金融市场中的NLP——情感分析( 四 )
结果基于BERT的微调模型在花费了或多或少相似的超参数调整时间之后 , 明显优于其他模型 。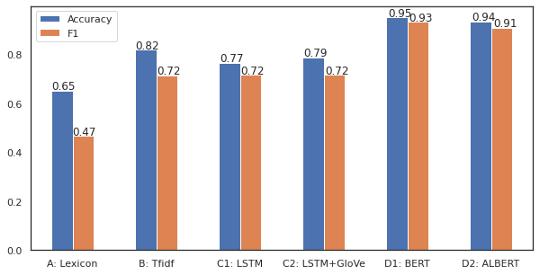 文章插图
文章插图
模型A表现不佳 , 因为输入过于简化为情感得分 , 情感分数是判断情绪的单一值 , 而随机森林模型最终将大多数数据标记为中性 。 简单的线性模型只需对情感评分应用阈值就可以获得更好的效果 , 但在准确度和f1评分方面仍然很低 。 文章插图
文章插图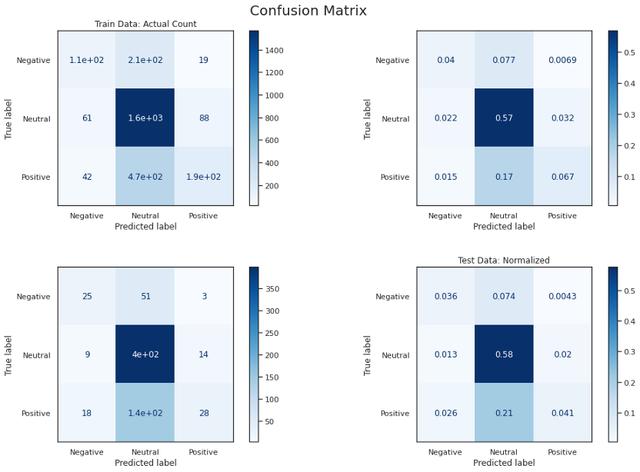 文章插图
文章插图
我们没有使用欠采样/过采样或SMOTE等方法来平衡输入数据 , 因为它可以纠正这个问题 , 但会偏离存在不平衡的实际情况 。 如果可以证明为每个要解决的问题建立一个词典的成本是合理的 , 这个模型的潜在改进是建立一个自定义词典 , 而不是L-M词典 。
模型B比前一个模型好得多 , 但是它以几乎100%的准确率和f1分数拟合了训练集 , 但是没有被泛化 。 我试图降低模型的复杂度以避免过拟合 , 但最终在验证集中的得分较低 。 平衡数据可以帮助解决这个问题或收集更多的数据 。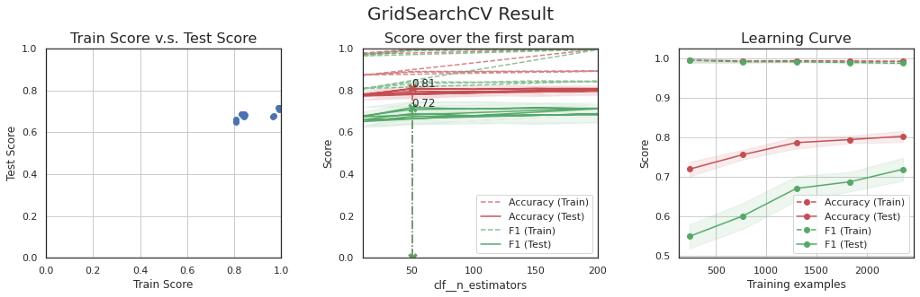 文章插图
文章插图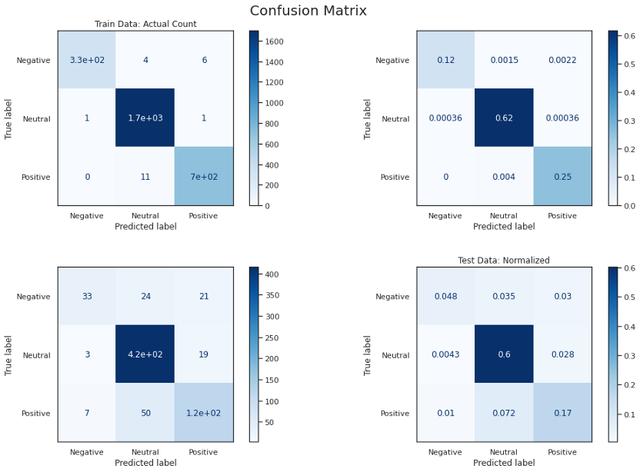 文章插图
文章插图
模型C产生了与前一个模型相似的结果 , 但改进不大 。 事实上 , 训练数据的数量不足以从零开始训练神经网络 , 需要训练到多个epoch , 这往往会过拟合 。 预训练的GloVe并不能改善结果 。 对后一种模型的一个可能的改进是使用类似领域的大量文本(如10K、10Q财务报表)来训练GloVe , 而不是使用维基百科中预训练过的模型 。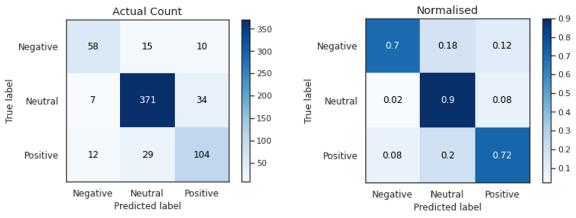 文章插图
文章插图
模型D在交叉验证和最终测试中的准确率和f1分数均达到90%以上 。 它正确地将负面文本分类为84% , 而正面文本正确分类为94% , 这可能是由于输入的数量 , 但最好仔细观察以进一步提高性能 。 这表明 , 由于迁移学习和语言模型 , 预训练模型的微调在这个小数据集上表现良好 。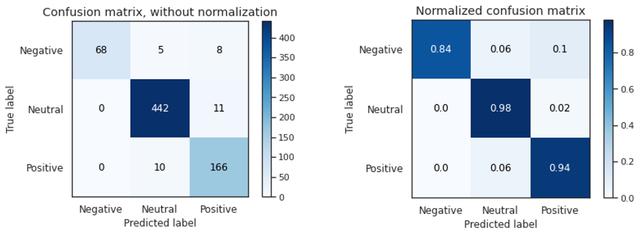 文章插图
文章插图 文章插图
文章插图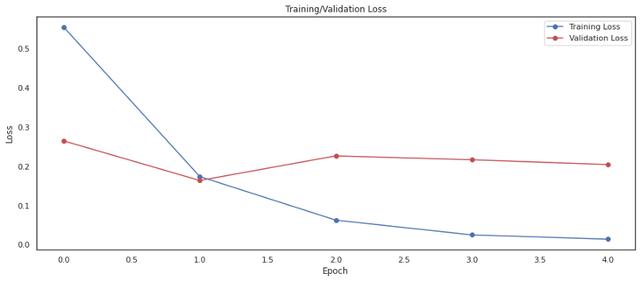 文章插图
文章插图
结论这个实验展示了基于BERT的模型在我的领域中应用的潜力 , 以前的模型没有产生足够的性能 。 然而 , 结果不是确定性的 , 如果调整下超参数 , 结果可能会有所不同 。
值得注意的是 , 在实际应用中 , 获取正确的输入数据也相当重要 。 没有高质量的数据(通常被称为“垃圾输入 , 垃圾输出”)就不能很好地训练模型 。
这里使用的所有代码都可以在git repo中找到:
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 发展|新基建发展迅猛,必然会是一个巨大的市场机遇
- 蓝海|背靠万亿美元市场,老年人会是音乐产业的新蓝海吗?
- 升级|国内知名商贸市场迭代争议多,理念升级更重要
- 高端|5nm旗舰芯片将集结完毕,Exynos 1080成高端市场“座上客”
- 脸上|那个被1亿锦鲤砸中的“信小呆”:失去工作后,脸上已无纯真笑容
- 白皮书|这个370亿美元的市场,因为新四化,中国企业的机会来了
- 平台|207家平台有81家失踪,网约车市场泡沫初现
- 市场|聚焦私域流量电商供应链赋能 纷来电商或站上万亿市场风口