浅析C# Dictionary实现原理( 二 )
1. 拉链法:这种方法的思路是将产生冲突的元素建立一个单链表 , 并将头指针地址存储至Hash表对应桶的位置 。 这样定位到Hash表桶的位置后可通过遍历单链表的形式来查找元素 。
2. 再Hash法:顾名思义就是将key使用其它的Hash函数再次Hash , 直到找到不冲突的位置为止 。
对于拉链法有一张图来描述 , 通过在冲突位置建立单链表 , 来解决冲突 。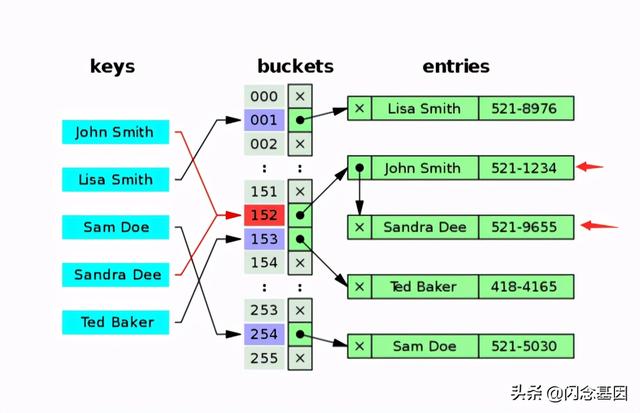 文章插图
文章插图
三、Dictionary实现Dictionary实现我们主要对照源码来解析 , 目前对照源码的版本是 .Net Framwork 4.7。 地址可戳一戳这个链接 源码地址:Link
这一章节中主要介绍Dictionary中几个比较关键的类和对象 , 然后跟着代码来走一遍插入、删除和扩容的流程 , 相信大家就能理解它的设计原理 。
1. Entry结构体首先我们引入 Entry 这样一个结构体 , 它的定义如下代码所示 。 这是Dictionary种存放数据的最小单位 , 调用 Add(Key,Value) 方法添加的元素都会被封装在这样的一个结构体中 。
private struct Entry {public int hashCode;// 除符号位以外的31位hashCode值, 如果该Entry没有被使用 , 那么为-1public int next;// 下一个元素的下标索引 , 如果没有下一个就为-1public TKey key;// 存放元素的键public TValue value;// 存放元素的值}2. 其它关键私有变量除了Entry结构体外 , 还有几个关键的私有变量 , 其定义和解释如下代码所示 。
private int[] buckets;// Hash桶private Entry[] entries; // Entry数组 , 存放元素private int count;// 当前entries的index位置private int version;// 当前版本 , 防止迭代过程中集合被更改private int freeList;// 被删除Entry在entries中的下标index , 这个位置是空闲的private int freeCount;// 有多少个被删除的Entry , 有多少个空闲的位置private IEqualityComparer comparer; // 比较器private KeyCollection keys;// 存放Key的集合private ValueCollection values;// 存放Value的集合上面代码中 , 需要注意的是 buckets、entries 这两个数组 , 这是实现Dictionary的关键 。
3. Dictionary - Add操作经过上面的分析 , 相信大家还不是特别明白为什么需要这么设计 , 需要这么做 。 那我们现在来走一遍Dictionary的Add流程 , 来体会一下 。
首先我们用图的形式来描述一个Dictionary的数据结构 , 其中只画出了关键的地方 。 桶大小为4以及Entry大小也为4的一个数据结构 。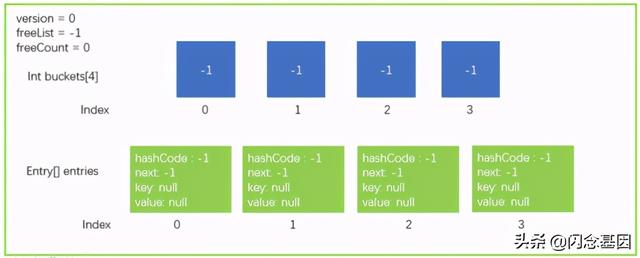 文章插图
文章插图
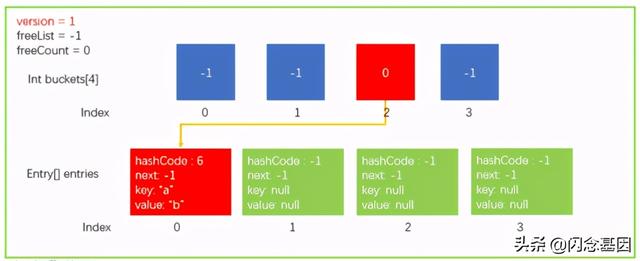
然后我们假设需要执行一个 Add 操作 ,dictionary.Add("a","b"), 其中 key = "a",value = "http://kandian.youth.cn/index/b"。
- 根据 key 的值 , 计算出它的hashCode 。 我们假设"a"的hash值为6( GetHashCode("a") = 6 ) 。
- 通过对hashCode取余运算 , 计算出该hashCode落在哪一个buckets桶中 。 现在桶的长度( buckets.Length )为4 , 那么就是 6 % 4 最后落在 index 为2的桶中 , 也就是 buckets[2]。
- 避开一种其它情况不谈 , 接下来它会将 hashCode、key、value 等信息存入 entries[count] 中 , 因为 count 位置是空闲的;继续 count++ 指向下一个空闲位置 。 上图中第一个位置 , index=0就是空闲的 , 所以就存放在 entries[0] 的位置 。
- 将 Entry 的下标 entryIndex 赋值给 buckets 中对应下标的 bucket。 步骤3中是存放在 entries[0] 的位置 , 所以 buckets[2]=0。
- 最后 version++, 集合发生了变化 , 所以版本需要+1 。只有增加、替换和删除元素才会更新版本上文中的步骤1~5只是方便大家理解 , 实际上有一些偏差 , 后文再谈Add操作小节中会补充 。
 文章插图
文章插图这样是理想情况下的操作 , 一个bucket中只有一个hashCode没有碰撞的产生 , 但是实际上是会经常产生碰撞;那么Dictionary类中又是如何解决碰撞的呢 。
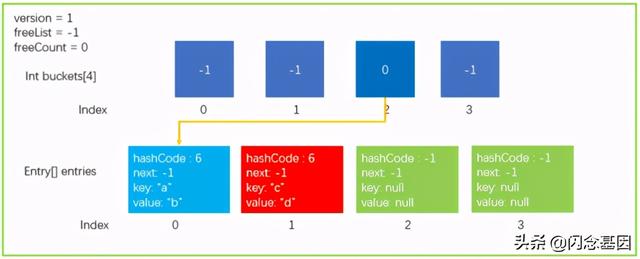
我们继续执行一个 Add 操作 ,dictionary.Add("c","d"), 假设 GetHashCode(“c”)=6, 最后 6 % 4 = 2。 最后桶的 index 也是2 , 按照之前的 步骤1~3 是没有问题的 , 执行完后数据结构如下图所示 。
 文章插图
文章插图如果继续执行 步骤4 那么 buckets[2] = 1, 然后原来的 buckets[2]=>entries[0] 的关系就会丢失 , 这是我们不愿意看到的 。 现在Entry中的 next 就发挥大作用了 。
如果对应的 buckets[index] 有其它元素已经存在 , 那么会执行以下两条语句 , 让新的 entry.next 指向之前的元素 , 让 buckets[index] 指向现在的新的元素 , 就构成了一个单链表 。
- 与用户|掌握好这4个步骤,实现了规模性的盈利
- 落地|“电竞之都”争夺战中,城市们该怎样实现产业落地?
- 美好生活|以人为本实现万物互融,中国视频社会化时代开启
- 手机|女神的自拍秘密,只需一部vivo S7便可以实现
- 自动任务|赶在三星 S21 发布之前实现语音解锁
- 产业|新主导力量来了,上海如何实现一次“革命性重塑”?
- Mate40Pro|华为Mate40Pro前置镜头有多强实现的这些功能国产机没人做到
- 突破|再传喜讯国产8英寸石墨烯晶圆亮相,中国芯再次实现新突破
- 如何基于Python实现自动化控制鼠标和键盘操作
- 小天才电话手表立体定位技术,真正实现无死角定位