金融市场中的NLP——情感分析( 三 )
作为替代 , 还尝试了斯坦福大学的GloVe词嵌入 , 这是一种无监督的学习算法 , 用于获取单词的向量表示 。 在这里 , 用6百万个标识、40万个词汇和300维向量对Wikipedia和Gigawords进行了预训练 。 在我们的词汇表中 , 大约90%的单词都是在这个GloVe里找到的 , 其余的都是随机初始化的 。
D、 BERT和ALBERT我使用了Huggingface中的transformer实现BERT模型 。 现在他们提供了tokenizer和编码器 , 可以生成文本id、pad掩码和段id , 可以直接在BertModel中使用 , 我们使用标准训练过程 。
与LSTM模型类似 , BERT的输出随后被传递到dropout , 全连接层 , 然后应用log softmax 。 如果没有足够的计算资源预算和足够的数据 , 从头开始训练模型不是一个选择 , 所以我使用了预训练的模型并进行了微调 。 预训练的模型如下所示:
- BERT:bert-base-uncased
- ALBERT:albert-base-v2
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)def train_bert(model, tokenizer)# 移动模型到GUP/CPU设备device = 'cuda:0' if torch.cuda.is_available() else 'cpu'model = model.to(device)# 将数据加载到SimpleDataset(自定义数据集类)train_ds = SimpleDataset(x_train, y_train)valid_ds = SimpleDataset(x_valid, y_valid)# 使用DataLoader批量加载数据集中的数据train_loader = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)valid_loader = torch.utils.data.DataLoader(valid_ds, batch_size=batch_size, shuffle=False)# 优化器和学习率衰减num_total_opt_steps = int(len(train_loader) * num_epochs)optimizer = AdamW_HF(model.parameters(), lr=learning_rate, correct_bias=False)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=num_total_opt_steps*warm_up_proportion, num_training_steps=num_total_opt_steps)# PyTorch scheduler# 训练model.train()# Tokenizer 参数param_tk = {'return_tensors': "pt",'padding': 'max_length','max_length': max_seq_length,'add_special_tokens': True,'truncation': True}# 初始化best_f1 = 0.early_stop = 0train_losses = []valid_losses = []for epoch in tqdm(range(num_epochs), desc="Epoch"):# print('================epoch {}==============='.format(epoch+1))train_loss = 0.for i, batch in enumerate(train_loader):# 传输到设备x_train_bt, y_train_bt = batchx_train_bt = tokenizer(x_train_bt, **param_tk).to(device)y_train_bt = torch.tensor(y_train_bt, dtype=torch.long).to(device)# 重设梯度optimizer.zero_grad()# 前馈预测loss, logits = model(**x_train_bt, labels=y_train_bt)# 反向传播loss.backward()# 损失train_loss += loss.item() / len(train_loader)# 梯度剪切torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)# 更新权重和学习率optimizer.step()scheduler.step()train_losses.append(train_loss)# 评估模式model.eval()# 初始化val_loss = 0.y_valid_pred = np.zeros((len(y_valid), 3))with torch.no_grad():for i, batch in enumerate(valid_loader):# 传输到设备x_valid_bt, y_valid_bt = batchx_valid_bt = tokenizer(x_valid_bt, **param_tk).to(device)y_valid_bt = torch.tensor(y_valid_bt, dtype=torch.long).to(device)loss, logits = model(**x_valid_bt, labels=y_valid_bt)val_loss += loss.item() / len(valid_loader)valid_losses.append(val_loss)# 计算指标acc, f1 = metric(y_valid, np.argmax(y_valid_pred, axis=1))# 如果改进了 , 保存模型 。 如果没有 , 那就提前停止if best_f1 < f1:early_stop = 0best_f1 = f1else:early_stop += 1print('epoch: %d, train loss: %.4f, valid loss: %.4f, acc: %.4f, f1: %.4f, best_f1: %.4f, last lr: %.6f' %(epoch+1, train_loss, val_loss, acc, f1, best_f1, scheduler.get_last_lr()[0]))if device == 'cuda:0':torch.cuda.empty_cache()# 如果达到耐心数 , 提前停止if early_stop >= patience:break# 返回训练模式model.train()return model评估首先 , 输入数据以8:2分为训练组和测试集 。 测试集保持不变 , 直到所有参数都固定下来 , 并且每个模型只使用一次 。 由于数据集不用于计算交叉集 , 因此验证集不用于计算 。 此外 , 为了克服数据集不平衡和数据集较小的问题 , 采用分层K-Fold交叉验证进行超参数整定 。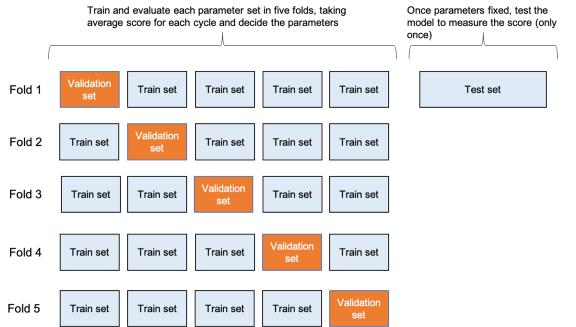 文章插图
文章插图由于输入数据不平衡 , 因此评估以F1分数为基础 , 同时也参考了准确性 。
def metric(y_true, y_pred):acc = accuracy_score(y_true, y_pred)f1 = f1_score(y_true, y_pred, average='macro')return acc, f1scoring = {'Accuracy': 'accuracy', 'F1': 'f1_macro'}refit = 'F1'kfold = StratifiedKFold(n_splits=5)模型A和B使用网格搜索交叉验证 , 而C和D的深层神经网络模型使用自定义交叉验证 。# 分层KFoldskf = StratifiedKFold(n_splits=5, shuffle=True, random_state=rand_seed)# 循环for n_fold, (train_indices, valid_indices) in enumerate(skf.split(y_train, y_train)):# 模型model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)# 输入数据x_train_fold = x_train[train_indices]y_train_fold = y_train[train_indices]x_valid_fold = x_train[valid_indices]y_valid_fold = y_train[valid_indices]# 训练train_bert(model, x_train_fold, y_train_fold, x_valid_fold, y_valid_fold)
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 发展|新基建发展迅猛,必然会是一个巨大的市场机遇
- 蓝海|背靠万亿美元市场,老年人会是音乐产业的新蓝海吗?
- 升级|国内知名商贸市场迭代争议多,理念升级更重要
- 高端|5nm旗舰芯片将集结完毕,Exynos 1080成高端市场“座上客”
- 脸上|那个被1亿锦鲤砸中的“信小呆”:失去工作后,脸上已无纯真笑容
- 白皮书|这个370亿美元的市场,因为新四化,中国企业的机会来了
- 平台|207家平台有81家失踪,网约车市场泡沫初现
- 市场|聚焦私域流量电商供应链赋能 纷来电商或站上万亿市场风口