机器人是怎么知道如何抓握杯子的?( 四 )
[6] 利用图像和其他元数据源中获取物品的各种信息 , 然后使用马尔可夫逻辑网络(MLN)学习知识图谱 。 在对未知物品进行推理时只依赖于已习得的知识库而无需训练单独的分类器 , 包括 zero-shot affordance prediction 。
作者通过从图像以及诸如 Amazon 和 eBay 之类的在线文本源中提取信息来抽取物品的属性和 Affordance ,然后从中学习知识图谱 。 每一个物品都有三类属性:视觉属性(Visual attributes)、物理属性(Physical attributes)和分类属性(Categorical attributes) 。 视觉属性对应于从视觉感知中获得的信息 , 包括物品的形状和材质等;物理属性包括物体的重量和大小;分类属性则反映物体所属于的更抽象的类别 , 比如动物、机器、器械、电器等等 。
相应地 , 每个物品也有三类标签:Affordance 标签、人体姿势(Human poses)和人与物品的相对位置(Human-object relative locations) 。 后两者分别用于描述人体的姿势和人与物品交互过程中人与物体之间的空间关系 。
在数据收集好之后 , 就可以利用马尔可夫逻辑网络(MLN)从中学习关系即通用规则的权重来构建知识图谱 。 下图可视化了作者所构建的知识图谱的一部分 。 在下图中 , 每个节点包含了某一类属性或标签 , 连接两个节点的线段则代表两个节点之间的逻辑公式——比如既是 vehicle 又是 animal , MLN 需要学习相应的权重 , 其中正权重表示两者可能同时出现 , 由绿色实线表示 , 负权重表示两者是负相关的 , 由红色虚线表示 。 在本例中 vehicle 和 animal 是由红色虚线连接的 , 即两者不大可能出现在同一物体上 。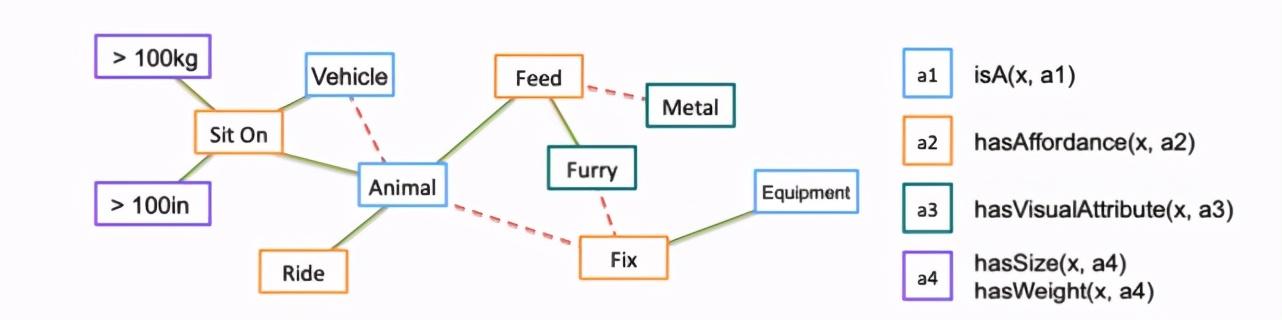 文章插图
文章插图
构造的 KB 的图形化显示 。(图源:Zhu, Y., Fathi, A., & Fei-Fei, L. (2014). Reasoning about Object Affordances in a Knowledge Base Representation. ECCV.)
在执行推理时 , 模型首先根据提供的图像抽取物体的视觉属性 , 然后推测其物理和分类属性 。 利用这些属性模型可以在习得的知识图谱中对物体的 Affordance 进行查询 。 下图给出了 zero-shot affordance prediction 的例子 。 文章插图
文章插图
zero shot affordance prediction 的推理过程 。 给定一个未知对象的图像 , 模型通过 hierarchical model 估算对象属性 。 这些属性可作为知识图谱查询的线索 , 从而对 Affordance 进行预测 , 并估计人体姿势和人体的相对位置 。 (图源:Zhu, Y., Fathi, A., & Fei-Fei, L. (2014). Reasoning about Object Affordances in a Knowledge Base Representation. ECCV.)
由于推理是运用多个线索综合完成的 , 模型的稳健性较好 , 不容易出现缺少某一个属性的信息就推理失败的情况 。 灵活性也好 , 可以比较容易的对模型进行扩展 。 不便之处则在于模型的质量很大程度上依靠于知识图谱的质量 , 而后者又依靠于数据集的质量 。 如果数据集中有很强的偏置(bias) , 比如红色的物体刚好都可以被抓握 , 所生成的模型表现也会受到影响 。
当然 , 许多研究会将上述的方法混合起来 , 比如 [9] 和 [10] 就使用了 CNN 抽取特征用于构建知识图谱 。
抓握(grasping)
抓握(grasping)是人类生活最常用到的动作之一 , 而机器人的任务就是根据已经学习过的物体推断未知物体的 grasping affordance , 即一个物体是否能被抓握 。 抓握和推理任务在一定程度上有重合 。 在机器人领域内 , 有很多研究会将推断物体是否能被抓握和识别物体具体能够被抓握的位置放在一个学习任务中 。 另一方面 , 抓握也可以分为学习 simple-task affordance 和 task-specific affordance 。 本文的重点会更偏向于推理未知物体能否被抓握 , 借用 zero-shot learning 的概念——在上文中的知识图谱中也有简要提到——这一领域也被叫做 zero-shot (grasp) affordance 。 这也算是推理抓握功能的难点之一 , 其他难点还包括实时推理、数据收集等 。
早期的一些研究会利用本地特征抽取器(local feature extractors )来学习一个物体是否能被抓握 , 如 [7] 。 虽然随着深度学习的流行手工设计的特征已经不再吃香 , 这篇文章还是在一定程度上解决了如何面对未知物体的问题:只寻找物体上是否有具有已知能够抓握的部位 。 [8] 则使用了神经网络来判断一个物体可能的 Affordance , 包括正面吸取(suction down)、侧面吸取(suction side)、抓握(grasp down)和齐平抓握(flush grasp) 。 四种 Affordance 如下图所示 , 抓握和齐平抓握的区别主要是后者具有在目标对象和墙壁之间滑动一根手指的附加行为 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 行业|现在行业内客服托管费用是怎么算的
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?