贾磊畅谈AI语音技术的现在、过去和未来( 四 )
2020 年百度语音技术成果盘点
智能语音交互系统是人工智能产业链的关键环节 , 面对未来智能语音产业链的新需求 , 百度研发了新一代适合大规模工业化部署的全新端到端语音交互系统 , 实现了语音交互全链路协同处理 , 软硬件一体优化 , 信号语音一体化建模 , 语音语言一体建模 , 语音语义一体交互 , 语音图像多模态融合 , 全深度学习的语音识别、语音唤醒以及千人千面个性化语音合成等 , 其中重大技术创新如下 。
1. Attention(注意力) 技术早已经广泛应用于 NLP、图像等商业产品领域 , 但是语音识别领域 , 从 2015 年开始 , 实验室内就广泛进行了基于 Attention 的声学建模技术 , 也获得了广泛的成功 , 但是在语音识别最广泛使用的语音交互领域 , Attention 机制一直没办法应用于工业产品 。 核心原因是语音识别的流式服务要求:语音必须分片传输到服务器上 , 解码过程也必须是分片解码 , 用户话音刚落 , 语音识别结果就要完成 , 这时候人的说话过程、语音分片上传过程和语音识别的解码过程三者都是并行的 。 这样用户话音一落 , 就可以拿到识别结果 , 用户的绝对等待时间最短 , 用户体验最佳 。 传统注意力建模技术必须拿到全局语音之后 , 才开始做注意力特征抽取 , 然后再解码 , 这样一来解码器过程的耗时就不能和语音识别的解码过程同步起来 , 用户等待时间就会很长 , 不满足语音交互的实时性要求 。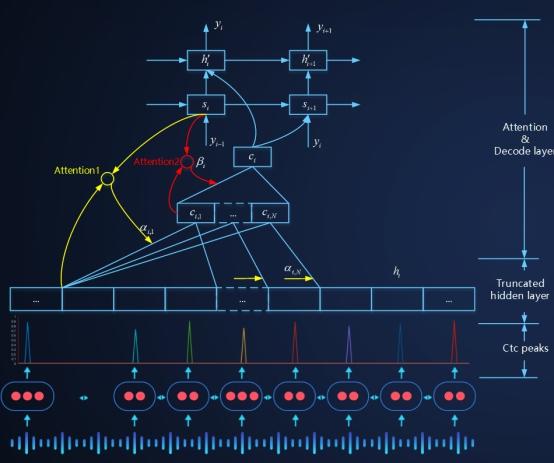 文章插图
文章插图
SMLTA: 百度流式多级截断注意力模型(2019年1月发布)
2019年1月 , 百度语音团队提出了流式多级的截断注意力模型 SMLTA 。 该方案采用 CTC 模型和 SMLTA 模型相结合的办法 , 利用 CTC 的 peak 对连续语音流进行截断 , 然后在截断的语音流上做截断的注意力模型 。 这是全世界范围内 , 第一次基于 Attention(注意力技术) 的在线语音识别服务的大规模上线 。 该技术显著提升了线上语音交互的语音识别的准确率 , 同时实现了语音语言的一体化建模 , 为云端语音识别技术的全面端侧芯片化打下了基础 。 2020 年 , SMLTA 技术全面应用于百度语音识别全线产品:语音输入法、语音搜索、地图语音交互、智能音箱、汽车导航、智能呼叫中心、会议在线翻译等产品上 , 都能看到 SMLTA 技术对语音交互性能的持续提升 。
2. 近些年随着 5G 的万物互联概念的普及 , 中国社会对智能设备的远场语音交互需求日益增加 。 在远场环境下 , 目标声源距离拾音器较远 , 致使目标信号衰减严重 , 加之环境嘈杂干扰信号众多 , 最终导致信噪比较低 , 语音识别性能较差 。 为了提升远场语音识别准确率 , 一般会使用麦克风阵列作为拾音器 , 然后利用数字信号处理领域的多通道语音信号处理技术 , 增强目标信号 , 最终产生一路清晰信号 , 送给后面的语音识别系统进行语音识别 。 这时候数字处理信号系统和语音识别系统是级联方式 , 数字信号处理系统是以信号的清晰度为优化目标 , 语音识别声学建模是以云识别率为建模目标 , 两个系统优化目标不统一 , 错误也会级联放大 , 最终的交互体验相比于近场识别差很多 。 国际上 , Google 试图采用端到端建模技术解决这个问题 , 一套模型解决远场麦克阵列信号处理和语音识别声学建模问题 。 谷歌的解决方案采用的深度学习模型结构 , 借鉴了数字信号处理领域的类似于 filtering and sum 的数字信号处理思想 , 模型结构设计模拟经典数字信号处理过程 。 这种借鉴使得深度学习进行端到端建模更容易收敛 , 但是后期我们通过实验证明 , 这种借鉴严重影响了深度学习技术在该方向上的发挥和延伸 , 限制了深度学习模型的模型结构的演变 , 制约了技术的创新和发展 。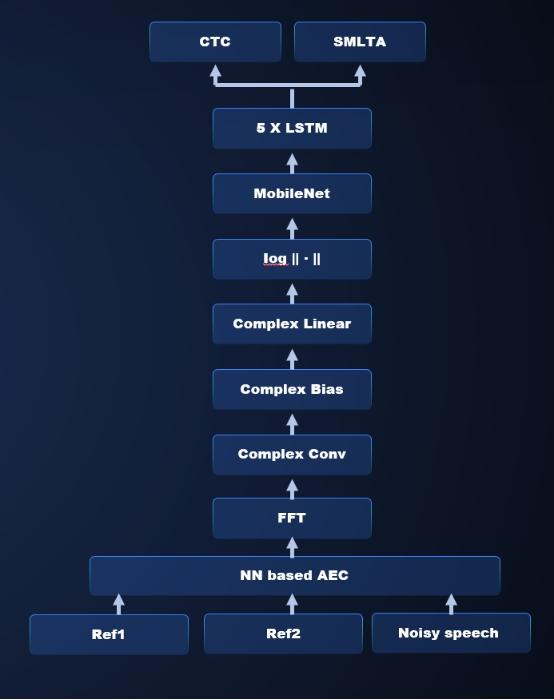 文章插图
文章插图
基于复数 CNN 的语音增强和语音识别一体化的端到端建模
百度语音团队研发出完全不依赖于任何先验假设的信号、语音一体化的适合远场语音交互的深度学习建模技术 。 该深度学习模型以复数 CNN 为核心 , 利用复数 CNN 网络挖掘生理信号本质特征的特点 , 采用复数 CNN、复数全连接层以及 CNN 等多层网络 , 直接对原始的多通道语音信号进行多尺度多层次的信息抽取 , 期间充分挖掘频带之间的关联耦合信息 。 在保留原始特征相位信息的前提下 , 同时实现了前端声源定位、波束形成和增强特征提取 。 该模型底部 CNN 抽象出来的特征 , 直接送入百度独有的端到端的流式多级的截断注意力模型中 , 从而实现了从原始多路麦克信号到识别目标文字的端到端一体化建模 。 整个网络的优化准则完全依赖于语音识别网络的优化准则来做 , 完全以识别率提升为目标来做模型参数调优 。 目前该方法已经被集成到百度最新发布的百度鸿鹄芯片中 。
- 华夏小康|百融云创语音技术获多项专利 “百小融”赋能金融机构加速数字化
- 淘宝|给双12做准备?淘宝突然上线新功能:居然能打语音电话了
- TT语音|产业蓬勃发展之际,“TT语音”们如何打好下半场“擂台赛”?
- 创投圈|跨所有语言?Meta发布新语音模型,简直能让全球人无障碍交流
- 中华新闻|讯飞输入法全新升级!AI语音输入取得新突破
- 语音助手|微软 Cortana 与亚马逊 Alexa 两家语音助手停止合作
- AirPods|女子误把AirPods当药吞,传语音信息听得见肠胃声
- 语音|微软发布最新语音合成模型Uni-TTSv3
- 高棉语|Facebook Messenger 50% 的语音流量来自柬埔寨
- 新一期|华为智慧语音新一期众测活动开启:小艺支持识别河南话等