机器人是怎么知道如何抓握杯子的?( 五 )
 文章插图
文章插图
神经网络需要学习的四种 Affordance(图源:Zeng, A., Song, S., Yu, K.-T., Donlon, E., Hogan, F. R., Bauza, M., Ma, D., Taylor, O., Liu, M., Romo, E., Fazeli, N., Alet, F., Chavan Dafle, N., Holladay, R., Morona, I., Nair, P. Q., Green, D., Taylor, I., Liu, W., … Rodriguez, A. (2019). Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. The International Journal of Robotics Research.)
在训练过程中 , 作者使用到两个全卷积残差网络(FCN) —— ResNet101 —— 中分别判断物体的吸取和抓握的 Affordance 。 为判断物体是否能够被吸取 , 下图中上排的 FCN 使用多视角 RGB-D 图像作为输入 , 然后对每个像素的 吸取 Affordance 进行预测 , 预测值越接近 1 , 则代表该部位越容易被吸取 。 随后 , 模型需要将所有视角的的预测汇集到 3D 点云(3D point cloud)上 。
图中下排的 FCN 则负责抓握 Affordance 的推理 。 作者假设一个物体可抓握与否取决于该物体是否有可抓握区域 , 并且可抓握区域可以从物体具备的几何形状和外观推断 , 即 [7] 的思想 。 首先 , RGB-D 图像将被合并到场景的正交 RGB-D 高度图(orthographic RGB-D heightmap)中 , 来生成场景的高度图 。 图中的每个像素代表垂直方向——即重力方向——上的 2mm*2mm 的空间 。 FCN 需要对图中的每个像素的抓握 Affordance 进行判断(0-1 的概率) , 由于作者假设机器手的位置是与生成的高度图在垂直方向上平行的 , 生成的 Affordance heatmap 可以直接用于机器手在该方向上抓握该物体某一个部位的可能性 。 通过将高度旋转 16 次到不同的角度 , 并用 FCN 对其进行预测 , 则可以得出在不同方向上对该物体抓握的可能性 , 即预测结果直接包含了 16 种不同的自上而下的抓取角度的概率图 。
在后处理(post-processing)时 , 根据最佳抓握点在生成的 3D 点云中的位置 , 算法会计算机器手两根手指的最佳宽度 。 同时 , 如果最佳抓握点过于靠近墙壁 , 算法会推荐执行齐平抓握 , 否则执行一般的抓握 。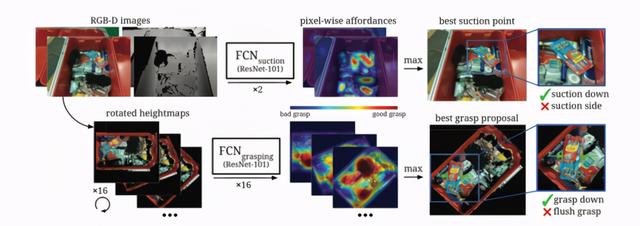 文章插图
文章插图
作者所提出的神经网络训练流程(图源:Zeng, A., Song, S., Yu, K.-T., Donlon, E., Hogan, F. R., Bauza, M., Ma, D., Taylor, O., Liu, M., Romo, E., Fazeli, N., Alet, F., Chavan Dafle, N., Holladay, R., Morona, I., Nair, P. Q., Green, D., Taylor, I., Liu, W., … Rodriguez, A. (2019). Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. The International Journal of Robotics Research.)
由于在进行推理时 , 训练好的神经网络有可能遇到未知的物体 , 作者提出了跨领域图像匹配(cross-domain image matching)模型来通过通过检索一组产品图像中的最佳匹配来解决此识别问题 。 该模型由两组 ConvNet (two-stream ConvNet)组成 , 一个用来对已知的图像计算 2048 维特征 , 另一个则为用于检索的图像——即未知物品的图像——计算 2048 维特征 。 在训练时作者从已知的物体中提供一系列匹配和不匹配的图像对来提供平衡的正例和反例 , 然后用 Triplet Loss 作为损失函数 。 这样可以有效地优化网络 , 从而最大程度地减小匹配对特征之间的 l2 距离 , 同时拉开不匹配对特征之间的 l2 距离 。 在测试过程中 , 已知对象和未知对象的图像都被映射到公共特征空间上 , 模型通过将观察到的图像映射到相同的特征空间并找到可能性最高的匹配来识别它们 。 本质上[8] 是把未知物体的推理简化成了搜索任务 。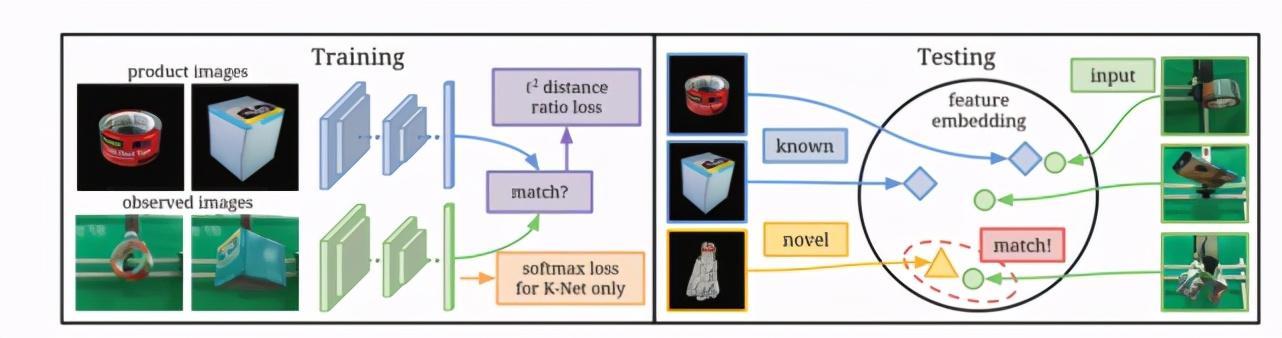 文章插图
文章插图
未知物体的识别框架(图源:Zeng, A., Song, S., Yu, K.-T., Donlon, E., Hogan, F. R., Bauza, M., Ma, D., Taylor, O., Liu, M., Romo, E., Fazeli, N., Alet, F., Chavan Dafle, N., Holladay, R., Morona, I., Nair, P. Q., Green, D., Taylor, I., Liu, W., … Rodriguez, A. (2019). Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. The International Journal of Robotics Research.)
[9] 和 [6] 有一定相似度 , 但 [9] 中的 CNN 是为了构建知识图谱然后用 MLN 进行学习而服务的 。 其提出的模型如下图所示 , 在学习阶段(紫色方框)根据已经给出的一系列物体属性、抓握功能 以及依次创造出的规则(rules) , 作者使用 MLN 来学习物品的属性、位置和抓握功能之间的语意关系 。 学习完成后得到白色方框内所示例的知识图谱 。 在推理阶段(蓝色方框) , 作者使用预训练卷积神经网络(CNN)从被推理的 RGB 图像中提取被推理物品的属性 , 即形状、纹理、材料、位置等 。 为了从训练好的知识图谱中查询具体的抓握功能 , 作者使用吉布斯抽样(Gibbs sampling) , 在计算量允许的情况下遍历尽可能多的可能性来生成后验样本 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 行业|现在行业内客服托管费用是怎么算的
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?