机器人是怎么知道如何抓握杯子的?( 二 )
实验过程中 , 不同的物体会被随机放置在透明平台上 , 机器手会依次移动到 24 个预先设定好的位置上 , 利用腕上安装的 RGB-D 摄像机捕获场景的深度图像 。 接下来作者使用 TSDF Fusion [12] 密集地重建场景 。 由于平台是透明的 , 相机的深度传感器不会捕捉到该平台 , 被建模物体的 3D 重建会比较简单 —— 只要在重建的场景中剪切(crop)即可 。 生成的 3D 模型会被用于接下来的模拟中 , 如下图中间所示 , 算法需要模拟类似于 M&M 豆大小的灰色的小颗粒物体向被推理对象掉落的物理过程 , 并计算究竟有多少颗粒会进入到该物体内并被容纳以量化一个物体的容纳性 , 即判断一个物体是否是开放式容器 。 若模拟结果显示被推理物体内不保有任何颗粒 , 则该物体不是开放式容器 。 在下图例子中 , 算法对纸杯和一卷胶带分别进行了模拟 , 结果显示只有纸杯是开放式物体 。 若一个物体被判断为开放式容器 , 机器手还会再次进行模拟 , 以推断自己应该倒入的位置和方向 , 然后将之付诸于行动 。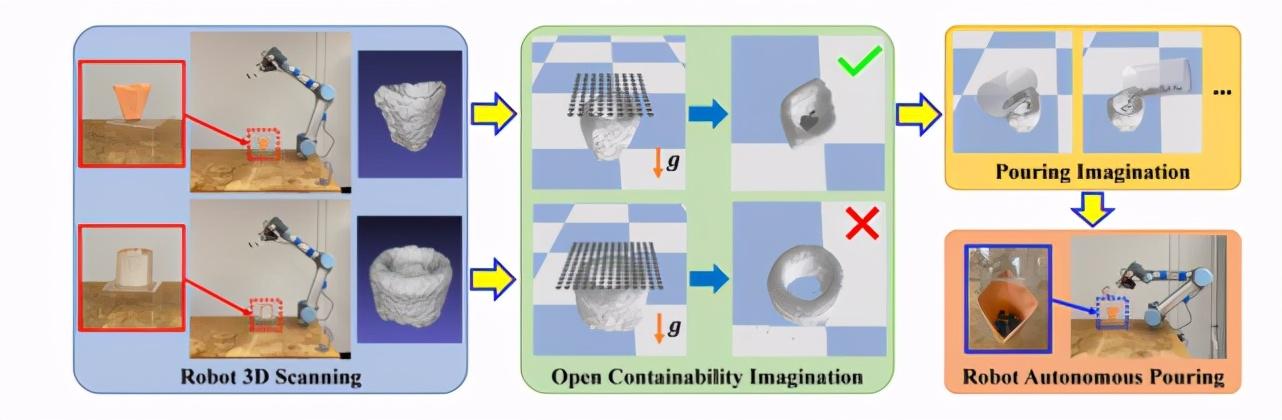 文章插图
文章插图
机器手对纸杯和胶带的容纳性进行推理 。 (图源:H. Wu, G. S. Chirikjian. (2020). Can I Pour into It? Robot Imagining Open Containability Affordance of Previously Unseen Objects via Physical Simulations. arXiv:2008.02321.)
作者利用 11 个物体对整个模拟算法(以 Imagination 代指)进行了校准 , 然后将其与利用深度学习对 RGB 图像进行学习的 AffordanceNet [11] 进行了比较 。 测试集包含 51 个物体——23 个开放式容器和 28 个非开放式容器 , 测试表现用 accuracy 和 AUC (area under curve)进行衡量 。 下表中可以看出 AffordanceNet 和 作者所提出的模拟方法都在测试集上取得了非常好的表现 。 Imagination 的准确度稍差 , 主要是因为对被推理物体的 3D 建模不够准确 , 从而导致生成的 3D 模型上出现了轻微凹陷 , 而凹陷部位可以容纳小颗粒物体从而导致了物体被误判为开放式容器 。 另一些失败的情况则比较模棱两可 , 如汤匙 , 这种争议在人类标注者上也存在 。 另一方面 , 由于使用了 RGB-D 相机 , Imagination 算法可以利用深度信息 , 这对推理和执行倾倒这个动作是有优势的 。 作者在之后进行的一些实验也证明了这一点 。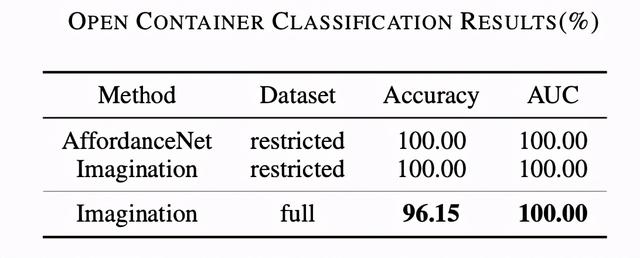 文章插图
文章插图
利用模拟来对物体的 Affordance 进行学习的优势主要在于可解释度高、对未知物体的鲁棒性好 , 难点则在于嵌入式开发中的硬件设施、计算能力、模拟算法的准确性等 。 比如本文的实验中 (1)被推理物体需要一直处于深度传感器的测量范围内;(2)只能对物体的顶部和侧面进行建模 , 因为无法机器手无法从被推理物体的下方进行扫描;(3)模拟算法模拟的是离散的刚性颗粒 , 其他物体——比如水——则具有完全不同的物理特性;(4)Affordance 的推理局限于物体的容纳性 , 如果想要将该研究延伸到新的 Affordance 如物体的抓握性 , 则需要完全的不同的模拟算法 。
通过视觉特征(visual features)
由于人类主要通过视觉线索对物体的 Affordance 进行推理 , 利用 RGB 照片建模的研究并不少见 , 比如前文提到的 AffordanceNet 。 随着深度学习的流行 , 不少研究会训练卷积神经网络(CNN)来取代传统的特征工程 。 [4] 就是典型的一例 。 这篇研究有意思的地方在于作者特意选择了专家演示的视频组成数据集 , 利用人类理解物体 Affordance 的线索训练模型 。 如果 [4] 也使用的视频中也有水杯 , 那么 CNN 就需要对专家演示中将茶水倾倒到水杯中和抓握杯柄将水杯端起来的片段理解水杯的容纳功能和抓握功能 。
专家演示的视频来自互联网上充斥着的大量的产品评论视频 (product review videos) , 其中很多视频中会有一名「专家」——比如产品评论者——通过对产品对象的一系列操作来详细演示产品功能 。 除了为消费者们拔草种草外 , 这些视频还为作者提供了新思路——用这些视频组成能够为机器人提供有关 affordance 以及人们如何与产品交互的大规模、高质量数据 。 文章插图
文章插图
产品评论视频中往往有一名「专家」在对产品进行演示(图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
这种方法虽然从逻辑上看非常可行 , 但却面临两个挑战:第一 , 这些视频中的产品和机器人要面对的产品在外观上可能有非常大的差异 , 如何保证机器人学到的 affordance 对产品外观是稳健的;第二 , 在视频中「专家」和产品的交互并不频繁 , 比如在上图例子中几乎只有第三帧中「专家」有对产品进行操作 , 还是在有大量的背景信息下进行的 , 机器人需要在其中辨别并学习真正有用的信息 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 行业|现在行业内客服托管费用是怎么算的
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?