OpenAI强化学习游戏库大更新:游戏上千款,还能自己加
傻大方提示您本文标题是:《OpenAI强化学习游戏库大更新:游戏上千款,还能自己加》。来源是。
OpenAI强化学习游戏库大更新:游戏上千款,还能自己加。ai|学习---
本文来自量子位,创业家系授权发布,略经编辑修改,版权归作者所有,内容仅代表作者独立观点。[ 下载创业家APP,读懂中国最赚钱的7000种生意
李林 编译整理 量子位 出品 | 公众号 QbitAI
ai|学习---傻大方小编总结的关键词

想把一个强化学习Agent训练成游戏高手?OpenAI今天推出的完整版Gym Retro必须了解一下。
这是一个用游戏来研究强化学习的平台,现在上面的游戏数量已经有1000多款,横跨各种后端模拟器,再也不是之前那个只能玩70款雅达利+30款世嘉的小平台了。
除了这1000多款可供AI玩耍的游戏之外,OpenAI还推出了一个集成工具,让用户可以在平台上添加新游戏。
跨游戏泛化
Gym Retro上的游戏覆盖了世嘉的创世纪和Master System,任天堂红白机(NES)、SNES和Game Boy主机。对于世嘉掌机GG(Game Gear)、任天堂Game Boy Color、Game Boy Advance、NEC TurboGrafx上的游戏,也有初步支持。
这么多游戏集中在同一个平台上,非常适合启动“跨游戏泛化”的研究。也就是说,AI把一个游戏玩输了之后,能不能把这些能力用到理念相似、表现形式不同的其他游戏上去?
在研究跨游戏泛化之前,要先从简单的起步:同一个游戏中的跨关卡泛化。上个月,OpenAI就举办了一场Retro Contest,让大家用刺猬索尼克的部分关卡来训练AI,再尝试泛化到另外一些关卡。现在仍在继续,离结束还有几周时间。
ai|学习---傻大方小编总结的关键词

当时,他们还发布了一篇技术报告来描述任务的基准。
Gotta Learn Fast: A New Benchmark for Generalization in RL Alex Nichol, Vicki Pfau, Christopher Hesse, Oleg Klimov, John Schulman https://arxiv.org/abs/1804.03720
现在,Gym Retro有了更多游戏,在庞大的数据集支撑下,这类泛化的研究可以从“跨关卡”变成“跨游戏”了。OpenAI自己也在进行这方面的研究,成果预计明年公布。
关于平台上的1000多款游戏,OpenAI温馨地提醒你:部分游戏可能有bug。
新游戏整合工具
如果你对跨游戏泛化没什么兴趣,偏偏只想让AI玩一款平台上没有的船新游戏呢?
OpenAI还随着Gym Retro正式版,推出了一个新游戏整合工具。只要你有游戏ROM,就可以运用这个工具创建保存状态、寻找内存位置、设计让强化学习Agent来解决的场景。
这个整合工具还支持录制和播放回放文件,把打游戏时所有的按键操作都保存下来。回放文件不保存每一帧图像,而是只包含初始状态和每次按键得出的结果,因此体积很小。这种回放文件可以用来观察Agent的动作,也可以用来保存人类输入制作训练数据。
AI擅长什么游戏?
PPO等强化学习算法最擅长的游戏有个共同特征:奖励密集,以反应速度取胜。比如说宇宙巡航舰(Gradius):
ai|学习---傻大方小编总结的关键词
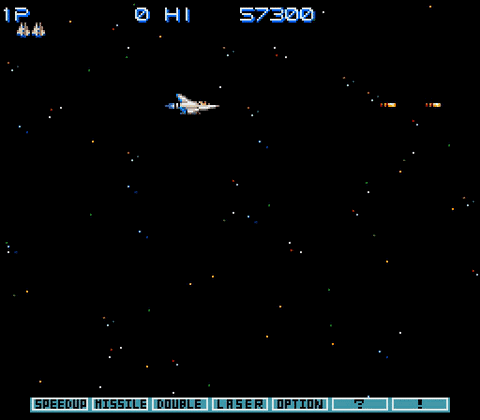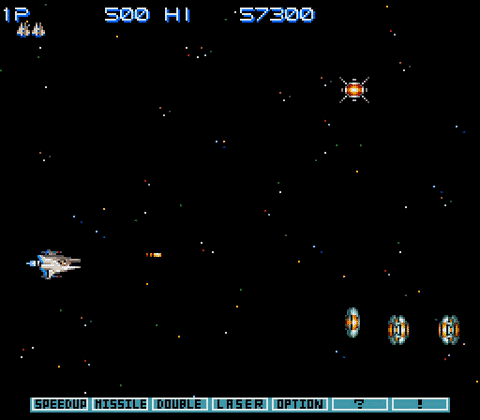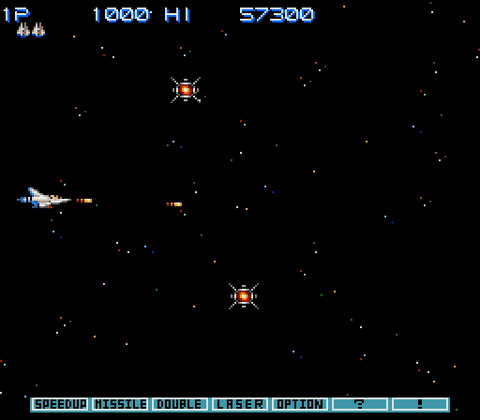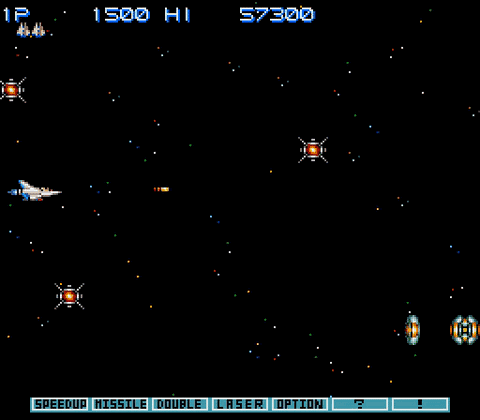
在宇宙巡航舰这个游戏里,消灭每一个敌人都能得分,也就是说很容易获得奖励;躲避开所有敌人就能活下来,也就是说拼的就是个反应速度。对于按帧来打游戏的强化学习算法来说,这并不算难。
而对于奖励稀疏,需要为几秒之后发生的事做规划的游戏,现在的强化学习算法就不太擅长了。
Gym Retro里就有很多游戏属于后者,等着广大小伙伴努力攻克。
防止AI钻空子
攻克这些游戏的过程中,请注意:你的AI可能会钻空子。
强化学习Agent打游戏,其实是在积累奖励,如果奖励函数只是得分、不考虑完成整个游戏的话,就可能会发生意想不到的操作。比如说下面的Cheese Cat-Astrophe和复仇之刃,就都被AI玩坏了:
ai|学习---傻大方小编总结的关键词

△
OpenAI强化学习游戏库大更新:游戏上千款,还能自己加。ai|学习---
Cheese Cat-Astropheai|学习---傻大方小编总结的关键词
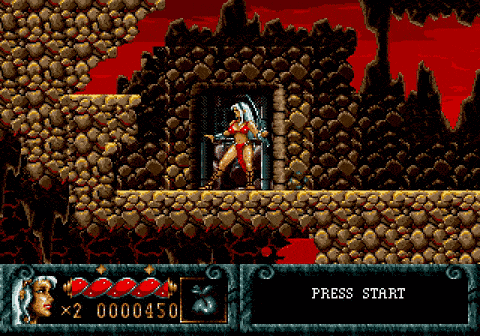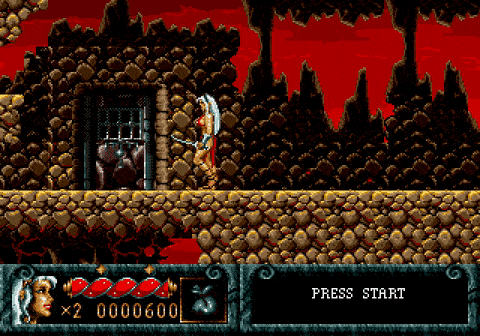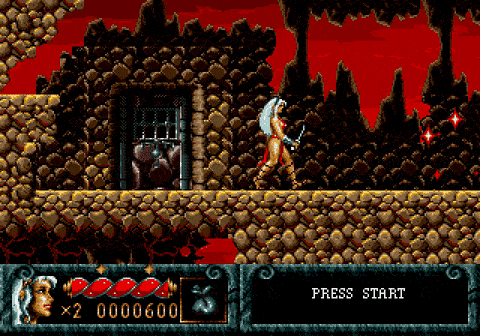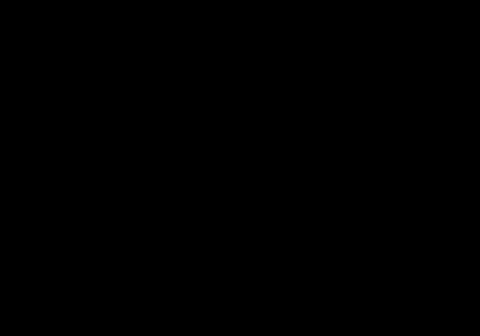
△
OpenAI强化学习游戏库大更新:游戏上千款,还能自己加。ai|学习---
复仇之刃在这两个游戏中,AI都为了快速积累奖励,困在一个关卡之内无限循环。
所以,OpenAI温馨提示:奖励函数设置得太简单,可能导致AI的行为出偏差。
让AI好好打游戏,慎重设置你的奖励函数~
- 金正恩表示要学习新加坡经济社会发展经验
- 如何用两台变频器同步控制两台电动机
- 6.7原油分析,黄金分析;原油黄金策略分析建议
- 一边看车一边遛娃,还有2000游乐嘉年华!快来儿博会学习如何带娃
- 房子那些事:最新任志强讲话整理,值得学习
- 产品课间圈:适合互联网人学习成长的大本营
- 推荐算法进阶手册:2大篇章10大模块51份学习资料
- 医生走向市场的8条学习清单
- 诺奖得主:学习科学需思维训练和动手能力并重
- 经方的魅力与学习的方法