领域|强化学习算法DeepCube,机器自行解决复杂魔方问题( 六 )
论文提出的训练方法是“ Auto-Didactic Iterations”(简称“ ADI”),该方法也简洁明了。从目标状态(复原的魔方)开始,执行一些预定义的长度为N的随机变换序列(文中给出了N个状态的序列)。对序列中的每个状态,一次执行以下过程:
将所有可能的变换(总共12个)应用于状态s;
将这12个状态传递给当前的神经网络,以输出值。这样就得到s的12个子状态的值;
根据v? = max?(v(s?,a) R(A(s?,a)))计算状态的目标值,其中A(s, a)是对s执行动作a之后的新状态;如果s是目标状态,则R(s)为1,否则为0;
状态s的目标策略使用相同的公式进行计算,不同的是我们选择最大值,即p? = argmax? (v(s?,a) R(A(s?,a)))。这仅意味着目标策略只有在最大值的子状态时取值为1,否则为0。
具体过程见下图。生成序列为x?,x?…,以魔方x?为例进行详细说明,对状态x?,通过上述公式确定策略和值目标。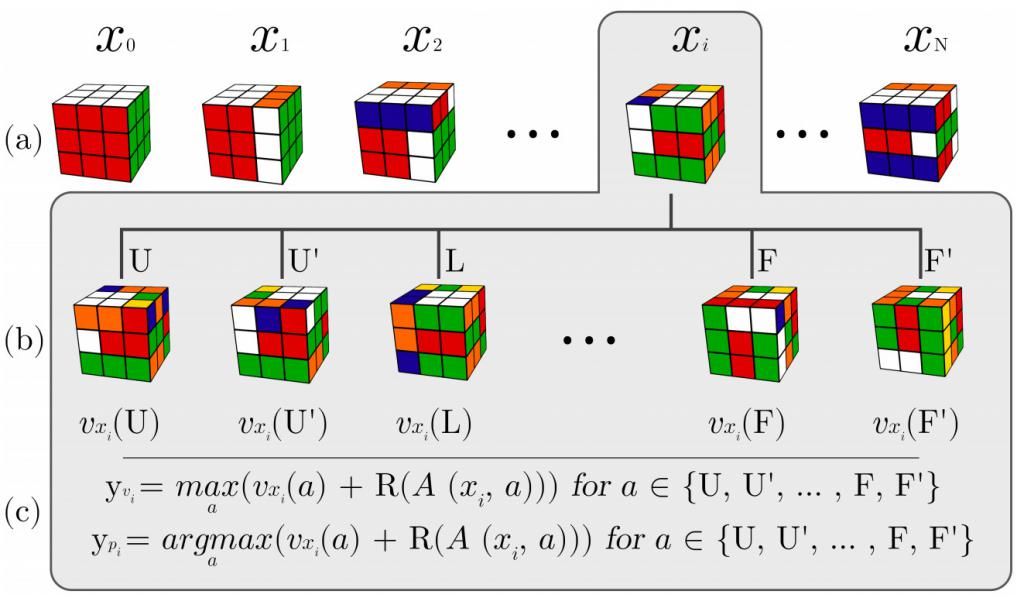
文章插图
通过该过程,我们可以生成任意数量的训练数据。
模型应用
假设我们已经通过上述过程训练得到模型,那么如何使用模型来复原魔方呢?根据网络结构,我们很容易想到这样的方法(但不幸的是该方法并不可行):
向模型提供要解决的三阶魔方的当前状态;
根据策略选择最大可能的动作(或从结果分布中采样);
【 领域|强化学习算法DeepCube,机器自行解决复杂魔方问题】对模型执行该动作;
重复上述过程,知道魔方复原。
看上去这样是可以奏效的,但是在实践中,这样的方法却行不通。主要原因是模型质量不过关。由于状态空间巨大,加上神经网络特性,对于所有输入状态,不可能经过训练使得NN返回准确的最佳动作。也就是说,模型并没有告诉我们明确的求解思路,只是向我们提出值得探索的方向,但这些方向可能使我们更接近解决方案,也有可能会引起误导。因为在训练过程中,不可能处理所有可能状态。要知道,即使使用GPU以每秒处理数十万状态的速度进行训练,对于4.33×101?的状态空间,也需要经过一个月的训练时间。因此,在训练中我们只取状态空间的一小部分,大约为0.0000005%,这就要求我们使用更复杂的方法。
有一种非常适用的方法,即“蒙特卡洛树搜索”,简称MCTS。该方法有很多变体,但总体思路很简单,可以与众所周知的蛮力搜索方法(如“广度优先搜索BFS”或“深度优先搜索DFS”)对比来进行说明。在BFS和DFS中,我们尝试所有可能的动作,并探索通过这些动作获得的所有状态对状态空间进行详尽搜索。可以发现,这种方式是上述过程的另一个极端。
MCTS在这两种极端之间进行折衷:我们想要执行搜索,并且存在一些值得关注的信息,但是,某些情况下信息可能是不可靠的噪声或错误,有时信息也可能提供正确的方向,从而加快搜索过程。
- 手机摄影技巧参考学习
- 为人处境,学习《金刚经》一句偈语,你就悟道宽心了!
- 我国历史上最邪门的禁书,学习此书者,非死即残,或断子绝孙
- 历史是由胜利者书写的,我们为什么还要学习历史?
- 慈禧|慈禧太后想当清朝女王,便向英国女王学习了一件事,使人啼笑皆非
- 酒桌上的劝酒、挡酒技术,让我们跟着胤禛一起学习和揣摩。
- 陈家|宋朝最成功的家长,三个儿子是状元,出了两个宰相,家教值得学习
- 文玩领域的中国好同学!我要是同桌肯定爱上你了
- 2021年11月16日「学习笔记」学习游击战的几点心得与思考
- 想要获得进步,就要向曾国藩等先进人物学习,成功没有捷径