一文带你了解基于视觉的机器人抓取自学习
作者:夏初
来源:公众号@计算机视觉工坊
“一眼就能学会动作” , 或许对人而言 , 这样的要求有点过高 , 然而 , 在机器人的身上 , 这个想法正在逐步实现中 。 马斯克(Elon Musk)创立的人工智能公司Open AI研究通过One-Shot Imitation Learning算法(一眼模仿学习) , 让机器人能够复制人类行为 。 现阶段理想化的目标是人类教机器人一个任务 , 经过人类演示一次后 , 机器人可以自学完成指定任务 。 机器人学习的过程 , 与人类的学习具有相通之处 , 但是需要机器人能够理解任务的动作方式和动作意图 , 并且将其转化为机器人自身的控制运动上 。
“机器人学习”是机器人研究的重要方向 , 其中包含了计算机视觉 , 自然语言处理 , 机器人控制等众多技术 。 机器人抓取(Robotic manipulation/grasping)是机器人智能化发展道路上亟待解决的问题之一 。 相较于传统的开环控制系统 , 本文将从基于视觉 , 基于视觉和语音 , 基于视觉和触觉三个方向出发 , 介绍机器人抓取的相关研究进展 , 并罗列相关的文章供大家查找阅读 。
1、基于视觉信息的机器人抓取学习
Google AI Blog: Grasp2Vec: Learning Object Representations from Self-Supervised Grasping
【论文原文摘要】结构良好的视觉表示可以使机器人学习更快 , 并且可以提高通用性 。 在本文中 , 研究人员研究了在没有人工标记的情况下 , 如何通过使用自主的机器人与环境的交互获得有效的以物体为中心的表示方法 , 即可完成机器人操作任务 。 这种机器人学习的方法可以让机器人收集获取更多的经验 , 不断完善机器人的认知 , 从而无需人工干预即可有效地进行缩放 。 本文中的学习方法是基于对象的永久性:当机器人从场景中删除对象时 , 该场景的表示会根据被删除对象的特征而随之变化 。 研究人员根据观察结果会在特征向量之间建立关系 , 并使用它来学习场景和物体的表示 。 这些场景和物体可用于识别对象实例 , 将它们在场景中进行定位 , 并在机器人从目标箱中检索命令对象时 , 执行以目标为导向的任务 。 整体的抓取过程是通过记录场景图像 , 抓取和移除物体以及记录结果 , 该抓取过程也可以用于为文中的方法自动收集训练数据 。 文中实验表明 , 这种用于任务抓取的自我监督方法明显优于直接增强图像学习方法和先前的表征学习方法 。
从小时候开始 , 即使从未有人明确地教过如何做 , 人们依旧能够识别并收拾取自己喜欢的物品 。 根据认知发展研究 , 这种与世界中的物体相互交互的能力 , 在人类感知和操纵物体的能力形成的过程中起着重要的作用 。 通过与周围世界的互动 , 人们可以通过自我监督来学习:知道自己采取了什么行动 , 并且从结果中学到了什么知识 。 在机器人技术中 , 人们积极研究了这种自我监督型学习 , 因为它使机器人系统无需大量的训练数据或人工监督即可进行学习 。
受对象永久性概念的启发 , 研究人员提出了Grasp2Vec , 一种用于获取物体表示的简单而高效的算法 。 Grasp2Vec算法中尝试抓取任何东西都会获取以下几条信息——如果机器人抓住一个物体并将其抬起 , 则物体必须在抓取前进入场景 。 此外 , 若机器人知道它抓住的物体当前处于夹爪中 , 就会将其从场景中移除 。 通过使用这种形式的自监督 , 机器人可以利用抓取前后的场景视觉变化来学习识别物体 。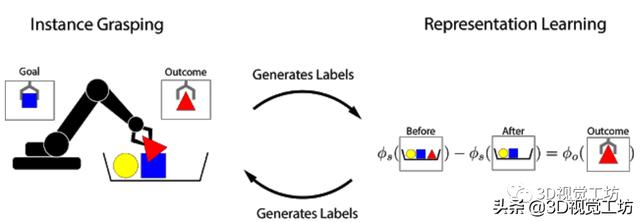 文章插图
文章插图
基于前与X Robotics合作的基础上(该项目的任务是让一系列机器人同时学习使用单目相机输入来抓取家用物品) , 研究人员使用机械臂“无意间”抓取物体 , 这种经验使机器人能够学习丰富的图像对象 。 这些表示可用于获取“有意抓握”的能力 , 并且机械臂可以拾取用户指定的对象 。
在强化学习的框架中 , 通过“奖励函数”可以衡量任务的成功与否 。 通过最大化奖励函数 , 机器人可以从头开始自学各种抓握的技能 。 如果任务的成功与否可以通过简单的方法来衡量 , 设计奖励函数就很容易 。 一个简单的例子是当一个按钮被按下时 , 该按钮直接向机器人提供奖励 。
然而 , 当成功标准取决于对当前任务的“感性理解”时 , 设计奖励函数的难度就会加大 。 考虑实例抓取的任务 , 其中机器人看到的是期望的物体图片 。 当机器人试图抓住该物体后 , 将会检查抓取的对象 。 此任务的奖励函数可以看作物体识别问题:抓住的物体是否与期望相匹配?
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 双行合一|关于Word我们要了解的知识(12)
- S7|vivo S7的6400万有多强?带你感受“神奇动物在哪里”
- 模式|刚了解到无货源电商模式,淘宝好还是抖音小店好?
- 微信|微信转账点收款就能收到钱了?这个“秘密”要了解,很多人上当了
- 工地|“智慧工地”是什么?记者带你全方位了解
- 这些错误,程序员经常会犯,你了解过吗?
- 现场|逛展看未来丨展会现场还能这么玩?带你解锁萌娃的逛展“姿势”
- 快速概览 + 详细了解N:N聚类算法是如何应用的
- 微服务如何保证不会出现连锁反应?Go 实现的断路器了解下