机器人是怎么知道如何抓握杯子的?( 三 )
作者提出的解决办法是将模型(Demo2Vec)分解为演示编码器(Demonstration encoder)和 affordance 预测器(affordance prediction) , 演示编码器负责将演示视频通过「演示嵌入」(demonstration embedding) 总结为了人类动作和被推理物体外观的低维向量 , 这里的需要解决的问题主要是如何提取关于人与物体交互的有用视觉提示 , 如前文提到的 , 这种交互在视频中比较稀疏 (「sparse」) ,且存在许多其他无关物体 。 作者提出用卷积 LSTM 网络(ConvLSTM)和 soft-attention 来组成演示编码器 。 卷积 LSTM 网络使用两组信息作为输入 , 一组是视频帧 , 即正常的 RGB 图像 , 另一组则是当前的视频帧和前一帧的差值(?x_t = x_t -x_)用以捕捉两帧之间的动态变化, 从而捕捉手部动作的变化讯息 。
接下来 , 卷积 LSTM 网络的两组输出(RGB 特征和动态特征)将会被输入到 soft attention 模块中 , 最终得到的注意力权重会与 RGB 特征相乘 , 并对所有帧求和 , 从而生成 demonstration embedding 。 利用 demonstration embedding , affordance 预测器 (predictor)将知识转移到目标图像上预测被推理物体的交互区域和动作标签 。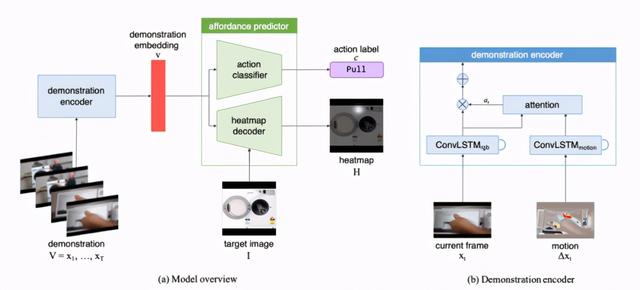 文章插图
文章插图
(a)模型概述 。 Demo2Vec 模型由一个演示编码器和一个 affordance 预测器组成 。 (b)演示编码器 。 演示编码器将输入的演示视频嵌入到低维向量 , 输入图像包括 RGB 图像和 运动图像 (motion modality) , 然后用 soft attention 将两部分信息融合起来 。 affordance 预测器然后利用嵌入向量来预测目标图像中展示的物体的 affordance 和热力图(heat map) 。 (图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
训练后的模型在面对同一个演示视频的不同时段 , 根据演示者的不同操作会对同一个物体推理出不同的 affordance 。 在下图给出的例子中 , 演示者在制作奶昔 , 并依次涉及到了四个 affordance:拿住(hold)、拿起(pick up)、推(push)、拿起(pick up) 。 该视频被分为 4 个短片(由不同颜色表示) , 模型能够正确的根据演示理解 affordance 并且识别每个 affordance 对应的部位 。 这和人类的表现更相似 , 能够让机器人更自然一些 。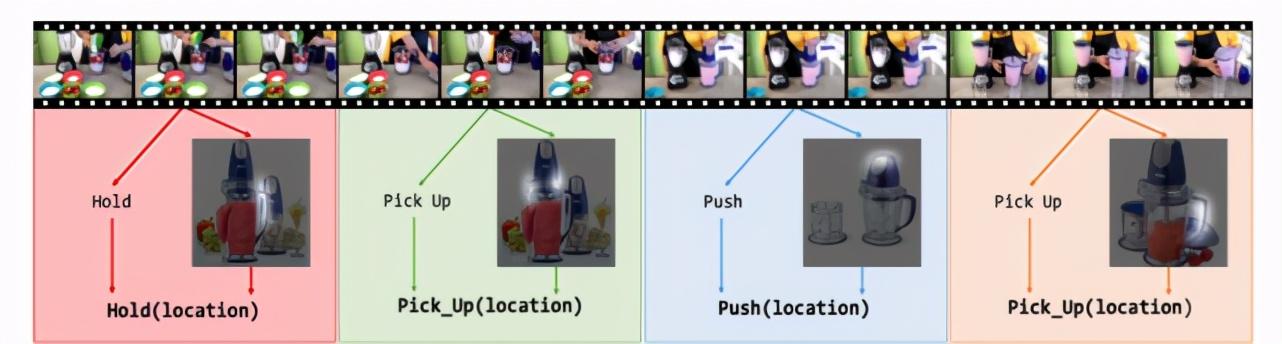 文章插图
文章插图
不同的演示可以令模型对同一物体推理出不同的 affordance(图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
但是 , 不可避免地 , 当演示视频中出现许多杂物或其他和被推理物体十分相似的物体时 , 模型很容易受到误导 。 如下图所示 , 演示人站在摄像机前占据了大部分画面 , 并且遮挡了被推理物体 , 此时模型错误的将物体的 Affordance 预测为 Hold(如图中红色方框所示) ,而实际上应该是 Rotate(如图中绿色方框所示) 。 文章插图
文章插图
当演示人遮挡了被推理物体时推理结果会出错(图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
此外 , 每次对物体的 affordance 进行判断时 , 演示视频是必不可少的 。 而人类只需要对演示视频观看几次就能够直接对未知物体进行推理 。 从这一点看利用模拟(simulation)的 [3] 的泛化能力要更好一点 。 但利用视觉线索仍然是最接近人类推理 Affordance 的方法之一 。 算力方面 , 根据模型的不同——比如 [5] 直接用 RGB-D 图像 3D 建模——有可能对计算能力有很高的要求 。
通过构建知识图谱(knowledge graph)
可以看出 , 利用视觉信息 + CNN 的方法主要是试图模拟人类学习 Affordance 的过程 , 但是由于 CNN 是黑箱模型 , 训练出来的模型可解释性差 。 除此之外 , 绝大多数训练好的 CNN 本质上仍是一个分类器 , 因而其能够推理的 Affordance 也局限于训练数据所包含的 Affordance 。 使用构建知识库的方法则不一样 , 由于物品的各项特征都被单独标记了出来用于最后的推理 , 模型在可解释性方面更有优势 , 使用基于知识的表示形式便于对学习范围进行扩展 。 如果利用知识图谱对水杯的 Affordance 进行学习 , 得到的规则可能是「有柄的物体可以被抓握 , 有开口并且有底的物体可以容纳」 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 行业|现在行业内客服托管费用是怎么算的
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?