金融市场中的NLP——情感分析( 二 )
 文章插图
文章插图
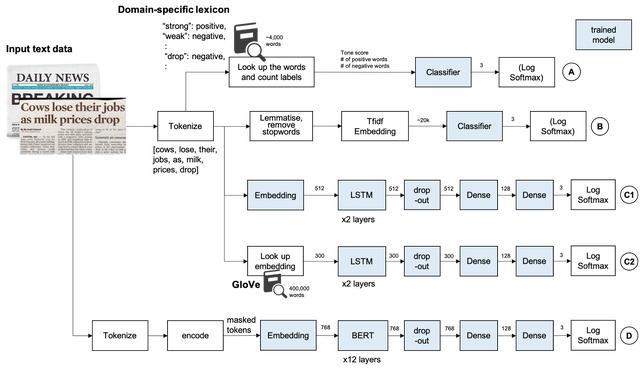
A、 基于词汇的方法创建特定于领域的词典是一种传统的方法 , 在某些情况下 , 如果源代码来自特定的个人或媒体 , 则这种方法简单而强大 。 Loughran和McDonald情感词列表 。 这个列表包含超过4k个单词 , 这些单词出现在带有情绪标签的财务报表上 。 注:此数据需要许可证才能用于商业应用 。 请在使用前检查他们的网站 。
## 样本negative: ABANDONnegative: ABANDONEDconstraining: STRICTLY我用了2355个消极单词和354个积极单词 。 它包含单词形式 , 因此不要对输入执行词干分析和词干化 。 对于这种方法 , 考虑否定形式是很重要的 。 比如not , no , don , 等等 。 这些词会把否定词的意思改为肯定的 , 如果前面三个词中有否定词 , 这里我简单地把否定词的意思转换成肯定词 。
然后 , 情感得分定义如下 。
tone_score = 100 * (pos_count — neg_count) / word_count用默认参数训练14个不同的分类器 , 然后用网格搜索交叉验证法对随机森林进行超参数整定 。
classifiers = []classifiers.append(("SVC", SVC(random_state=random_state)))classifiers.append(("DecisionTree", DecisionTreeClassifier(random_state=random_state)))classifiers.append(("AdaBoost", AdaBoostClassifier(DecisionTreeClassifier(random_state=random_state),random_state=random_state,learning_rate=0.1)))classifiers.append(("RandomForest", RandomForestClassifier(random_state=random_state, n_estimators=100)))classifiers.append(("ExtraTrees", ExtraTreesClassifier(random_state=random_state)))classifiers.append(("GradientBoosting", GradientBoostingClassifier(random_state=random_state)))classifiers.append(("MultipleLayerPerceptron", MLPClassifier(random_state=random_state)))classifiers.append(("KNeighboors", KNeighborsClassifier(n_neighbors=3)))classifiers.append(("LogisticRegression", LogisticRegression(random_state = random_state)))classifiers.append(("LinearDiscriminantAnalysis", LinearDiscriminantAnalysis()))classifiers.append(("GaussianNB", GaussianNB()))classifiers.append(("Perceptron", Perceptron()))classifiers.append(("LinearSVC", LinearSVC()))classifiers.append(("SGD", SGDClassifier()))cv_results = []for classifier in classifiers :cv_results.append(cross_validate(classifier[1], X_train, y=Y_train, scoring=scoring, cv=kfold, n_jobs=-1))# 使用随机森林分类器rf_clf = RandomForestClassifier()# 执行网格搜索param_grid = {'n_estimators': np.linspace(1, 60, 10, dtype=int),'min_samples_split': [1, 3, 5, 10],'min_samples_leaf': [1, 2, 3, 5],'max_features': [1, 2, 3],'max_depth': [None],'criterion': ['gini'],'bootstrap': [False]}model = GridSearchCV(rf_clf, param_grid=param_grid, cv=kfold, scoring=scoring, verbose=verbose, refit=refit, n_jobs=-1, return_train_score=True)model.fit(X_train, Y_train)rf_best = model.best_estimator_B、 基于Tfidf向量的传统机器学习输入被NLTK word_tokenize()标记化 , 然后词干化和删除停用词 。 然后输入到TfidfVectorizer, 通过Logistic回归和随机森林分类器进行分类 。
### 逻辑回归pipeline1 = Pipeline([('vec', TfidfVectorizer(analyzer='word')),('clf', LogisticRegression())])pipeline1.fit(X_train, Y_train)### 随机森林与网格搜索pipeline2 = Pipeline([('vec', TfidfVectorizer(analyzer='word')),('clf', RandomForestClassifier())])param_grid = {'clf__n_estimators': [10, 50, 100, 150, 200],'clf__min_samples_leaf': [1, 2],'clf__min_samples_split': [4, 6],'clf__max_features': ['auto']}model = GridSearchCV(pipeline2, param_grid=param_grid, cv=kfold, scoring=scoring, verbose=verbose, refit=refit, n_jobs=-1, return_train_score=True)model.fit(X_train, Y_train)tfidf_best = model.best_estimator_C、 LSTM由于LSTM被设计用来记忆表达上下文的长期记忆 , 因此使用自定义的tokenizer并且输入是字符而不是单词 , 所以不需要词干化或输出停用词 。 输入先到一个嵌入层 , 然后是两个lstm层 。 为了避免过拟合 , 应用dropout , 然后是全连接层 , 最后采用log softmax 。
class TextClassifier(nn.Module):def __init__(self, vocab_size, embed_size, lstm_size, dense_size, output_size, lstm_layers=2, dropout=0.1):"""初始化模型"""super().__init__()self.vocab_size = vocab_sizeself.embed_size = embed_sizeself.lstm_size = lstm_sizeself.dense_size = dense_sizeself.output_size = output_sizeself.lstm_layers = lstm_layersself.dropout = dropoutself.embedding = nn.Embedding(vocab_size, embed_size)self.lstm = nn.LSTM(embed_size, lstm_size, lstm_layers, dropout=dropout, batch_first=False)self.dropout = nn.Dropout(dropout)if dense_size == 0:self.fc = nn.Linear(lstm_size, output_size)else:self.fc1 = nn.Linear(lstm_size, dense_size)self.fc2 = nn.Linear(dense_size, output_size)self.softmax = nn.LogSoftmax(dim=1)def init_hidden(self, batch_size):"""初始化隐藏状态"""weight = next(self.parameters()).datahidden = (weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_(),weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_())return hiddendef forward(self, nn_input_text, hidden_state):"""在nn_input上执行模型的前项传播"""batch_size = nn_input_text.size(0)nn_input_text = nn_input_text.long()embeds = self.embedding(nn_input_text)lstm_out, hidden_state = self.lstm(embeds, hidden_state)# 堆叠LSTM输出 , 应用dropoutlstm_out = lstm_out[-1,:,:]lstm_out = self.dropout(lstm_out)# 全连接层if self.dense_size == 0:out = self.fc(lstm_out)else:dense_out = self.fc1(lstm_out)out = self.fc2(dense_out)# Softmaxlogps = self.softmax(out)return logps, hidden_state
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 发展|新基建发展迅猛,必然会是一个巨大的市场机遇
- 蓝海|背靠万亿美元市场,老年人会是音乐产业的新蓝海吗?
- 升级|国内知名商贸市场迭代争议多,理念升级更重要
- 高端|5nm旗舰芯片将集结完毕,Exynos 1080成高端市场“座上客”
- 脸上|那个被1亿锦鲤砸中的“信小呆”:失去工作后,脸上已无纯真笑容
- 白皮书|这个370亿美元的市场,因为新四化,中国企业的机会来了
- 平台|207家平台有81家失踪,网约车市场泡沫初现
- 市场|聚焦私域流量电商供应链赋能 纷来电商或站上万亿市场风口