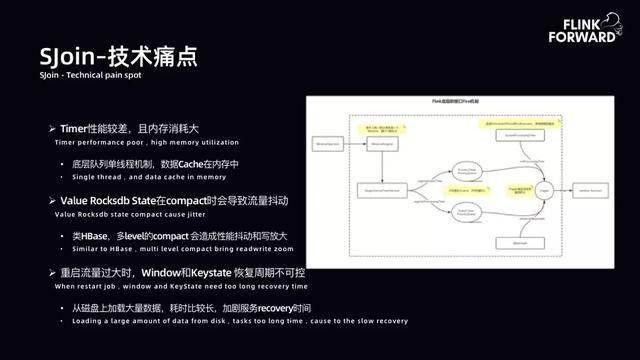
- SJoin-技术痛点:下图是 Flink 使用 WindowOperator 时的内部拓扑图 。 用户打开窗口 , 每一条记录都是一个 Window 窗口 。 第一个问题是窗口分配量巨大 , QPS 与窗口分配量基本持恒 。 第二个问题是 Timer Service 每一个记录都打开了一个窗口 , 在早期原生 Flink 中是一个内存队列 , 内存队列部分也存在许多问题 。 底层队列早期是单线程机制 , 数据 Cache 在内存中 , 存在许多问题 。
 文章插图
文章插图- SJoin-优化思路:首先是 Timer 优化升级 。 早期社区没有更好的解决方案时 , bilibili 尝试自研 PersistentTimerManager , 后期升级 Flink , 采用基于 RocksDB 的 Timer 。 第二 , 启用 Redis 作为 ValueState , 提高 State 稳定性 。 第三 , 扩展 SQL 语法 , 以支持非典型 A Left Join B On Time-based Window 场景下的 SQL 语义 。
- 计算机学科|机器视觉系统是什么
- 好友聊天|《QQ》能量值计算规则
- 研发|腾讯成立云计算西安分公司,将成总部之外最大云研发中心
- 动手做|动手做一个最简单的加法计算器
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- 腾讯最重要的云研发中心之一——腾讯云计算(西安)有限责任公司揭牌