浅析C# Dictionary实现原理( 四 )
从上文中大家都知道 , Hash运算会不可避免的产生冲突 , Dictionary中使用拉链法来解决冲突的问题 , 但是大家看下图中的这种情况 。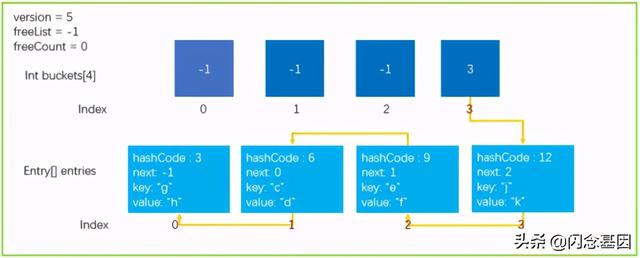 文章插图
文章插图
所有的元素都刚好落在 buckets[3] 上面 , 结果就是导致了 时间复杂度O(n), 查找性能会下降;所以 第二种 , Dictionary中发生的碰撞次数太多 , 会严重影响性能 ,也会触发扩容操作 。
目前.Net Framwork 4.7中设置的碰撞次数阈值为100.public const int HashCollisionThreshold = 100;6.2 扩容操作如何进行为了给大家演示的清楚 , 模拟了以下这种数据结构 , 大小为2的Dictionary , 假设碰撞的阈值为2;现在触发Hash碰撞扩容 。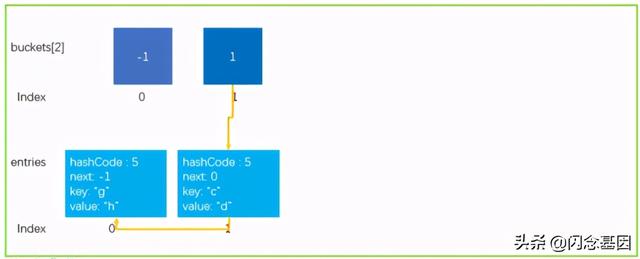 文章插图
文章插图
开始扩容操作 。
1.申请两倍于现在大小的buckets、entries
2.将现有的元素拷贝到新的entries
完成上面两步操作后 , 新数据结构如下所示 。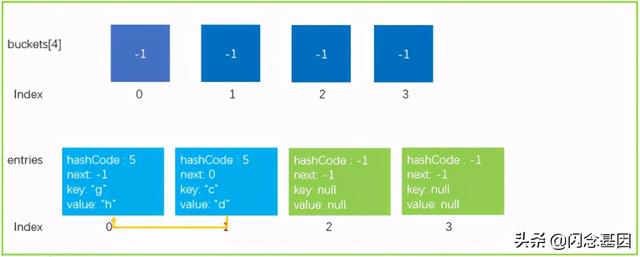 文章插图
文章插图
3、如果是Hash碰撞扩容 , 使用新HashCode函数重新计算Hash值上文提到了 , 这是发生了Hash碰撞扩容 , 所以需要使用新的Hash函数计算Hash值 。 新的Hash函数并一定能解决碰撞的问题 , 有可能会更糟 , 像下图中一样的还是会落在同一个 bucket 上 。 文章插图
文章插图
4、对entries每个元素bucket = newEntries[i].hashCode % newSize确定新buckets位置**5、重建hash链 , newEntries[i].next=buckets[bucket]; buckets[bucket]=i; **
因为 buckets 也扩充为两倍大小了 , 所以需要重新确定 hashCode 在哪个 bucket 中;最后重新建立hash单链表.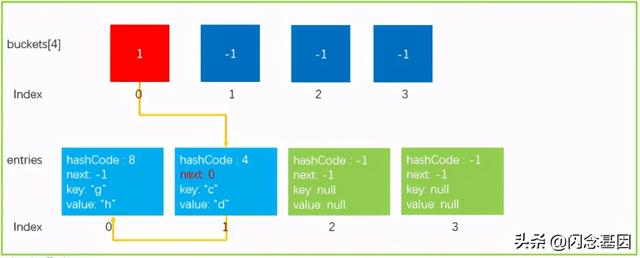 文章插图
文章插图
这就完成了扩容的操作 , 如果是达到 Hash碰撞阈值 触发的扩容可能扩容后结果会更差 。
在JDK中 ,HashMap 如果碰撞的次数太多了 , 那么会将 单链表转换为红黑树 提升查找性能 。 目前 .Net Framwork 中还没有这样的优化 ,.Net Core 中已经有了类似的优化 , 以后有时间在分享 .Net Core 的一些集合实现 。
每次扩容操作都需要遍历所有元素 , 会影响性能 。 所以创建Dictionary实例时最好设置一个预估的初始大小 。 private void Resize(int newSize, bool forceNewHashCodes) {Contract.Assert(newSize >= entries.Length);// 1. 申请新的Buckets和entriesint[] newBuckets = new int[newSize];for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1;Entry[] newEntries = new Entry[newSize];// 2. 将entries内元素拷贝到新的entries总Array.Copy(entries, 0, newEntries, 0, count);// 3. 如果是Hash碰撞扩容 , 使用新HashCode函数重新计算Hash值if(forceNewHashCodes) {for (int i = 0; i < count; i++) {if(newEntries[i].hashCode != -1) {newEntries[i].hashCode = (comparer.GetHashCode(newEntries[i].key)}}}// 4. 确定新的bucket位置// 5. 重建Hahs单链表for (int i = 0; i < count; i++) {if (newEntries[i].hashCode >= 0) {int bucket = newEntries[i].hashCode % newSize;newEntries[i].next = newBuckets[bucket];newBuckets[bucket] = i;}}buckets = newBuckets;entries = newEntries;}7. Dictionary - 再谈Add操作在我们之前的 Add 操作步骤中 , 提到了这样一段话 , 这里提到会有一种其它的情况 , 那就是 有元素被删除 的情况 。
- 避开一种其它情况不谈 , 接下来它会将 hashCode、key、value 等信息存入 entries[count] 中 , 因为 count 位置是空闲的;继续 count++ 指向下一个空闲位置 。 上图中第一个位置 , index=0就是空闲的 , 所以就存放在 entries[0] 的位置 。
这就是为什么 Remove 操作会记录 freeList、freeCount, 就是为了将删除的空间利用起来 。 实际上 Add 操作会优先使用 freeList 的空闲 entry 位置 , 摘录代码如下 。
private void Insert(TKey key, TValue value, bool add){if( key == null ) {ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if (buckets == null) Initialize(0);// 通过key获取hashCodeint hashCode = comparer.GetHashCode(key)// 计算出目标bucket下标int targetBucket = hashCode % buckets.Length; // 碰撞次数int collisionCount = 0;for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {if (entries[i].hashCode == hashCode}// 如果不是增加操作 , 那可能是索引赋值操作 dictionary["foo"] = "foo"// 那么赋值后版本++ , 退出entries[i].value = http://kandian.youth.cn/index/value;version++;return;}// 每遍历一个元素 , 都是一次碰撞collisionCount++;}int index;// 如果有被删除的元素 , 那么将元素放到被删除元素的空闲位置if (freeCount> 0) {index = freeList;freeList = entries[index].next;freeCount--;}else {// 如果当前entries已满 , 那么触发扩容if (count == entries.Length){Resize();targetBucket = hashCode % buckets.Length;}index = count;count++;}// 给entry赋值entries[index].hashCode = hashCode;entries[index].next = buckets[targetBucket];entries[index].key = key;entries[index].value = http://kandian.youth.cn/index/value;buckets[targetBucket] = index;// 版本号++version++;// 如果碰撞次数大于设置的最大碰撞次数 , 那么触发Hash碰撞扩容if(collisionCount> HashHelpers.HashCollisionThresholdResize(entries.Length, true);}}
- 与用户|掌握好这4个步骤,实现了规模性的盈利
- 落地|“电竞之都”争夺战中,城市们该怎样实现产业落地?
- 美好生活|以人为本实现万物互融,中国视频社会化时代开启
- 手机|女神的自拍秘密,只需一部vivo S7便可以实现
- 自动任务|赶在三星 S21 发布之前实现语音解锁
- 产业|新主导力量来了,上海如何实现一次“革命性重塑”?
- Mate40Pro|华为Mate40Pro前置镜头有多强实现的这些功能国产机没人做到
- 突破|再传喜讯国产8英寸石墨烯晶圆亮相,中国芯再次实现新突破
- 如何基于Python实现自动化控制鼠标和键盘操作
- 小天才电话手表立体定位技术,真正实现无死角定位