浅析C# Dictionary实现原理( 三 )
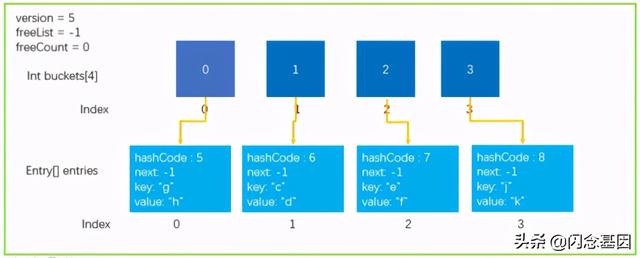
entries[index].next = buckets[targetBucket];...buckets[targetBucket] = index;实际上 步骤4 也就是做一个这样的操作 , 并不会去判断是不是有其它元素 , 因为 buckets 中桶初始值就是-1 , 不会造成问题 。
经过上面的步骤以后 , 数据结构就更新成了下图这个样子 。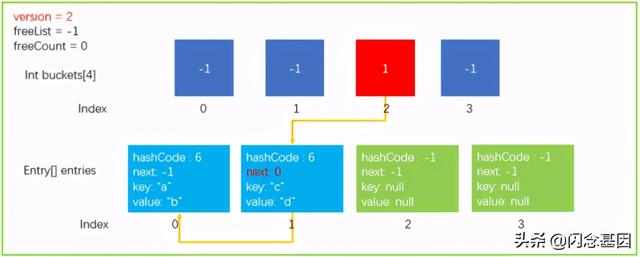 文章插图
文章插图
4. Dictionary - Find操作为了方便演示如何查找 , 我们继续Add一个元素 dictionary.Add("e","f"),GetHashCode(“e”) = 7; 7% buckets.Length=3 ,数据结构如下所示 。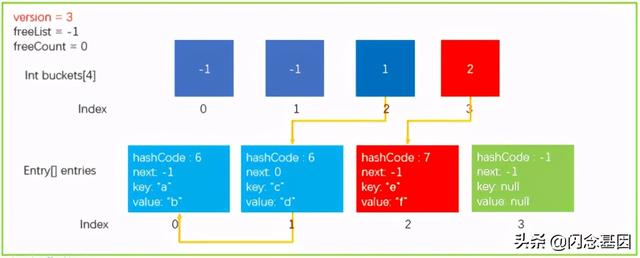 文章插图
文章插图
假设我们现在执行这样一条语句 dictionary.GetValueOrDefault("a"), 会执行以下步骤.
- 获取key的hashCode , 计算出所在的桶位置 。 我们之前提到 , "a"的 hashCode=6, 所以最后计算出来 targetBucket=2。
- 通过 buckets[2]=1 找到 entries[1] ,比较key的值是否相等 , 相等就返回 entryIndex, 不想等就继续 entries[next] 查找 , 直到找到key相等元素或者 next == -1 的时候 。 这里我们找到了 key == "a" 的元素 , 返回 entryIndex=0。
- 如果 entryIndex >= 0 那么返回对应的 entries[entryIndex] 元素 , 否则返回 default(TValue)。 这里我们直接返回 entries[0].value。
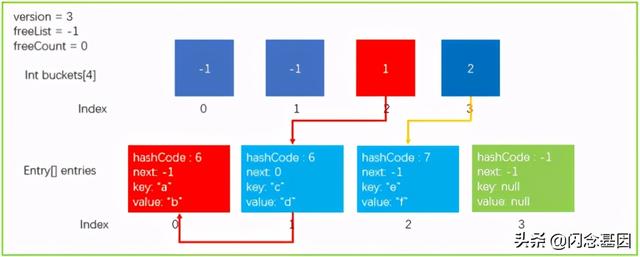 文章插图
文章插图将查找的代码摘录下来 , 如下所示 。
// 寻找Entry元素的位置private int FindEntry(TKey key) {if( key == null) {ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if (buckets != null) {int hashCode = comparer.GetHashCode(key)// 获取HashCode , 忽略符号位// int i = buckets[hashCode % buckets.Length] 找到对应桶 , 然后获取entry在entries中位置// i >= 0; i = entries[i].next 遍历单链表for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {// 找到就返回了if (entries[i].hashCode == hashCode}}return -1;}...internal TValue GetValueOrDefault(TKey key) {int i = FindEntry(key);// 大于等于0代表找到了元素位置 , 直接返回value// 否则返回该类型的默认值if (i >= 0) {return entries[i].value;}return default(TValue);}5. Dictionary - Remove操作前面已经向大家介绍了增加、查找 , 接下来向大家介绍Dictionary如何执行删除操作 。 我们沿用之前的Dictionary数据结构 。文章插图删除前面步骤和查找类似 , 也是需要找到元素的位置 , 然后再进行删除的操作 。
我们现在执行这样一条语句 dictionary.Remove("a"), hashFunc运算结果和上文中一致 。 步骤大部分与查找类似 , 我们直接看摘录的代码 , 如下所示 。
public bool Remove(TKey key) {if(key == null) {ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if (buckets != null) {// 1. 通过key获取hashCodeint hashCode = comparer.GetHashCode(key)// 2. 取余获取bucket位置int bucket = hashCode % buckets.Length;// last用于确定是否当前bucket的单链表中最后一个元素int last = -1;// 3. 遍历bucket对应的单链表for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) {if (entries[i].hashCode == hashCode}else {// 4.1 last不小于0 , 代表当前元素处于bucket单链表中间位置 , 需要将该元素的头结点和尾节点相连起来,防止链表中断entries[last].next = entries[i].next;}// 5. 将Entry结构体内数据初始化entries[i].hashCode = -1;// 5.1 建立freeList单链表entries[i].next = freeList;entries[i].key = default(TKey);entries[i].value = http://kandian.youth.cn/index/default(TValue);// *6. 关键的代码 , freeList等于当前的entry位置 , 下一次Add元素会优先Add到该位置freeList = i;freeCount++;// 7. 版本号+1version++;return true;}}}return false;}执行完上面代码后 , 数据结构就更新成了下图所示 。 需要注意 varsion、freeList、freeCount 的值都被更新了 。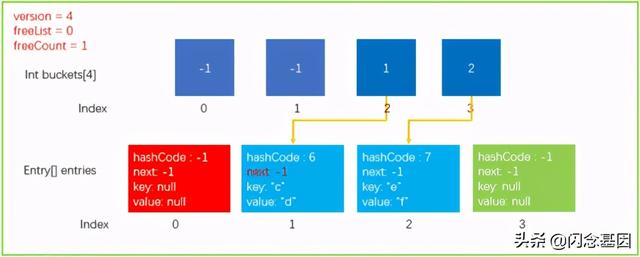 文章插图
文章插图6. Dictionary - Resize操作(扩容)有细心的小伙伴可能看过了 Add 操作以后就想问了 ,buckets、entries 不就是两个数组么 , 那万一数组放满了怎么办?接下来就是我所要介绍的 Resize(扩容) 这样一种操作 , 对我们的 buckets、entries 进行扩容 。
6.1 扩容操作的触发条件首先我们需要知道在什么情况下 , 会发生扩容操作; 第一种情况自然就是数组已经满了 , 没有办法继续存放新的元素 。如下图所示的情况 。
 文章插图
文章插图
- 与用户|掌握好这4个步骤,实现了规模性的盈利
- 落地|“电竞之都”争夺战中,城市们该怎样实现产业落地?
- 美好生活|以人为本实现万物互融,中国视频社会化时代开启
- 手机|女神的自拍秘密,只需一部vivo S7便可以实现
- 自动任务|赶在三星 S21 发布之前实现语音解锁
- 产业|新主导力量来了,上海如何实现一次“革命性重塑”?
- Mate40Pro|华为Mate40Pro前置镜头有多强实现的这些功能国产机没人做到
- 突破|再传喜讯国产8英寸石墨烯晶圆亮相,中国芯再次实现新突破
- 如何基于Python实现自动化控制鼠标和键盘操作
- 小天才电话手表立体定位技术,真正实现无死角定位