贾磊畅谈AI语音技术的现在、过去和未来( 五 )
 文章插图
文章插图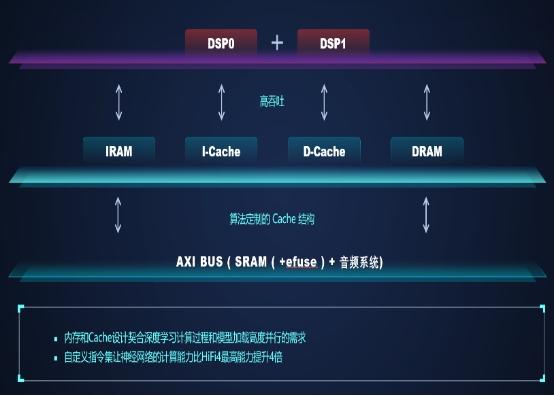 文章插图
文章插图
百度鸿鹄芯片结构图
2020 年 , 百度在智能音箱、车载导航和智能电视控制方面 , 落地了百度鸿鹄语音芯片 。 研发了以远场语音交互为核心的鸿鹄芯片解决方案 , 一颗芯片解决远场阵列信号处理和语音唤醒的问题 , 打造了云端芯一体化的语音交互解决方案 。 百度鸿鹄语音芯片设计 , 变革传统芯片设计方法 , 推出 AI 算法即软件定义芯片的全新设计思路 。 百度鸿鹄芯片采用双核 Hifi4 架构自定义指令集 , 2M 以上超大内存 , 台积电 40nm 工艺 , 在此硬件规格上 , 100mw 左右平均工作功耗 , 即可同时支持远场语音交互核心的阵列信号处理和语音唤醒能力 , 满足车规可靠性标准 。 同时 , 百度鸿鹄芯片为远场语音交互算法量身定制了芯片架构 , 完全契合 AI 算法需求的核内内存结构设计、分级的内存加载策略、依据 AI 算法调教的 Cache 设计和灵活的双核通信机制 , 最终实现了深度学习计算过程和数据加载的高度并行 。 百度鸿鹄芯片是中国行业内唯一一颗能够承载全部远场阵列信号处理和智能音箱唤醒技术的语音芯片 , 也已经完成了业内首个支持电视熄屏唤醒的 AI 芯片解决方案并实现工业产品落地 。
百度鸿鹄芯片之后 , 贾磊团队又将整个语音交互的复杂算法、逻辑和数据模型耦合的语音交互技术 , 利用百度全新研发的端到端语音建模技术 , 抽象成多个单纯的深度学习计算过程 , 从而可以几乎在性能无损的情况下将整个语音识别过程从云端搬到客户端 。 基于以上思路的百度鸿鹄芯片二代也正在紧锣密鼓的研发中 , 一颗芯片解决远场语音识别和合成问题将不再遥远 。 5G 时代的云端定义语音交互功能 , 端侧执行语音交互功能 , 云端一体的语音交互 , 很快会成为现实 。 文章插图
文章插图
百度智能语音全景图
在语音技术的产业化过程中 , 贾磊认为核心关键的要素是技术创新要把握产业需求 , 而不是闭门造车 。 比如百度的语音语言一体化的流式多级截断的注意力建模技术 (SMLTA) , 核心就是针对性的解决注意力(Attention)建模技术不能进行流式识别的问题 , 后者是在线语音识别技术必须的关键要求 。 再比如百度研发鸿鹄芯片 , 核心就是解决一颗芯片集成远场信号处理和远场唤醒 , 从而提升智能音箱的远场交互体验 , 降低智能音箱的成本 。 “文以载道” , 技术提升的首要目标是产品体验提升 , 而非纯粹的学术创新 。 管理上要集中优势兵力优先解决技术工业应用时的痛点问题 , 要基于用户感知体验提升去迭代技术 , 而非单纯的技术指标提升 。
端到端语音交互的技术挑战和难点
贾磊认为最大的挑战是对跨学科端到端的模拟数据的生成和大规模工业训练的深度学习训练平台的把握 。 端到端建模 , 目前越来越倾向于跨学科的端到端建模 , 这时候首先需要解决跨学科的数据模拟问题 。 每一个学科 , 都有一个学科假设的学科边界 。 之前几十年的研究成果 , 都是在学科边界的假设范围内进行的 , 所积累的各种训练数据 , 也是基于学科边界假设的 。 一旦学科边界被打破 , 每个学科的假设都不成立了 , 训练数据往往需要重新积累 。 所以 , 通常需要用模拟的方法产生跨学科的端到端的训练数据 。 如何模拟跨学科的场景数据 , 是端到端建模的第一个难题 。 端到端建模的第二个难题 , 是如何应对数据倍增时候的深度学习训练 , 这些问题 , 对通常的语音团队 , 会成为一个很大的挑战 。 比如在做信号和声学一体化建模的时候 , 要在近场语音识别建模的训练数据量上 , 叠加一个远场信号的声场模拟 。 这样的话 , 模拟的数据量会有一个成倍的增加 。 考虑到大规模工业训练的要求 , 上面提到的模拟数据的生成 , 还通常需要在 GPU 上进行 。 同时 , 数据成倍增加后 , 还要在 GPU 上进行高速有效的训练 。 这里面对深度学习训练平台的把握是至关重要的 , 否则跨学科端到端建模时候的训练数据模拟和训练速度优化中任何一个问题 , 都会是压垮端到端建模的最后一根稻草 。
解决上述问题的核心是要有对深度学习算法技术和工程技术都要有深刻的理解 , 对深度框架有全面的把握 。 有能力修改深度学习框架的内核 , 解决 GPU 上的训练加速、内存优化问题和算法调优的问题 。 如果只是泛泛的理解国外开源框架的算法技术 , 只是跑脚本训练模型 , 那么再遇到上述训练数据模拟和训练速度优化的时候 , 就无从下手 , 最终难以解决跨学科的端到端建模问题 。
- 华夏小康|百融云创语音技术获多项专利 “百小融”赋能金融机构加速数字化
- 淘宝|给双12做准备?淘宝突然上线新功能:居然能打语音电话了
- TT语音|产业蓬勃发展之际,“TT语音”们如何打好下半场“擂台赛”?
- 创投圈|跨所有语言?Meta发布新语音模型,简直能让全球人无障碍交流
- 中华新闻|讯飞输入法全新升级!AI语音输入取得新突破
- 语音助手|微软 Cortana 与亚马逊 Alexa 两家语音助手停止合作
- AirPods|女子误把AirPods当药吞,传语音信息听得见肠胃声
- 语音|微软发布最新语音合成模型Uni-TTSv3
- 高棉语|Facebook Messenger 50% 的语音流量来自柬埔寨
- 新一期|华为智慧语音新一期众测活动开启:小艺支持识别河南话等